从零构建Agentic RAG系统:使用MCP框架打造智能问答助手,看到就是赚到,建议收藏!!
本文详细介绍如何利用模型上下文协议(MCP)构建Agentic RAG系统,通过设置MCP服务器、定义私有数据与实时网络搜索工具、构建完整RAG管道,实现一个能够智能决策信息来源的智能应用。系统可根据查询类型自动选择从矢量数据库或网络获取最佳上下文,为用户提供准确答案。适合开发者学习大模型应用开发。
前言
今天我们将分享使用Agent模式来实现RAG,那就是Agentic RAG。
为了实现这一目标,我们将使用模型上下文协议 (MCP), 这是一个专为创建强大的多工具 AI 代理而设计的现代框架。本文将详细拆解每一个实现的步骤:
-
设置一个完整的 MCP 服务器。
-
为私有数据和实时 Web 搜索定义自定义工具。
-
构建一个完整的 RAG 管道,使代理处于控制之中。
最后,我们将实现一个功能齐全的智能应用程序,能够通过动态获取最佳上下文来处理复杂的查询,以获得真正准确的答案。
目录:
- 模型上下文协议 (MCP) 简介
- MCP 支持的代理 RAG 架构概述
- 设置工作环境
- 设置 MCP 服务器实例
- 定义 MCP 工具
- 构建 RAG 管道
- 将所有内容放在一起并测试系统
一、模型上下文协议(MCP)简介

MCP(即模型上下文协议)是一种开放标准,使大型语言模型 (LLM) 能够安全地访问和利用外部数据、工具和服务。
可以将其视为通用连接器,像用于 AI 的 USB-C,允许不同的 AI 应用程序与各种数据源和功能进行交互。它本质上标准化了人工智能模型如何接收和使用上下文(例如文件、提示或可调用函数)以更有效地执行任务。
- 标准化连接: MCP 为 AI 模型提供了一种与外部系统交互的一致方式,无论AI 模型或底层技术如何。
- 安全访问: MCP 通过定义 AI 模型如何与外部数据和工具交互的明确边界和权限来确保对资源的安全访问。
- 双向沟通: MCP 有助于向 AI 模型(上下文)发送信息和从模型接收结果或作,从而实现动态和交互式 AI 应用程序。
- 工具生态系统: MCP 是由“MCP 服务器”和“MCP 客户端”组成的生态系统,MCP 服务器是通过 MCP 标准公开其功能或数据的应用程序或服务,后者是连接到这些服务器的 AI 应用程序。
二、基于MCP的Agentic RAG 架构概述
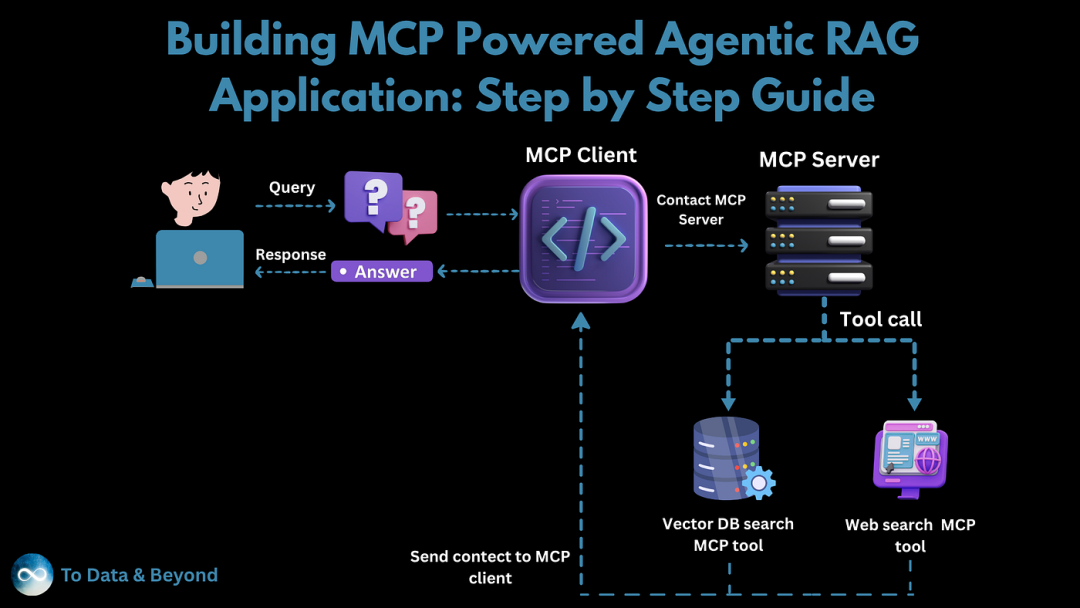
在开始之前,首先,了解一下基于MCP的 Agentic RAG 应用程序的架构,完整的流程图如下图所示:从用户的初始问题到最终的、上下文丰富的答案。

下面介绍一下该架构的关键组件:
- 用户: 流程的起点。用户提出问题并通过前端应用程序(例如,笔记本电脑上的 Web 界面)与系统进行交互。
- MCP 客户端: 这是应用程序面向用户的部分。它负责接收用户的查询,与后端服务器通信,并最终将最终的响应呈现给用户。
- MCP 服务器(代理): 这是系统的核心——运营的“大脑”。当 MCP 服务器收到请求时,它不会仅仅尝试根据自己预先训练的知识进行回答。相反,它充当代理 ,智能地决定是否需要更多信息来提供高质量的答案。
- 工具: 这些是 MCP 服务器可用于查找信息的外部资源。该架构具有两个强大的工具:
- 矢量数据库搜索 MCP 工具: 该工具连接到专门的矢量数据库来存储和搜索私有化文档、内部知识库或任何自定义文本语料库。它擅长查找语义相似的信息(RAG 中的“检索”)。
- 网络搜索 MCP 工具: 当答案不在我们的私有化数据中时,该工具允许代理在实时互联网上搜索最新和相关的公共信息。
Agentic RAG的基本流程如下所示:
- 查询提交: 用户在应用程序中输入一个问题(“查询”)。
- 客户端到服务器通信:MCP 客户端接收查询并将其转发到 MCP 服务器进行处理。
- 代理决策(工具调用): MCP 服务器分析查询并确定最佳作方案。它进行“工具调用”,决定是否应该:
- 查询 Vector DB 以获取内部专有知识。
- 执行 Web 搜索以获取实时公共信息。
- 使用两者的组合,或者如果问题足够笼统,则根本不使用。
-
信息检索(RAG 中的“R”): 所选工具执行搜索并检索相关文档、文章或数据片段。检索到的信息就是“上下文”。
-
上下文增强: 检索到的上下文被返回并用于增强原始请求。系统现在既有用户的原始查询,又有一组丰富的相关信息。
-
响应生成:MCP 客户端现在有了这个强大的上下文,可以生成全面而准确的答案。此过程称为“检索增强生成”(RAG),因为最终响应是根据检索到的信息生成的。
-
最终答案: 最终的、上下文感知的响应被发送回用户,提供的答案不仅合理,而且有真实数据的充分支持。
通过编排这些组件,我们创建了一个系统,可以通过智能地从多个来源查找和综合信息来回答复杂的问题。现在我们了解了“什么”和“为什么”,让我们继续讨论“如何”。
三、设置工作环境
现在开始实现Agentic RAG系统。在本节中,我们将配置我们的项目所需要的必要库。
在开始之前,请确保您的系统上安装了以下内容:
-
Python 3.8+ 和 pip
-
Docker(用于运行我们的矢量数据库)
首先,为项目创建一个根文件夹(例如 mcp-agentic-rag)并在其中创建以下文件。
/mcp-agentic-rag
|-- .env
|-- mcp_server.py # Our main application and server logic
|-- rag_app.py # Our RAG-specific code and data
现在,打开mcp_server.py 文件并添加以下代码。该脚本将处理导入、加载环境变量并定义我们服务的核心配置常量。
import os
from typing import List
import requests
from dotenv import load_dotenv
from mcp.server.fastmcp import FastMCP
# Updated import: Assumes FAQEngine and the FAQ text are in 'rag_app.py'
from rag_app import FAQEngine, PYTHON_FAQ_TEXT
# Load environment variables from .env file
load_dotenv()
# Configuration constants
QDRANT_URL = "http://localhost:6333"
COLLECTION_NAME = "python_faq_collection" # Using a new collection for the Python data
HOST = "127.0.0.1"
PORT = 8080
我们导入 os 和 requests 等标准库,但关键导入是:
-
from dotenv import load_dotenv:可以从单独的 .env 文件加载配置(如 API 密钥),这样我们的代码保持干净和安全。 -
from mcp.server.fastmcp import FastMCP:MCP 框架中的核心类,我们将使用它来构建服务器。 -
常见问题来自 rag_app 的 Ngine 和 PYTHON_FAQ_TEXT:这些是我们即将构建的自定义组件。PYTHON_FAQ_TEXT 将保存我们的原始数据,而 FAQEngine 将是处理嵌入和存储它的类。
我们还将为 Qdrant 连接和服务器地址定义易于访问的变量。使用常量使代码更具可读性,并且以后更容易修改。
3.1 安装 Python 库
在项目目录中打开终端,并使用 pip 安装所需的 Python 包:
pip install mcp-server qdrant-client python-dotenv requests
