LangChain v1.0学习笔记(1)
本文为在官网学习 LangChain v1.0 文档的笔记,帮助大家在网络不畅,或者官网阅读困难的情况下学习 LangChain v1.0。
本文为在官网学习 LangChain v1.0 文档的笔记,帮助大家在网络不畅,或者官网阅读困难的情况下学习 LangChain v1.0。
LangChain v1.0 官方文档:LangChain-Docs
一、LangChain概述
🔈LangChain v1.0 现已推出!
有关如何升级代码的完整更改列表和说明,请参阅官网发行说明和迁移指南。如果您遇到任何问题或有反馈,可以去官网社区提出问题。
LangChain 是开始构建由 LLM 提供支持的代理和应用程序的最简单方法。只需不到 10 行代码,您就可以连接到 OpenAI、Anthropic、Google 等。LangChain 提供预构建的代理架构和模型集成,帮助您快速入门,并将 LLM 无缝集成到您的代理和应用程序中。
如果您想快速构建代理和自治应用程序,我们建议您使用 LangChain。当您有更高级的需求,需要结合确定性和代理工作流程、大量自定义和仔细控制的延迟时,请使用 LangGraph,我们的低级代理编排框架和运行时。
LangChain 代理构建在 LangGraph 之上,以提供持久的执行、流、人机交互、持久性等。您无需了解 LangGraph 即可使用基本的 LangChain 代理。
# pip安装(需要Python 3.10或更高版本)
pip install -U langchain
# uv安装
uv add langchain(需要Python 3.10或更高版本)
1.1 创建Agent
# 使用pip install -qU "langchain[anthropic]"来调用该模型
from langchain.agents import create_agent
def get_weather(city: str) -> str:
"""获取指定城市的天气。"""
return f"{city}这边是晴朗的!"
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[get_weather],
system_prompt="你是一个乐于助人的助手",
)
# 运行代理程序
agent.invoke(
{"messages": [{"role": "user", "content": "北京的天气怎么样"}]}
)
1.2 核心优势
二、LangChain v1.0
-
V1中新增的功能:

-
升级指令:
# pip升级 pip install -U langchain # uv升级 uv add langchain
2.1 新增功能(1)—— create_agent
create_agent 是在 LangChain 1.0 中构建代理的标准方法。它提供了比langgraph.prebuilt.create_react_agent更简单的界面,同时通过使用中间件提供了更大的定制潜力。
from langchain.agents import create_agent
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[search_web, analyze_data, send_email],
system_prompt="你是一个乐于助人的研究助手。"
)
result = agent.invoke({
"messages":[
{"role":"user", "content":"研究人工智能安全趋势"
]
})
在后台,create_agent 建立在基本的代理循环之上——调用一个模型,让它选择要执行的工具,然后在它不再调用工具时完成: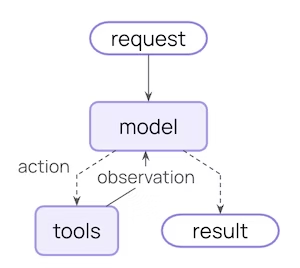
2.1.1 中间件(Middleware)
- 中间件(Middleware)是 create_agent 的定义特征。它提供了一个高度可定制的入口点,提高了您可以构建的内容的上限。
- 优秀的代理需要上下文工程:在正确的时间为模型提供正确的信息。中间件通过可组合抽象帮助您控制动态提示、对话摘要、选择性工具访问、状态管理和护栏。
(1)预构建中间件(Prebuilt middleware)
LangChain 为常见模式提供了一些预构建中间件(Prebuilt middleware),包括:
- PIIMiddleware:在发送到模型之前编辑敏感信息
- SummarizationMiddleware:在对话历史过长时压缩对话历史记录
- HumanInTheLoopMiddleware:敏感工具调用需要批准
from langchain.agents import create_agent
from langchain.agents.middleware import (
PIIMiddleware,
SummarizationMiddleware,
HumanInTheLoopMiddleware
)
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[read_email, send_email],
middleware=[
PIIMiddleware("email", strategy="redact", apply_to_input=True),
PIIMiddleware(
"phone_number",
detector=(
r"(?:\+?\d{1,3}[\s.-]?)?"
r"(?:\(?\d{2,4}\)?[\s.-]?)?"
