Agentic RL详解:打造自主学习自主迭代的高性能 Agent
强化学习(Reinforcement Learning,简称 RL)是一类机器学习范式,其核心思想是:智能体(Agent)在环境(Environment)中反复执行动作(Action),通过观察环境状态(State)和获得奖励(Reward)来调整行为策略(Policy),从而在长期运行中最大化累积奖励。状态 (State):智能体所处环境的当前观测,例如屏幕画面、传感器数据、对话上下文等。动作
Agentic RL详解:打造自主学习自主迭代的高性能 Agent
1. 工业级 Agent 开发落地难题:成本和效率难以兼顾
随着大语言模型(LLM, Large Language Models)和智能 Agent 技术的爆炸性发展,越来越多的企业与研究机构开始探讨:如何将 Agent 技术真正落地到工业场景、在商业化环境中稳定运行?然而,在实际工程实践中,一个非常严峻的挑战不断出现:成本与效率难以兼顾。
1.1 强模型+高性能的现实代价
首先,让我们来看“强模型”意味着什么。近年来,诸如DeepSeek、GPT-5、Qwen3等大规模模型在通用能力上表现卓越:语言理解、推理、生成能力非常强,甚至在工具调用、代码生成、数学证明等复杂任务上都有突破。然而,这样的模型在“工业化落地”方面却遇到了两大壁垒:
- 部署成本极高。大模型通常含数十亿到百亿以上参数,运行时不仅需要大规模显存(如DeepSeek-V3.2模型企业级高并发部署至少需要双节点8卡A100服务器),还需要强大的计算集群、低延迟网络、冷却散热设备,整体基础设施成本极高。此外,每次推理都可能产生较高的 API 调用费用或内部计算资源开销。
- 数据隐私与安全难以保障。许多行业(例如金融、医疗、政府)对数据安全和隐私要求极高。使用公开云端 API 服务调用强模型意味着将敏感数据发送至外部服务器,存在数据泄露风险。或者,若将强模型部署在内部私有云环境,则意味着企业需要承担更大的硬件投入与维护成本。
结果是:虽然“强模型容器化、自动调用工具”的构想令人兴奋,但落地执行中往往会因为“成本爆表”或“能力配置过剩”而被迫放弃或大幅简化。
1.2 轻量模型+高效率的工程妥协
另一个常见走向是:为降低成本,企业转而选择体量较小、部署更容易、运行更高效的开源模型。例如模型参数只有数 亿或数十亿级别,显存需求较低、推理延迟较短、硬件门槛亦低得多。这种方案确实在“部署难度”“维护成本”“延迟响应”方面表现更佳,但却伴随一个痛点:能力不足。具体表现包括:
- 对于复杂任务(尤其是工具调用、跨表 SQL 查询、复杂推理链)表现不佳,生成错误或无法稳定完成任务。
- 在少量数据或定制场景下,模型“泛化能力”较弱,需要大量人工提示(prompt engineering)或微调才能达到合理水平。
- 在实际使用中,为了避免错误,往往不得不对模型输出进行人工校验或报警机制,从而复用了人工成本。
因此,“轻量化部署”虽然降低了工程门槛,但在“真正落地”的过程中,经常被“能力瓶颈”所困。
1.3 垂域模型训练 & SFT:仍然存在挑战
为了在成本与效率之间寻找平衡,不少工程团队尝试了两条技术路径:
- 训练垂域专用模型:即从头或在通用基础模型上,使用行业特定数据进行大规模训练(如金融对话、法律检索、医学问答)。虽然能够获得较高的专用能力表现,但这一路径的缺点是非常显著:训练成本高、数据准备繁琐、基础设施需求大、调参复杂、维护升级难。