- mcp-server:MCP 代理的核心库。
- qdrant-client:与 Qdrant 矢量数据库交互的官方 Python 客户端。
- python-dotenv:用于加载我们的 .env 文件。
- requests:用于发出 HTTP 请求的标准库,我们的 Web 搜索工具将使用它。
3.2 创建 .env 文件
在根目录中创建一个名为 .env 的文件。在该文件写入工具需要 API 密钥(例如,OPENAI_API_KEY 或 FIRECRAWL_API_KEY)敏感信息。
# .env file
# Add any API keys or secrets here later
OPENAI_API_KEY="sk-..."
FIRECRAWL_API_KEY = "Your API Key"
3.3 启动矢量数据库 (Qdrant)
Vector DB 搜索 MCP 工具需要一个数据库来与之通信,这里将使用 Docker 快速轻松地运行 Qdrant 实例。在终端中执行以下命令:
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrant
此命令执行三个操作:
-
如果没有官方 Qdrant 映像,请下载它。
-
启动容器并映射两个端口:6333 用于 API(我们的应用将使用)和 6334 用于 Web UI。
-
挂载本地目录 (qdrant_storage) 以将数据库数据保存在主机上。
您可以通过在浏览器中打开 http://localhost:6334/ 来验证它是否正在运行。您应该会看到 Qdrant 仪表板。
现在,我们的基础已经奠定好了。我们有项目结构、初始配置、安装所有必要的库和正在运行的矢量数据库。在下一节中,我们将设置 MCP 服务器实例。

四、设置 MCP 服务器实例
配置好环境后,下一个步骤是创建应用程序的核心组件:MCP 服务器实例。此对象是 FastMCP 类的实例,将充当代理的编排器。它是管理传入请求、了解哪些工具可用以及处理查询的整个生命周期的“大脑”。
# Create an MCP server instance
mcp_server = FastMCP("MCP-RAG-app",
host=HOST,
port=PORT,
timeout=30)
下面来看一下FastMCP 构造函数的参数:
-
“MCP-RAG-app”:这是我们应用程序的唯一名称。MCP 框架在内部使用它来识别和记录,如果运行多个 MCP 服务,可以更轻松地区分不同的 MCP 服务。
-
host=HOST: 此参数告诉服务器要监听哪个网络地址。我们使用的是我们之前定义的 HOST 常量(“127.0.0.1”),这意味着服务器只能从本地计算机 (localhost) 访问。这是开发的安全默认值。
-
port=PORT: 指定服务器的网络端口。我们已将其设置为 8080。运行后,我们的应用程序将在 http://127.0.0.1:8080 处可用。
-
timeout=30:为请求设置了 30 秒的全局超时。如果工具调用花费的时间超过此时间,服务器将停止等待并返回超时错误,从而防止应用程序无限期挂起。
现在,我们的MCP服务器已经实例化,但它就像一个没有感官的大脑,已经准备好运行,但它还不知道做什么事情。在接下来的步骤中,我们定义用于从矢量数据库和网络检索信息的工具来赋予它“感官”。
五、定义 MCP 工具
我们的 MCP 服务器现在已实例化,但它就像一个拥有空工具箱的熟练工人。为了让它有用,我们需要给它工具。在 MCP 世界中,工具只是我们在服务器中“注册”的 Python 函数,注册好之后,Agent就可以选择使用该工具了。注册是通过一个简单的装饰器完成的:@mcp_server.tool()。
至关重要的是,Agent依靠函数的文档字符串(描述函数的功能以及参数的含义)来了解该工具的作用以及何时应该使用它。一个写得好的文档字符串不仅适用于开发人员,也适用于开发人员。它是对人工智能的直接指令,指导其决策过程。