r"\d{3,4}[\s.-]?\d{4}"
),
strategy="block"
),
SummarizationMiddleware(
model="claude-sonnet-4-5-20250929",
max_tokens_before_summary=500
),
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
}
}
),
]
)
(2)自定义中间件(Custom middleware)
您还可以构建自定义中间件(Custom middleware)以满足您的需求。中间件在代理执行的每个步骤中公开钩子: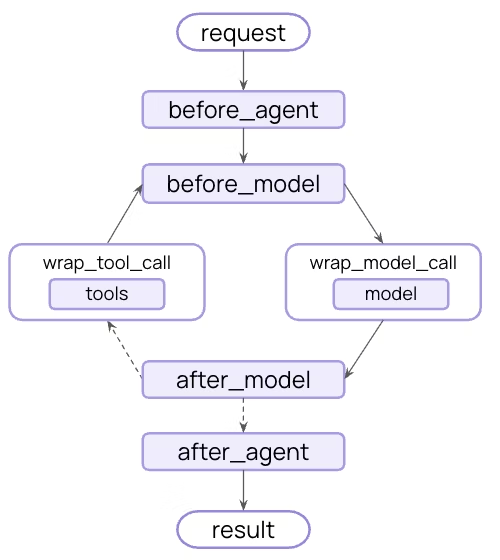
通过在 AgentMiddleware 类的子类上实现以下任何钩子来构建自定义中间件:
| 钩子 | 运行时 | 功能 |
|---|---|---|
| before_agent | 运行agent之前 | 加载内存,验证输入 |
| before_model | 每次 LLM 调用之前 | 更新提示,修剪消息 |
| wrap_model_call | 围绕每个 LLM 调用 | 拦截和修改请求/响应 |
| wrap_tool_call | 围绕每个工具调用 | 拦截和修改工具执行 |
| after_model | 在每次 LLM 响应后 | 验证输出,应用护栏 |
| after_agent | 代理完成后 | 保存结果、清理 |
自定义中间件示例:
from dataclasses import dataclass
from typing import Callable
from langchain_openai import ChatOpenAI
from langchain.agents.middleware import (
AgentMiddleware,
ModelRequest
)
from langchain.agents.middleware.types import ModelResponse
@dataclass
class Context:
user_expertise: str = "beginner"
class ExpertiseBasedToolMiddleware(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
user_level = request.runtime.context.user_expertise
if user_level == "expert":
# More powerful model
model = ChatOpenAI(model="gpt-5")
tools = [advanced_search, data_analysis]
else:
# Less powerful model
model = ChatOpenAI(model="gpt-5-nano")
tools = [simple_search, basic_calculator]
request.model = model
request.tools = tools
return handler(request)
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[
simple_search,
advanced_search,
basic_calculator,
data_analysis
],
middleware=[ExpertiseBasedToolMiddleware()],
context_schema=Context
)
2.2 基于 LangGraph 构建
由于create_agent基于 LangGraph 构建,因此您可以通过以下方式自动获得对长期运行且可靠的代理的内置支持: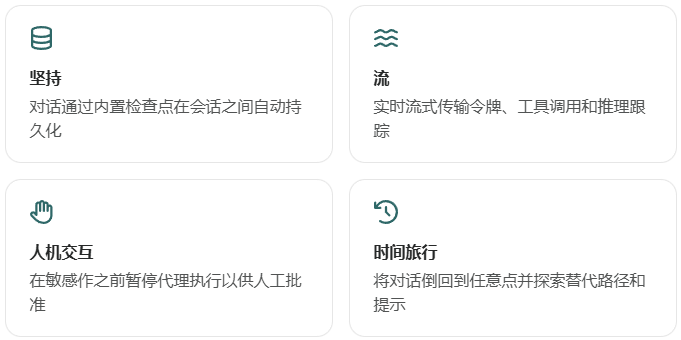
无需学习 LangGraph 即可使用这些功能 - 它们开箱即用。
2.3 结构化输出
create_agent 改进了结构化输出生成:
- 主循环集成:结构化输出现在在主循环中生成,而不需要额外的 LLM 调用
- 结构化输出策略:模型可以在调用工具或使用提供者端结构化输出生成之间进行选择
- 降低成本:消除额外 LLM 调用带来的额外费用
from langchain.agents import create_agent
from langchain.agents.structured_output import ToolStrategy
from pydantic import BaseModel
class Weather(BaseModel):
temperature: float
condition: str
def weather_tool(city: str) -> str:
"""Get the weather for a city."""