- SFT(Supervised Fine-Tuning)微调:在通用模型基础上,用监督方式(将输入-输出对提前准备好)对模型进行微调,令其更贴合特定任务(如文本分类、SQL 生成)。相比从头训练,这种方式成本低许多,部署也更快。但实际落地时发现:当任务涉及到调用工具、执行 SQL、进行自我纠错与多轮交互时,SFT 的提升往往不能满足需求——模型虽然微调过,但仍然缺乏“自主学习、自主纠错、动态迭代”的能力。
换句话说,虽然垂域训练与 SFT 能够部分改善轻量模型在定制任务上的表现,但仍然难以同时做到“低成本+高能力+高效率”。工业界亟需寻找一种“低门槛部署、可定制功能、动态能力提升”的技术方案。
详细的 Agentic RL 原理及入门实战教程 加入 赋范空间 免费领取
1.4 最高效率提升Agent性能:Agent 强化学习(Agentic RL)
在此背景下,Agent 强化学习(常称 Agentic RL)应运而生,成为了许多工程团队考虑的重要方向。其核心优势在于:
- 快速提升小尺寸模型的工具调用准确率:通过强化学习方法,模型可通过“生成→执行→反馈”循环,主动提升对工具调用、对话交互、SQL 生成等特定任务的能力。
- 降低训练成本:相比从头训练或大规模 SFT,强化学习方案往往只需少量 rollout 数据和少量训练资源,就能够显著提升模型能力,尤其在定制场景下效果明显。
- 支持模型持续迭代与优化:一旦部署后,还可以继续运行 rollout 数据、反馈、再训练,实现“模型上线后还在变强”——这对于工业级 Agent 尤为关键。
因此,Agentic RL 成为了在“成本低、效率高、能力强”三者中取得平衡的关键技术路径。接下来,我们将更深入介绍其概念、原理以及与传统 SFT 的区别。
2. Agentic RL 概念介绍
2.1 强化学习(Reinforcement Learning)概念介绍
强化学习(Reinforcement Learning,简称 RL)是一类机器学习范式,其核心思想是:智能体(Agent)在环境(Environment)中反复执行动作(Action),通过观察环境状态(State)和获得奖励(Reward)来调整行为策略(Policy),从而在长期运行中最大化累积奖励。其基本要素包括:
- 状态 (State):智能体所处环境的当前观测,例如屏幕画面、传感器数据、对话上下文等。
- 动作 (Action):智能体在当前状态下可选的行为,例如“生成一条 SQL 语句”、“调用工具”、“提出下一轮问题”等。
- 奖励 (Reward):环境给予智能体的反馈信号,用以指示其行为是否有利,例如“生成 SQL 正确”可给 +1 奖励,“出错”给 0 或负奖励。
- 策略 (Policy):智能体依据状态选择动作的机制或函数。
- 价值函数 (Value Function):衡量在当前状态下、遵循某策略时,未来可获得的累积奖励期望。
- 环境转移 (State Transition):智能体执行动作后环境跳转到下一个状态并给出新的奖励。
在对话、生成、Agent 调用工具等任务中,强化学习渐渐被广泛应用,因为它能够学习“一个动作序列导致长期收益”的能力,而不仅仅局限于“一次输出对错”的监督学习。
强化学习的核心:决策—反馈—改进的闭环
flowchart LR
A[Agent 决策者] -- Action a(t) --> B[Environment 环境]
B -- State s(t+1) --> A
B -- Reward r(t+1) --> A
A -- Policy update 改进策略 π --> A
在每个时间步 t,智能体依据状态 s(t) 选动作 a(t),环境返回新状态 s(t+1) 与奖励 r(t+1);智能体据此更新策略 π,让自己在未来获得更高的总收益。整个学习过程并不是“先学完再用”,而是一边行动、一边吃反馈、一边变更好。
2.2 什么是 Agentic RL?