让我们从定义我们的第一个工具开始:连接到我们的私有矢量数据库的工具。该工具将负责搜索我们的内部 Python 常见问题解答知识库。
将以下代码添加到 mcp_server.py 文件中。
@mcp_server.tool()
def python_faq_retrieval_tool(query: str) -> str:
"""
Retrieve the most relevant documents from the Python FAQ collection.
Use this tool when the user asks about general Python programming concepts.
Args:
query (str): The user query to retrieve the most relevant documents.
Returns:
str: The most relevant documents retrieved from the vector DB.
"""
if not isinstance(query, str):
raise TypeError("Query must be a string.")
# Use the single, pre-initialized faq_engine instance for efficiency
return faq_engine.answer_question(query)
让我们解释一下这段代码的含义:
- @mcp_server.tool():这是python装饰器,它告诉我们的 mcp_server 实例,“嘿,这是您可以使用的新功能!服务器会自动检查函数的名称、参数,以及最重要的文档字符串,以了解这项新技能。
- 文档字符串:这是代理行为最关键的部分。当代理收到用户查询时,它将阅读此说明以确定此工具是否适合该作业。我们已经明确告诉它在用户询问一般 Python 编程概念时使用此工具。这个清晰的说明使代理能够区分需要搜索我们的内部常见问题解答和搜索网络。
- python_faq_retrieval_tool(query: str) -> str: 这是一个带有类型提示的标准 Python 函数。MCP 框架使用这些提示来验证输入并了解该工具使用的数据类型。
- faq_engine.answer_question(query):这是执行工具核心逻辑。它调用 faq_engine 对象上的方法(我们将在“构建 RAG 管道”部分中构建该方法)以在我们的 Qdrant 数据库中执行实际的向量搜索,并将结果作为字符串返回。
通过这个单一的功能,我们赋予了我们的代理第一个感觉——在它自己的专用内存中查找信息的能力。接下来,我们将赋予它向外看网络的能力。
现在,如果用户询问一个非常新的 Python 库、一个时事或我们内部知识库中未涵盖的主题怎么办?为此,我们的代理需要能够浏览互联网。
我们将为我们的代理配备第二个工具,该工具使用 FireCrawl API 来执行实时 Web 搜索,为我们的代理提供了一种查找实时公共信息的方法,使其更加通用。
将最终工具添加到 mcp_server.py:
@mcp_server.tool()
def firecrawl_web_search_tool(query: str) -> List[str]:
"""
Search for information on a given topic using Firecrawl.
Use this tool when the user asks a specific question not related to the Python FAQ.
Args:
query (str): The user query to search for information.