return f"it's sunny and 70 degrees in {city}"
agent = create_agent(
"gpt-4o-mini",
tools=[weather_tool],
response_format=ToolStrategy(Weather)
)
result = agent.invoke({
"messages": [{"role": "user", "content": "What's the weather in SF?"}]
})
print(repr(result["structured_response"]))
# results in `Weather(temperature=70.0, condition='sunny')`
错误处理:通过参数控制错误处理:handle_errorsToolStrategy
- 解析错误:模型生成的数据与所需结构不匹配
- 多个工具调用:模型为结构化输出模式生成 2+ 个工具调用
❗内容块支持目前仅适用于以下集成:
langchain-anthropic
langchain-aws
langchain-openai
langchain-google-genai
langchain-ollama
对内容块的更广泛支持将逐步在更多提供商中推出。
新的 content_blocks 属性引入了跨提供程序工作的消息内容的标准表示形式:
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-sonnet-4-5-20250929")
response = model.invoke("What's the capital of France?")
# Unified access to content blocks
for block in response.content_blocks:
if block["type"] == "reasoning":
print(f"Model reasoning: {block['reasoning']}")
elif block["type"] == "text":
print(f"Response: {block['text']}")
elif block["type"] == "tool_call":
print(f"Tool call: {block['name']}({block['args']})")
好处:
- 与提供商无关:使用同一 API 访问推理跟踪、引文、内置工具(网络搜索、代码解释器等)和其他功能,无论提供商如何
- 类型安全:所有内容块类型的完整类型提示
- 向后兼容:标准内容可以延迟加载,因此没有关联的重大更改
有关更多信息,可以参阅内容块指南。
2.4 简化包
LangChain v1 简化了 langchain 包命名空间,以专注于代理的基本构建块。细化的命名空间公开了最有用和最相关的功能:
Namespace:
| 模块 | 可用内容 | 笔记 |
|---|---|---|
| langchain.agents | create_agent,AgentState | 核心代理创建功能 |
| langchain.messages | 邮件类型、内容块trim_messages | 从 @[langchain-core] |
| langchain.tools | @tool、BaseTool、注射辅助工具 | 从 @[langchain-core] |
| langchain.chat_models | init_chat_model、BaseChatModel | 统一模型初始化 |
| langchain.embeddings | 嵌入,init_embeddings | 嵌入模型 |
为了方便起见,其中大部分都是从中重新导出的,这提供了构建代理的集中 API 表面。
langchain-core
# Agent building
from langchain.agents import create_agent
# Messages and content
from langchain.messages import AIMessage, HumanMessage
# Tools
from langchain.tools import tool
# Model initialization
from langchain.chat_models import init_chat_model
from langchain.embeddings import init_embeddings
langchain-classic
遗留功能已转移到 langchain-classic,以保持核心包的精简和专注。
langchain-classic 中有什么:
- 遗留链和链实现
- 检索器(例如或上一个模块中的任何内容)MultiQueryRetrieverlangchain.retrievers
- 索引 API
- 中心模块(用于以编程方式管理提示)
- langchain-community 导出
- 其他已弃用的功能
安装 langchain-classic:
# pip安装
pip install langchain-classic
# uv安装
uv add langchain-classic
然后更新导入:
from langchain import ...
from langchain_classic import ...
from langchain.chains import ...
from langchain_classic.chains import ...
from langchain.retrievers import ...
from langchain_classic.retrievers import ...
from langchain import hub
from langchain_classic import hub
三、LangChain v1 迁移指南
下面这部分指南主要概述了 LangChain v1 与之前版本之间的主要变更。
3.1 简化包结构
LangChain v1 大幅精简了 langchain 包的命名空间,聚焦于智能体(agent)的核心构建模块。精简后的包更便于开发者发现和使用核心功能。
3.1.1 命名空间:
| 模块 | 可用内容 | 说明 |
|---|---|---|
langchain.agents |
create_agent、AgentState |
核心智能体创建功能 |
langchain.messages |
消息类型、内容块、trim_messages |
从 langchain-core 重导出 |
langchain.tools |
@tool、BaseTool、注入辅助工具 |
从 langchain-core 重导出 |
langchain.chat_models |
init_chat_model、BaseChatModel |
统一模型初始化 |
langchain.embeddings |
init_embeddings、Embeddings |
嵌入模型相关 |
3.1.2 langchain-classic 包
如果你的代码中使用了 langchain 包中的以下内容,需要安装 langchain-classic 并更新导入语句:
- 旧版链(
LLMChain、ConversationChain等) - 检索器(例如
MultiQueryRetriever或原langchain.retrievers模块中的任何内容) - 索引 API
- Hub 模块(用于程序化管理提示词)
- 嵌入模块(例如
CacheBackedEmbeddings和社区嵌入模型) langchain-community重导出的内容- 其他已废弃功能
导入示例(v1 新写法 vs v0 旧写法)
# v1新写法
# 链(Chains)
from langchain_classic.chains import LLMChain
# 检索器(Retrievers)
from langchain_classic.retrievers import ...