此前我们提到,“Agentic RL”即 Agent 强化学习,是将 RL 方法应用于智能 Agent 系统的特定范式。换句话说,它不仅仅训练一个模型“回答问题”,而是训练一个 Agent “持续行动+自我纠错+迭代提升”的能力。我们可以给出如下定义:
总的来说,Agentic RL 是指:在智能 Agent 系统中,通过 RL 方法让 Agent 不断生成动作(如工具调用、对话交互、SQL 执行)、观察反馈、获得奖励,并基于累积经验优化其策略,以实现 Agent 在定制任务中“自主学习、自主迭代”的能力提升。
2.3 Agentic RL 与 SFT(监督微调)的区别
为了深入理解 Agentic RL 的特点,我们将其与更传统的 SFT(Supervised Fine-Tuning)方式作对比:
| 项目 | SFT (监督微调) | Agentic RL (Agent 强化学习) |
|---|---|---|
| 输入/输出形式 | 大量准备好的输入-输出对,例如“问题→正确 SQL” | 生成动作→执行→观察反馈→获得奖励 |
| 优化目标 | 模型拟合训练集中的答案,对错作为损失函数 | 模型最大化累积奖励,不仅看是否一次正确,更看长期表现 |
| 适用场景 | 生成任务、文本分类、简单交互 | 多轮对话、工具调用、Agent 行为决策、复杂任务链 |
| 能力提升模式 | 静态:模型微调后能力固定 | 动态:模型上线后还可继续 rollout 与再训练,形成闭环 |
| 资源成本 | 相对低但效果提升有限 | 效果显著,但需 rollout 环境、执行反馈、策略优化流程 |
从表格中可以看出,当任务涉及“Agent 行为 + 工具调用 + 多步交互 + 纠错能力”时,传统的 SFT 往往难以取得满意效果。而 Agentic RL 通过“行为-反馈-优化”的闭环,能显著提升 Agent 的性能,尤其是在定制化场景中。而结合我们之前讨论的工业化背景,不难看出Agentic RL 的优势在于:
- 它允许小尺寸模型在低成本部署情况下,通过实时 rollout 与反馈机制逐步提升能力,而不是“一次训练后就固定”。
- 它不仅关注“答案正确”这一静态指标,更关注“行为链是否合理”“工具调用是否有效”“多轮交互是否流畅”,从而训练出真正意义上的 Agent。
- 在部署之后, Agent 还可以继续运行 rollout 、收集数据、再训练,形成「上线 → 使用 → 反馈 → 优化」的持续迭代机制,极大提升工程效率与能力稳定性。
好的,下面是本节 “3. Agentic RL:时下顶尖 Agent 的标配” 的课件内容,按照你要求的二级/三级标题格式、中文标题、通俗且具有技术深度的风格编写,字数不少于 2000 字。请你先查看是否满意,如果有修改意见我也可以随时调整。
3. Agentic RL:时下顶尖 Agent 的标配
3.1 当前顶尖 Agent 的发展趋势
在 2025 年,Agent 技术正迎来快速爆发的阶段。从早年以聊天机器人为主,到如今的“工具调用+多轮决策+主动执行”型 Agent,整个行业的关注点有了明显转移:不仅仅是“能答问题”,而且是“能做决策”“能自主行动”“能持续迭代”。在这种背景下,越来越多的顶尖 Agent 项目将 Agentic 强化学习(Agentic RL)作为技术标配,换言之,若一个 Agent 没有主动学习、自我纠错、持续优化的能力,那么它很难称之为“工业级”、“顶尖”或“领先”。