Returns:
List[str]: A list of the most relevant web search results.
"""
if not isinstance(query, str):
raise TypeError("Query must be a string.")
url = "https://api.firecrawl.dev/v1/search"
api_key = os.getenv('FIRECRAWL_API_KEY')
if not api_key:
return ["Error: FIRECRAWL_API_KEY environment variable is not set."]
payload = {"query": query, "timeout": 60000}
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
try:
response = requests.post(url, json=payload, headers=headers)
response.raise_for_status()
# Raise an exception for bad status codes (4xx or 5xx)
# Assuming the API returns JSON with a key like "data" or "results" # Adjust .get("data", ...) if the key is different
return response.json().get("data", ["No results found from web search."])
except requests.exceptions.RequestException as e:
return [f"Error connecting to Firecrawl API: {e}"]
这个 firecrawl_web_search_tool 功能是我们代理的另一个强大功能。使用相同的 @mcp_server.tool()装饰器注册,其文档字符串提供了何时使用它的关键说明:对于与 Python FAQ 无关的任何问题。
这与我们的第一个工具有明显的区别,使代理能够做出明智的选择。该函数的逻辑很简单:它从我们的环境变量中安全地检索 Firecrawl API Key,构造包含用户查询的 POST 请求,并将其发送到 Firecrawl API。
为了确保我们的应用程序具有弹性并且不会在网络故障时崩溃,整个 API 调用都包装在 try…except 块,允许它优雅地处理连接问题。请求成功后,它会解析 JSON 响应并返回搜索结果列表,从而有效地使我们的代理能够访问互联网的大量信息。
现在定义了这两种工具,我们的代理可以选择:向内查看其私人知识库或向外部查看公共网络。接下来,我们将构建为内部知识搜索提供支持的引擎。
六、构建 RAG 管道
我们的 python_faq_retrieval_tool 目前只是一个承诺,它依赖于一个 faq_engine 对象来完成矢量搜索的繁重工作,但我们还没有构建这个引擎。该组件是我们 RAG 系统“检索”部分的核心。它将负责两项关键任务:
-
索引: 获取我们的纯文本数据,将其转换为数值表示(嵌入),并将它们有效地存储在我们的 Qdrant 矢量数据库中。
-
搜索: 提供一种方法,可以获取用户的查询,将其转换为嵌入,并在数据库中搜索最相关的存储信息。
为了实现这一目标,我们将编排几个功能强大的库。我们将使用 llama-index 来实现其强大的嵌入功能,使用 qdrant-client 与我们的数据库进行通信,并使用一些标准的 Python 实用程序来有效地处理数据处理。
让我们首先创建 rag_app.py 文件并添加必要的导入,这些导入将构成我们管道的支柱。
import uuid
from itertools import islice
from typing import List, Dict, Any, Generator
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from tqdm import tqdm
from qdrant_client import models, QdrantClient
构建管道的第一步是定义知识库本身。这是我们的代理将搜索的专有数据,以回答与 Python 相关的问题。
在我们的 rag_app.py 文件中,在导入下方添加源文本:
PYTHON_FAQ_TEXT = """
Question: What is the difference between a list and a tuple in Python?
Answer: Lists are mutable, meaning their elements can be changed, while tuples are immutable. Lists use square brackets `[]` and tuples use parentheses `()`.
Question: What are Python decorators?
Answer: Decorators are a design pattern in Python that allows a user to add new functionality to an existing object without modifying its structure. They are often used for logging, timing, and access control.
Question: How does Python's Global Interpreter Lock (GIL) work?
Answer: The GIL is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecode at the same time. This means that even on a multi-core processor, only one thread can execute Python code at once.
Question: What is the difference between `==` and `is` in Python?
Answer: `==` checks for equality of value (do two objects have the same content?), while `is` checks for identity (do two variables point to the same object in memory?).
Question: Explain list comprehensions and their benefits.
Answer: List comprehensions provide a concise way to create lists. They are often more readable and faster than using traditional `for` loops and `.append()` calls.