# 索引(Indexing)
from langchain_classic.indexes import ...
# Hub
from langchain_classic import hub
# v0旧写法
# 链(Chains)
from langchain.chains import LLMChain
# 检索器(Retrievers)
from langchain.retrievers import ...
# 索引(Indexing)
from langchain.indexes import ...
# Hub
from langchain import hub
安装命令:
- pip 安装:
pip install langchain-classic - uv 安装:
uv pip install langchain-classic
3.2 迁移至 create_agent
在 v1.0 之前,推荐使用 langgraph.prebuilt.create_react_agent 构建智能体。现在,建议使用 langchain.agents.create_agent 构建智能体。
以下表格概述了从 create_react_agent 到 create_agent 的功能变更:
| 模块 | 核心变更说明 |
|---|---|
| 导入路径 | 包从 langgraph.prebuilt 迁移至 langchain.agents |
| 提示词 | 参数重命名为 system_prompt,动态提示词通过中间件实现 |
| 模型前钩子 | 替换为带有 before_model 方法的中间件 |
| 模型后钩子 | 替换为带有 after_model 方法的中间件 |
| 自定义状态 | 仅支持 TypedDict,可通过 state_schema 或中间件定义 |
| 模型 | 支持通过中间件动态选择,不支持预绑定模型 |
| 工具 | 工具错误处理迁移至带有 wrap_tool_call 方法的中间件 |
| 结构化输出 | 移除提示词驱动的输出,改用 ToolStrategy/ProviderStrategy |
| 流式节点名称 | 节点名称从 "agent" 改为 "model" |
| 运行时上下文 | 通过 context 参数依赖注入,替代 config["configurable"] |
| 命名空间 | 精简为聚焦智能体构建模块,旧版代码迁移至 langchain-classic |
3.2.1 导入路径
智能体预构建函数的导入路径从 langgraph.prebuilt 迁移至 langchain.agents,函数名从 create_react_agent 改为 create_agent:
# v0(旧)
from langgraph.prebuilt import create_react_agent
# v1(新)
from langchain.agents import create_agent
3.2.2 提示词
(1)静态提示词重命名
prompt 参数已重命名为 system_prompt:
v1(新)
from langchain.agents import create_agent
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[check_weather],
system_prompt="你是一个有帮助的助手"
)
v0(旧)
# 旧版使用 prompt 参数的写法(不再支持)
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(
model="claude-sonnet-4-5-20250929",
tools=[check_weather],
prompt="你是一个有帮助的助手"
)
(2)SystemMessage 转字符串
如果在系统提示词中使用 SystemMessage 对象,需提取其字符串内容:
v1(新)
from langchain.agents import create_agent
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[check_weather],
system_prompt="你是一个有帮助的助手"
)
v0(旧)
# 旧版使用 SystemMessage 的写法(不再支持)
from langgraph.prebuilt import create_react_agent
from langchain.schema import SystemMessage
agent = create_react_agent(
model="claude-sonnet-4-5-20250929",
tools=[check_weather],
prompt=SystemMessage(content="你是一个有帮助的助手")
)
(3)动态提示词
动态提示词是核心的上下文工程模式,可根据当前对话状态调整模型的提示内容。通过 @dynamic_prompt 装饰器实现:
v1(新)
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
from langgraph.runtime import Runtime
@dataclass
class Context:
user_role: str = "user"
@dynamic_prompt
def dynamic_prompt(request: ModelRequest) -> str:
user_role = request.runtime.context.user_role
base_prompt = "你是一个有帮助的助手。"
if user_role == "expert":
prompt = (
f"{base_prompt} 提供详细的技术回复。"
)
elif user_role == "beginner":
prompt = (
f"{base_prompt} 用简单的方式解释概念,避免专业术语。"
)
else:
prompt = base_prompt