3.2 Agentic RL 在顶尖 Agent 中的体现
既然说到“标配”,那我们就来看 Agentic RL 在这些顶尖 Agent 系统中具体是如何体现的。通过具体案例,你会发现,它并不是“加几个强化学习训练”那么简单,而是一整套“代理行为-工具调用-反馈循环-线上迭代”机制。
GPT-5-Codex
在 GPT-5-Codex 的说明中,OpenAI 提到其训练流程强调真实编程环境的任务:例如“多文件重构”“运行测试套件”“提交 PR” 等。 也就是说,这款模型并不是仅仅“做一个回答”,而是扮演“编程 Agent”、主动执行“编写代码→运行代码→修正代码→提交代码”这一流程。你将会注意到:
- 它的训练目标是不仅输出一个答案,而是“直到任务完成”并由系统验证(例如测试通过)才算成功。
- 它强调工具调用能力(如 IDE 接口、版本控制 PR、运行时调试)——这正是 Agentic RL 所强调的“代理行为”部分。
- 它具备持续优化机制:在任务执行过程中不断反馈、纠错,从而模型获得迭代提升。
因此,我们可以看到 Agentic RL 在这个系统中的实践:模型是一个“活的代理”,而不是只是“被动回答问题”的聊天机器人。
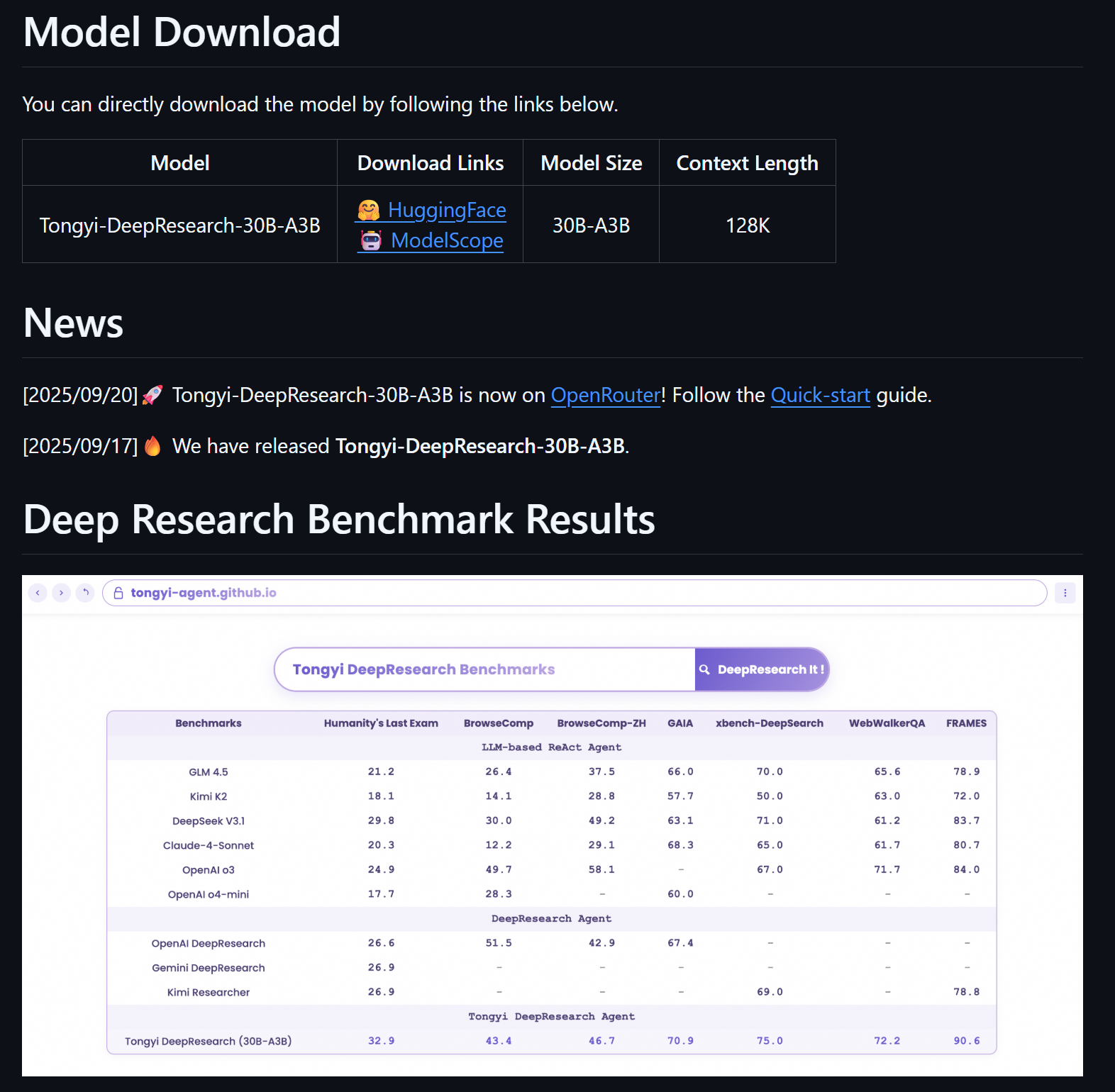
Tongyi DeepResearch
在 Tongyi DeepResearch 的技术报告中,阿里通义明确指出其模型是“特为 Agent 任务训练”的:训练管道包括“ Agentic 持续预训练(agentic continual pre-training)”“冷启动 SFT + on-policy RL 策略” 等。
具体来说,这款模型适配了如下 Agent 特征:
- 长周期、跨任务的“研究型”代理行为:例如检索、浏览、合并多源知识、自动报告生成。
- 工具调用与交互能力:不仅是文本回答,而是访问 Web、检索知识、生成报告。
- Feedback / Reward 驱动的训练机制:训练中不仅做监督微调,还加入了 RL 机制,使模型能基于执行体验优化策略。
从这两个案例来看,顶尖 Agent 系统倾向于将 Agentic RL 作为关键技术路径,使得模型具备“自主行动+持续迭代”的能力,而不仅仅是“静态微调”。这就进一步印证了“Agentic RL 是时代标配”这一说法。
除此之外,如ChatGPT-Agent、Cursor 2.0 Composer等等,也无一不是经过Agentic RL的产品。

3.3 Agentic RL为Agent开发带来的真正影响
接下来我们来看 Agentic RL 解决了传统 Agent 或 LLM 在工业落地时所面临的几个核心瓶颈。
- 部署能力 vs 持续能力
传统 LLM 即便具备强大的通用能力,一启动就被“固定”:你做了监督微调,模型上线,它的能力就是固定的。但工业落地中,能力不是“一次训练就搞定”就足够的。环境变化、工具版本更新、数据分布漂移、用户需求演化都要求 Agent 有“持续优化能力”。而 Agentic RL 恰好提供了这种能力:模型上线后还可以继续采集 rollout 数据、获得反馈、优化策略,从而让 Agent 能力持续提升。