Question: What is `*args` and `**kwargs` in function definitions?
Answer: `*args` allows you to pass a variable number of non-keyword arguments to a function, which are received as a tuple. `**kwargs` allows you to pass a variable number of keyword arguments, received as a dictionary.
Question: What are Python's magic methods (e.g., `__init__`, `__str__`)?
Answer: Magic methods, or dunder methods, are special methods that you can define to add "magic" to your classes. They are invoked by Python for built-in operations, like `__init__` for object creation or `__add__` for the `+` operator.
Question: How does error handling work in Python?
Answer: Python uses `try...except` blocks to handle exceptions. Code that might raise an error is placed in the `try` block, and the code to handle the exception is placed in the `except` block.
Question: What is the purpose of the `if __name__ == "__main__":` block?
Answer: This block ensures that the code inside it only runs when the script is executed directly, not when it is imported as a module into another script.
Question: What are generators in Python?
Answer: Generators are a simple way to create iterators. They are functions that use the `yield` keyword to return a sequence of values one at a time, saving memory for large datasets.
"""
在本指南中,我们将知识作为多行字符串直接嵌入到脚本中。在生产应用程序中,您通常会从文档集合(如文本文件 、PDF 或数据库)加载此数据 , 但原理保持不变。
此 PYTHON_FAQ_TEXT 变量包含常见 Python 问题和答案的精选列表。每个 Q&A 对都是一个独立的信息块,使其成为我们向量数据库的理想格式。当我们索引这些数据时,每个块都将成为我们的代理可以检索的可搜索单元。
定义数据后,下一步是创建一个可以处理它的类。
定义数据后,我们现在需要构建可以处理、索引和查询数据的引擎。这就是 FAQEngine 类的用武之地。它是 RAG 管道的核心组件,封装了与嵌入模型和 Qdrant 向量数据库交互的所有逻辑。
首先,我们将在 rag_app.py 中添加一个小的辅助函数。此功能将帮助我们以可管理的块处理数据,这对于处理大型数据集时的内存效率和性能至关重要。
# Helper function for batching
def batch_generator(data: List[Any], batch_size: int) -> Generator[List[Any], None, None]:
"""Yields successive n-sized chunks from a list."""
for i in range(0, len(data), batch_size):
yield data[i : i + batch_size]
现在,让我们定义将所有内容组合在一起的主类。
class FAQEngine:
"""
An engine for setting up and querying a FAQ database using Qdrant and HuggingFace embeddings.
"""
def __init__(self,
qdrant_url: str = "http://localhost:6333",
collection_name: str = "python-faq",
embed_model_name: str = "nomic-ai/nomic-embed-text-v1.5"):
self.collection_name = collection_name
# Initialize the embedding model
print("Loading embedding model...")
self.embed_model = HuggingFaceEmbedding(
model_name=embed_model_name,
trust_remote_code=True
)
# Dynamically get the vector dimension from the model
self.vector_dim = len(self.embed_model.get_text_embedding("test"))
print(f"Embedding model loaded. Vector dimension: {self.vector_dim}")
# Initialize the Qdrant client
self.client = QdrantClient(url=qdrant_url, prefer_grpc=True)
print("Connected to Qdrant.")
@staticmethod
def parse_faq(text: str) -> List[str]:
"""Parses the raw FAQ text into a list of Q&A strings."""
return [
qa.replace("\n", " ").strip()
for qa in text.strip().split("\n\n")
]
def setup_collection(self, faq_contexts: List[str], batch_size: int = 64):
"""
Creates a Qdrant collection (if it doesn't exist) and ingests the FAQ data.
"""
# Check if collection exists, create if not
try:
self.client.get_collection(collection_name=self.collection_name)
print(f"Collection '{self.collection_name}' already exists. Skipping creation.")
except Exception:
print(f"Creating collection '{self.collection_name}'...")
self.client.create_collection(
collection_name=self.collection_name,
vectors_config=models.VectorParams(
size=self.vector_dim,
distance=models.Distance.DOT
)
)
print(f"Embedding and ingesting {len(faq_contexts)} documents...")