return prompt
agent = create_agent(
model="gpt-4o",
tools=tools,
middleware=[dynamic_prompt],
context_schema=Context
)
# 带上下文调用
agent.invoke(
{"messages": [{"role": "user", "content": "解释异步编程"}]},
context=Context(user_role="expert")
)
v0(旧)
# 旧版动态提示词实现方式(不再支持)
from langgraph.prebuilt import create_react_agent
def dynamic_prompt(state):
user_role = state["user_role"]
base_prompt = "你是一个有帮助的助手。"
if user_role == "expert":
return f"{base_prompt} 提供详细的技术回复。"
elif user_role == "beginner":
return f"{base_prompt} 用简单的方式解释概念,避免专业术语。"
else:
return base_prompt
agent = create_react_agent(
model="gpt-4o",
tools=tools,
prompt=dynamic_prompt
)
3.2.3 模型前钩子
模型前钩子现在通过带有 before_model 方法的中间件实现。这种新模式更具扩展性,可定义多个中间件在模型调用前运行,实现跨智能体的通用模式复用。
常见用途包括:
- 对话历史总结
- 消息截断
- 输入安全防护(如个人身份信息脱敏)
v1 已内置总结中间件:
v1(新)
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=tools,
middleware=[
SummarizationMiddleware(
model="claude-sonnet-4-5-20250929",
max_tokens_before_summary=1000
)
]
)
v0(旧)
# 旧版模型前钩子实现方式(不再支持)
from langgraph.prebuilt import create_react_agent
def pre_model_hook(state):
# 对话历史总结逻辑
return state
agent = create_react_agent(
model="claude-sonnet-4-5-20250929",
tools=tools,
pre_model_hook=pre_model_hook
)
3.2.4 模型后钩子
模型后钩子现在通过带有 after_model 方法的中间件实现。这种新模式更具扩展性,可定义多个中间件在模型调用后运行,实现跨智能体的通用模式复用。
常见用途包括:
- 人工介入审核
- 输出安全防护
v1 已内置工具调用人工审核中间件:
v1(新)
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[read_email, send_email],
middleware=[HumanInTheLoopMiddleware(
interrupt_on={
"send_email": True,
"description": "发送前请审核此邮件"
},
)]
)
v0(旧)
# 旧版模型后钩子实现方式(不再支持)
from langgraph.prebuilt import create_react_agent
def post_model_hook(state):
# 人工审核逻辑
return state
agent = create_react_agent(
model="claude-sonnet-4-5-20250929",
tools=[read_email, send_email],
post_model_hook=post_model_hook
)
3.2.5 自定义状态
自定义状态可通过额外字段扩展默认智能体状态,支持两种定义方式:
- 通过
create_agent的state_schema参数(适用于工具需访问的状态) - 通过中间件(适用于特定中间件钩子和关联工具管理的状态)
推荐通过中间件定义自定义状态,可使状态扩展与相关中间件和工具在概念上保持关联。state_schema 参数仍支持向后兼容。
(1)通过 state_schema 定义状态
当自定义状态需要被工具访问时,使用 state_schema 参数:
v1(新)
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent, AgentState
# 定义扩展 AgentState 的自定义状态
class CustomState(AgentState):
user_name: str
@tool
def greet(
runtime: ToolRuntime[CustomState]
) -> str:
"""用于向用户问好(包含用户名)"""
user_name = runtime.state.get("user_name", "未知用户")
return f"你好 {user_name}!"
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[greet],
state_schema=CustomState
)
v0(旧)
# 旧版自定义状态实现方式(不再支持)
from langgraph.prebuilt import create_react_agent
from pydantic import BaseModel
class CustomState(BaseModel):
user_name: str = "未知用户"
@tool
def greet(state: CustomState) -> str:
"""用于向用户问好(包含用户名)"""
return f"你好 {state.user_name}!"