- 工具调用 vs 静态回答
在很多 Agent 场景中,真正难的不是“你问我答”这种静态生成,而是“你让我去做”——例如“调用数据库执行 SQL”、 “访问 Web 检索知识”、 “操作 IDE 生成代码”,这些都属于 Agent 行为。传统 SFT 或简单微调在这方面一般表现有限,因为它无法充分利用“执行结果+反馈”的闭环信息。 Agentic RL 正是为这种“执行-反馈”机制设计,使模型不仅“能答”,而且“能做、做得对”。
- 效率 vs 成本 vs 定制能力
通用大模型强但成本高,小模型便宜但能力弱。那怎样才能在部署门槛低、运维难度小的情况下,仍然让 Agent 具备较强能力?答案就是:使用小模型+强化学习优化其工具调用与任务策略,从而打造“低成本但高能力”的定制 Agent。也就是说, Agentic RL 可被视为“以较低资源获得近顶尖能力”的技术路径。
因此,如果一个 Agent 系统仅用了普通 SFT 或固定微调而没有“执行/反馈/迭代”的机制,那么它往往缺乏“持续进化”和“复杂任务自适应”的能力,很难称为真正工业级、顶尖的 Agent。
4.热门Agentic RL训练框架
4.1 Hugging Face TRL:LLM 强化学习的工业标准
GitHub: https://github.com/huggingface/trl
定位:
Hugging Face TRL(Transformer Reinforcement Learning)是全球最成熟的 LLM RL 开源框架,几乎所有 RLHF 研究与论文(包括 OpenAI DPO、Anthropic HH 模型)都可在 TRL 上复现。其设计目标是将强化学习与 🤗 Transformers 生态无缝结合,为模型提供从 SFT → Reward Model → PPO/DPO 优化的全流程工具链。
核心功能:
TRL 支持 PPO、DPO、KTO、RLOO 等策略优化算法,允许用户基于任何 CausalLM 模型进行强化学习。框架提供 AutoModelForCausalLMWithValueHead 模块,用于在语言模型上附加价值头(Value Head),实现对每个生成序列的回报估计。此外,它内置 RLHF 示例管线,从奖励模型训练到 PPO 微调都可一键执行。
技术特点与用途:
TRL 在研究界被视为“RLHF 基线框架”。它支持高度模块化实验配置,可自由替换奖励模型、参考模型和优化算法。其训练稳定性高、社区活跃度高,非常适合科研实验和企业级 LLM 强化学习任务。
4.2 veRL:字节跳动的生产级强化学习框架
GitHub: https://github.com/volcengine/verl
定位:
veRL(Volcano Engine Reinforcement Learning)是字节跳动火山引擎于 2024 年底开源的分布式大模型强化学习训练框架。其设计目标是将 RLHF 的科研实现转化为可规模化部署的生产级系统。
核心功能:
veRL 的核心模块包括 Rollout 生成器、奖励建模器、策略更新器、分布式调度器。它支持多种算法,如 PPO、DPO、DAPO (Dynamic Alignment Policy Optimization)和 GRPO,并通过异步管线方式加速训练。其架构借鉴了工业级 RL 系统(如 DeepMind Acme、OpenAI RLHF pipeline),可在数百张 GPU 上同时运行。
技术特点与用途:
veRL 面向企业和研究机构的“大规模模型后训练”场景。其分布式框架支持任务并行、异步更新和奖励缓存机制,可显著降低 GPU 闲置率。其 DAPO 算法被广泛用于 Qwen 系列模型中,以优化推理稳定性与语言一致性。
4.3 ART(Agent Reinforcement Trainer):智能体行为优化框架
GitHub: https://github.com/OpenPipe/ART
定位:
ART 是由 OpenPipe 团队在 2025 年推出的开源框架,专门面向 Agent 场景下的强化学习训练。它让语言模型在动态环境中执行任务、收集交互轨迹、基于反馈优化策略,是“从 LLM 到 Agentic RL” 转变的典型代表。
核心功能:
ART 以 POMDP (部分可观测马尔可夫决策过程)为基础建模 Agent 行为,支持 GRPO 与 RLVR 等算法。其训练循环可连接外部工具(如 Web API、文件系统、浏览器模拟器等),让模型学会在真实任务中优化执行策略。
用途与特点:
ART 特别适用于构建“会操作”的 Agent,例如 Web 浏览 Agent、代码调试 Agent 或信息抽取 Agent。与 TRL 不同,ART 关注模型的执行反馈而非文本对齐。其可插拔 environment 接口允许用户轻松定义任务环境,使 Agent 在执行任务时获得奖励信号,从而实现端到端强化学习。
4.4 Microsoft Agent-Lightning:企业级 Agentic RL 平台
GitHub: https://github.com/microsoft/agent-lightning
定位:
Agent-Lightning 是微软在 2025 年推出的多智能体强化学习框架,旨在为企业提供一个统一的 Agent 训练与评估平台。其灵感来自 PyTorch Lightning 的模块化设计,能够在不同 Agent 系统(如 LangChain、AutoGen、Swarm 等)上无缝嵌入 RL 训练机制。
核心功能:
框架核心由 Trainer、Rewarder、Environment 和 Orchestrator 模块构成。支持 PPO、DPO、RLVR 等算法,可在多 Agent 协作任务中共享奖励信号,实现自适应优化。它还内置 MCP 协议(Model Context Protocol)接口,方便连接外部 LLM 服务进行协同训练。
技术特点与用途:
Agent-Lightning 为“多智能体系统的强化学习训练”提供工业级解决方案。它能在任务自动化、AI 编程助理、搜索规划等场景中实现多 Agent 间的动态协作优化,支持自动奖励归因与可视化分析。
详细的 Agent RL 原理及入门实战教程 加入 赋范空间 免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)