# Process data in batches
for batch in tqdm(batch_generator(faq_contexts, batch_size),
total=(len(faq_contexts) // batch_size) + 1,
desc="Ingesting FAQ data"):
# 1. Get embeddings for the batch
embeddings = self.embed_model.get_text_embedding_batch(batch, show_progress_bar=False)
# 2. Create Qdrant points with unique IDs and payloads
points = [
models.PointStruct(
id=str(uuid.uuid4()), # Generate a unique ID for each point
vector=vector,
payload={"context": context}
)
for context, vector in zip(batch, embeddings)
]
# 3. Upload points to the collection
self.client.upload_points(
collection_name=self.collection_name,
points=points,
wait=False # Asynchronous upload for speed
)
print("Data ingestion complete.")
print("Updating collection indexing threshold...")
self.client.update_collection(
collection_name=self.collection_name,
optimizer_config=models.OptimizersConfigDiff(indexing_threshold=20000)
)
print("Collection setup is finished.")
def answer_question(self, query: str, top_k: int = 3) -> str:
"""
Searches the vector database for a given query and returns the most relevant contexts.
"""
# 1. Create an embedding for the user's query
query_embedding = self.embed_model.get_query_embedding(query)
# 2. Search Qdrant for the most similar vectors
search_result = self.client.search(
collection_name=self.collection_name,
query_vector=query_embedding,
limit=top_k,
score_threshold=0.5 # Optional: filter out less relevant results
)
# 3. Format the results into a single string
if not search_result:
return "I couldn't find a relevant answer in my knowledge base."
relevant_contexts = [
hit.payload["context"] for hit in search_result
]
# Combine the contexts into a final, readable output
formatted_output = "Here are the most relevant pieces of information I found:\n\n---\n\n".join(relevant_contexts)
return formatted_output
构造函数 __init__ 负责设置所有必要的组件。它从 llama-index 初始化 HuggingFaceEmbedding 模型,该模型将处理文本到向量的转换。
这里的一个关键细节是,我们通过嵌入测试字符串来动态确定 vector_dim;这使得我们的代码健壮并适应不同的嵌入模型。最后,它建立了与我们的 Qdrant 数据库的连接。print 语句在运行脚本时向用户提供有用的反馈。
在为数据创建索引之前,我们需要对其进行清理。parse_faq static 方法是一个简单的实用程序,它获取我们的原始 PYTHON_FAQ_TEXT 并将其拆分为单个问题/答案字符串的干净列表,这是我们数据库的完美格式。
setup_collection 方法是索引魔法发生的地方。它首先检查具有我们指定名称的 Qdrant 集合是否已经存在,从而防止我们每次启动应用程序时浪费地重新索引数据。如果它不存在,它会创建一个新的,并使用正确的矢量大小和距离指标对其进行配置。
然后,它开始循环,使用我们的 batch_generator 帮助程序以高效的块处理常见问题解答数据。在此循环中,每批都会发生三步过程:
- 嵌入: 它将这批文本块转换为数字向量列表。
- 结构化: 它将每个向量打包到 Qdrant PointStruct 中,其中包括一个唯一的 ID 和一个包含原始文本的有效负载。这个有效负载至关重要,因为它允许我们在搜索后检索人类可读的上下文。
- 上传: 它将这些Point发送到 Qdrant 集合。
最后,answer_question 方法是我们代理的工具将调用的方法。这是“检索”步骤。它接受用户的查询,使用相同的嵌入模型将其转换为向量,然后使用 client.search 函数在我们的数据库中查找最相似的向量。
然后,它从top结果中提取原始文本,并将其格式化为单个干净的字符串。这种格式化的文本是最终用于生成高质量答案的“上下文”。
七、将所有内容放在一起并测试系统
我们拥有所有单独的组件:服务器、工具和 RAG 引擎。现在,让我们将它们连接在一起 mcp_server.py 并启动我们的应用程序。
# This should be at the end of the mcp_server.py file
if __name__ == "__main__":
# 1. Initialize our RAG Engine
print("Initializing FAQ Engine and setting up Qdrant collection...")