agent = create_react_agent(
model="claude-sonnet-4-5-20250929",
tools=[greet],
state_schema=CustomState
)
(2)通过中间件定义状态
中间件可通过设置 state_schema 属性定义自定义状态,使状态扩展与相关中间件和工具在概念上保持关联:
from langchain.agents.middleware import AgentState, AgentMiddleware
from typing_extensions import NotRequired
from typing import Any
class CustomState(AgentState):
model_call_count: NotRequired[int] # 可选字段
class CallCounterMiddleware(AgentMiddleware[CustomState]):
state_schema = CustomState # 绑定自定义状态
def before_model(self, state: CustomState, runtime) -> dict[str, Any] | None:
count = state.get("model_call_count", 0)
if count > 10:
return {"jump_to": "end"} # 超过调用次数则终止
return None
def after_model(self, state: CustomState, runtime) -> dict[str, Any] | None:
# 更新模型调用次数
return {"model_call_count": state.get("model_call_count", 0) + 1}
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[...],
middleware=[CallCounterMiddleware()] # 注册中间件
)
更多关于通过中间件定义自定义状态的细节,参见中间件文档。
(3)状态类型限制
create_agent 仅支持 TypedDict 作为状态模式,不再支持 Pydantic 模型和数据类(dataclass)。
v1(新)
from langchain.agents import AgentState, create_agent
# AgentState 是 TypedDict 类型
class CustomAgentState(AgentState):
user_id: str
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=tools,
state_schema=CustomAgentState
)
v0(旧)
# 旧版支持的 Pydantic 模型/数据类方式(不再支持)
from langgraph.prebuilt import create_react_agent
from pydantic import BaseModel
from dataclasses import dataclass
class CustomState(BaseModel):
user_id: str
# 或
@dataclass
class CustomState:
user_id: str
agent = create_react_agent(
model="claude-sonnet-4-5-20250929",
tools=tools,
state_schema=CustomState
)
只需继承 langchain.agents.AgentState(而非 BaseModel 或使用 dataclass 装饰器)。如需验证逻辑,可在中间件钩子中实现。
3.2.6 模型
动态模型选择支持根据运行时上下文(如任务复杂度、成本约束、用户偏好)选择不同模型。langgraph-prebuilt v0.6 中的 create_react_agent 支持通过 model 参数传入可调用对象实现动态模型和工具选择,该功能在 v1 中已迁移至中间件接口。
(1)动态模型选择
v1(新)
from langchain.agents import create_agent
from langchain.agents.middleware import (
AgentMiddleware, ModelRequest, ModelRequestHandler
)
from langchain.messages import AIMessage
from langchain_openai import ChatOpenAI
basic_model = ChatOpenAI(model="gpt-5-nano") # 基础模型
advanced_model = ChatOpenAI(model="gpt-5") # 高级模型
class DynamicModelMiddleware(AgentMiddleware):
def wrap_model_call(self, request: ModelRequest, handler: ModelRequestHandler) -> AIMessage:
# 根据消息数量选择模型
if len(request.state.messages) > self.messages_threshold:
model = advanced_model
else:
model = basic_model
return handler(request.replace(model=model))
def __init__(self, messages_threshold: int) -> None:
self.messages_threshold = 10 # 消息数量阈值
agent = create_agent(
model=basic_model,
tools=tools,
middleware=[DynamicModelMiddleware(messages_threshold=10)]
)
v0(旧)
# 旧版动态模型选择方式(不再支持)
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
basic_model = ChatOpenAI(model="gpt-5-nano")
advanced_model = ChatOpenAI(model="gpt-5")
def select_model(state):
if len(state["messages"]) > 10:
return advanced_model
else:
return basic_model
agent = create_react_agent(
model=select_model,
tools=tools
)
(2)预绑定模型
为更好地支持结构化输出,create_agent 不再接受带有工具或配置的预绑定模型:
# 不再支持的写法
model_with_tools = ChatOpenAI().bind_tools([some_tool])
agent = create_agent(model_with_tools, tools=[])
# 推荐写法
agent = create_agent("gpt-4o-mini", tools=[some_tool])
如果不使用结构化输出,动态模型函数可返回预绑定模型。
3.2.7 工具
create_agent 的 tools 参数接受以下类型的列表:
- LangChain
BaseTool实例(通过@tool装饰的函数) - 带有正确类型提示和文档字符串的可调用对象(函数)
- 表示内置提供商工具的字典
该参数不再接受 ToolNode 实例。
v1(新)
from langchain.agents import create_agent
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[check_weather, search_web] # 直接传入工具函数/实例
)
v0(旧)
# 旧版支持 ToolNode 的写法(不再支持)
from langgraph.prebuilt import create_react_agent
from langgraph.graph import ToolNode
check_weather_node = ToolNode(check_weather)
search_web_node = ToolNode(search_web)
agent = create_react_agent(
model="claude-sonnet-4-5-20250929",
tools=[check_weather_node, search_web_node]
)
(1)工具错误处理
现在可通过实现 wrap_tool_call 方法的中间件配置工具错误处理:
v1(新)
# 示例即将推出
v0(旧)
# 旧版工具错误处理方式(不再支持)
from langgraph.prebuilt import create_react_agent
def handle_tool_error(error):
return f"工具调用失败:{str(error)}"
agent = create_react_agent(
model="claude-sonnet-4-5-20250929",
tools=[check_weather, search_web],
tool_error_handler=handle_tool_error
)
3.2.8 结构化输出
(1)节点变更
结构化输出不再通过独立于主智能体的节点生成,而是在主循环中生成,降低了成本和延迟。
(2)工具和提供商策略
v1 新增两种结构化输出策略:
ToolStrategy:使用模拟工具调用生成结构化输出ProviderStrategy:使用提供商原生结构化输出生成功能
v1(新)
from langchain.agents import create_agent
from langchain.agents.structured_output import ToolStrategy, ProviderStrategy
from pydantic import BaseModel
class OutputSchema(BaseModel):
summary: str # 总结内容
sentiment: str # 情感倾向
# 使用 ToolStrategy
agent = create_agent(
model="gpt-4o-mini",
tools=tools,
response_format=ToolStrategy(OutputSchema) # 显式指定工具策略
)
v0(旧)
# 旧版结构化输出实现方式(不再支持)
from langgraph.prebuilt import create_react_agent
from pydantic import BaseModel
class OutputSchema(BaseModel):
summary: str
sentiment: str
agent = create_react_agent(
model="gpt-4o-mini",
tools=tools,
structured_output_schema=OutputSchema
)
(3)移除提示词驱动输出
response_format 参数不再支持提示词驱动输出。相比模拟工具调用和提供商原生结构化输出,提示词驱动输出的可靠性较低。
3.2.9 流式节点名称变更
从智能体流式输出事件时,节点名称从 "agent" 改为 "model",更贴合该节点的用途。
3.2.10 运行时上下文
调用智能体时,通常需要传递两种类型的数据:
- 对话过程中动态变化的状态(如消息历史)
- 对话期间不变的静态上下文(如用户元数据)
v1 中,通过为 invoke 和 stream 方法设置 context 参数支持静态上下文。
v1(新)
from dataclasses import dataclass
from langchain.agents import create_agent
@dataclass
class Context:
user_id: str # 用户ID
session_id: str # 会话ID
agent = create_agent(
model=model,
tools=tools,
context_schema=Context # 绑定上下文模式
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "你好"}]},
context=Context(user_id="123", session_id="abc") # 传入静态上下文
)
v0(旧)
# 旧版使用 config["configurable"] 的写法(仍支持向后兼容)
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(
model=model,
tools=tools
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "你好"}]},
config={"configurable": {"user_id": "123", "session_id": "abc"}}
)
旧版 config["configurable"] 模式仍支持向后兼容,但建议新应用或迁移至 v1 的应用使用新的 context 参数。
3.3 标准内容
v1 中,消息新增了与提供商无关的标准内容块。通过 message.content_blocks 可获取跨提供商的一致类型化视图,现有 message.content 字段(用于字符串或提供商原生结构)保持不变。
3.3.1 变更内容
- 消息新增
content_blocks属性,用于标准化内容 - 标准化块结构,详见消息文档
- 可通过
LC_OUTPUT_VERSION=v1环境变量或output_version="v1"参数,将标准块序列化到content中
3.3.2 读取标准化内容
v1(新)
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-5-nano")
response = model.invoke("解释人工智能")
for block in response.content_blocks:
if block["type"] == "reasoning":