faq_engine = FAQEngine(qdrant_url=QDRANT_URL, collection_name=COLLECTION_NAME)
# 2. Ingest our data into the vector database
# This will create embeddings and store them
faq_engine.setup_collection(PYTHON_FAQ_TEXT)
# 3. Start the MCP server
print(f"Starting MCP server at http://{HOST}:{PORT}")
mcp_server.run()
最后一个块按顺序执行三件事:
-
创建 FAQEngine 的实例。
-
调用 setup_collection()来处理我们的文本并将其加载到 Qdrant 中。
-
启动 mcp_server,该现在将监听传入的请求。
请务必确保 Qdrant 的 Docker 容器仍在运行。然后,在项目目录中打开终端并运行服务器:
python mcp_server.py
您应该会看到输出,指示正在设置常见问题解答引擎并且服务器正在运行:
Initializing FAQ Engine and setting up Qdrant collection...
Collection not found. Creating and indexing...
Indexing complete.
Starting MCP server at http://127.0.0.1:8080
INFO: Started server process [12345]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
服务器已上线!现在,让我们充当客户端并向其发送请求。打开一个新的终端窗口 ,并使用 curl 与我们的代理进行交互。
测试用例 1:查询 Python 常见问题解答
让我们问一个应该由我们的内部知识库来回答的问题。
curl -X POST http://127.0.0.1:8080/mcp \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "user",
"content": "Can you explain list comprehensions in Python?"
}
]
}'
代理应正确选择 python_faq_retrieval_tool。该工具将查询 Qdrant,您将从 PYTHON_FAQ_TEXT 获得包含相关上下文的响应。来自服务器的响应将是一个 JSON 对象,其中包含工具调用和结果:
{
"messages": [
//... original message ...
{
"role": "assistant",
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "python_faq_retrieval_tool",
"arguments": "{\"query\": \"list comprehensions in Python\"}"
}
}
]
},
{
"role": "tool",
"tool_call_id": "call_abc123",
"name": "python_faq_retrieval_tool",
"content": "Retrieved Context from FAQ:\nWhat is a list comprehension in Python?\nA: A list comprehension is a concise way to create lists. It consists of brackets containing an expression followed by a for clause, then zero or more for or if clauses. The expressions can be anything, meaning you can put in all kinds of objects in lists."
}
]
}
测试用例 2:查询 Web
现在,让我们问一些我们的常见问题解答不知道的事情。确保 .env 文件中有 FIRECRAWL_API_KEY。
curl -X POST http://127.0.0.1:8080/mcp \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "user",
"content": "What is the new Polars DataFrame library?"
}
]
}'
这一次,代理将看到“Polars”不在其 FAQ 工具的文档字符串中。它将选择 web_search_tool。响应看起来类似,但将包含 FireCrawl 获取的 Markdown 内容。
到目前为止,已经成功地从头开始构建了一个复杂的Agentic RAG 应用程序。通过利用模型上下文协议,已经创建了一个模块化、智能且足智多谋的系统。
我们已经了解了 MCP 如何允许我们定义不同的工具,以及代理如何使用简单的文档字符串来智能地决定将哪种功能用于给定查询。这种强大的模式允许用户创建可以推理自己的能力并动态地从私有知识库(通过 RAG)和公共 Internet 中提取信息的应用程序,从而获得更准确和有用的响应。
在这里,可以通过添加更多工具(例如计算器、数据库查询工具)、将更复杂的文档引入 RAG 管道或将其连接到真实用户界面来扩展系统。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 8
8 0
0- 0



 已为社区贡献224条内容
已为社区贡献224条内容

所有评论(0)