print(block.get("reasoning")) # 打印推理过程
elif block["type"] == "text":
print(block.get("text")) # 打印文本内容
v0(旧)
# 旧版读取消息内容的方式(仅支持字符串)
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI(model="gpt-5-nano")
response = model.invoke("解释人工智能")
print(response.content) # 直接打印字符串内容
3.3.3 创建多模态消息
v1(新)
from langchain.messages import HumanMessage
message = HumanMessage(content_blocks=[
{"type": "text", "text": "描述这张图片。"},
{"type": "image", "url": "https://example.com/image.jpg"},
])
res = model.invoke([message])
v0(旧)
# 旧版多模态消息创建方式(依赖提供商特定格式)
from langchain.messages import HumanMessage
message = HumanMessage(content=[
{"type": "text", "text": "描述这张图片。"},
{"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}}
])
res = model.invoke([message])
3.3.4 示例块结构
# 文本块
text_block = {
"type": "text",
"text": "Hello world",
}
# 图片块
image_block = {
"type": "image",
"url": "https://example.com/image.png",
"mime_type": "image/png", # MIME类型
}
更多细节参见官网内容块参考文档。
3.3.5 序列化标准内容
标准内容块默认不会序列化到 content 属性中。如果需要在 content 属性中访问标准内容块(例如向客户端发送消息时),可手动启用序列化:
3.3.6 环境变量方式
export LC_OUTPUT_VERSION=v1
3.3.7 初始化参数方式
model = init_chat_model("gpt-4o-mini", output_version="v1")
3.4 不兼容变更
3.4.1 移除 Python 3.9 支持
所有 LangChain 包现在要求 Python 3.10 或更高版本。Python 3.9 将于 2025 年 10 月停止支持。
3.4.2 更新聊天模型的返回类型
聊天模型调用的返回类型签名已从 BaseMessage 修正为 AIMessage。实现 bind_tools 的自定义聊天模型需更新返回签名:
v1(新)
def bind_tools(
...
) -> Runnable[LanguageModelInput, AIMessage]: # 返回类型为 AIMessage
v0(旧)
def bind_tools(
...
) -> Runnable[LanguageModelInput, BaseMessage]: # 旧返回类型为 BaseMessage
3.4.3 OpenAI Responses API 的默认消息格式
与 Responses API 交互时,langchain-openai 现在默认将响应项存储在消息的 content 中。如需恢复旧行为,可将 LC_OUTPUT_VERSION 环境变量设置为 v0,或在实例化 ChatOpenAI 时指定 output_version="v0":
# 通过 output_version 标志强制使用旧行为
model = ChatOpenAI(model="gpt-4o-mini", output_version="v0")
3.4.4 langchain-anthropic 中的默认 max_tokens
langchain-anthropic 中的 max_tokens 参数现在根据所选模型默认设置为更高的值,而非之前的默认值 1024。如果依赖旧默认值,需显式设置 max_tokens=1024:
from langchain_anthropic import ChatAnthropic
# 显式设置 max_tokens 为 1024(旧默认值)
model = ChatAnthropic(model="claude-3-sonnet-20240229", max_tokens=1024)
3.4.5 旧版代码迁移至 langchain-classic
超出标准接口和智能体核心范围的现有功能已迁移至 langchain-classic 包。详见简化命名空间部分,了解核心 langchain 包中的可用内容及迁移至 langchain-classic 的内容。
3.4.6 移除已废弃的 API
之前已标记为废弃并计划在 1.0 中移除的方法、函数和其他对象已被删除。请查看之前版本的废弃通知,获取替代 API 信息。
3.4.7 Text 属性
消息对象的 .text() 方法已改为属性,需移除括号:
# 属性访问(推荐)
text = response.text
# 已废弃的方法调用(将触发警告)
text = response.text()
现有用法(即 .text())仍可运行,但会触发警告。该方法形式将在 v2 中移除。
3.4.8 AIMessage 移除 example 参数
AIMessage 对象已移除 example 参数。建议迁移至使用 additional_kwargs 传递所需的额外元数据:
v1(新)
from langchain.schema import AIMessage
# 使用 additional_kwargs 传递额外元数据
message = AIMessage(content="这是回复内容", additional_kwargs={"example": True})
v0(旧)
from langchain.schema import AIMessage
# 旧版使用 example 参数的写法(不再支持)
message = AIMessage(content="这是回复内容", example=True)
3.5 次要变更
AIMessageChunk对象新增chunk_position属性,值为'last'时表示流中的最后一个块,便于更清晰地处理流式消息。非最后一个块的chunk_position为None。LanguageModelOutputVar的类型现在指定为AIMessage,而非BaseMessage。- 消息块合并逻辑(
AIMessageChunk.add)已更新,对合并块的最终 ID 采用更复杂的选择策略,优先使用提供商分配的 ID 而非 LangChain 生成的 ID。 - 现在默认使用
utf-8编码打开文件。 - 标准测试现在使用多模态内容块。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)