程序员泪目!大模型RAG隐私保护“黑科技“:DistilledPRAG,让敏感数据不再“裸奔“!
本文介绍DistilledPRAG技术,解决传统RAG系统明文文档暴露隐私问题及Parametric RAG的运维负担与表示不对齐问题。通过知识蒸馏,让"学生模型"在对齐文档结构与内部激活的前提下逼近"教师模型"推理能力,且全程不发送明文。实验表明,该方法在多个数据集上表现优于基线,有效平衡了隐私保护与推理性能。
你是否认真考虑过 RAG 流水线中的文档隐私?这篇文章也许能提供一个有帮助的方向。
一、为什么“Standard RAG → Cloud Search”在隐私上行不通
Standard RAG 的做法是把明文文档塞进 prompt。对于企业合同、病历或个人笔记等输入,这是完全不可行的——从设计上你就在暴露敏感数据。
Parametric RAG (PRAG) 试图把知识“烘进”LoRA 权重,但在实践中碰上两堵墙:
- 运维负担与时延。每份文档都需要各自的 synthetic Q&A 生成以及定制化的 LoRA 微调。在线服务时还要在这些 adapter 之间周转切换,真实世界的时延与运维开销难以接受。
- 表示不对齐。模型从 synthetic Q&A 学到的内容,往往与 Standard RAG 的表征与检索方式对不上,导致在 OOD 输入上的泛化较弱。
二、什么是 DistilledPRAG?(一句话版)
通过知识蒸馏,让“学生模型”(parametric RAG)在对齐文档结构与内部激活的前提下,逼近“教师模型”(standard RAG)的推理能力,并且全程不发送明文。
实操要点
- 先合成,再对齐。构造 289,079 个覆盖单文档与跨文档场景的 Q&A 样本。对学生模型,用特殊的 mask tokens 替代原始文档;一个 parameter generator 将每份文档“翻译”为对应的 LoRA。随后在两条战线进行蒸馏——hidden states 与 output distributions——让学生对齐教师。
- 训练/推理同构。训练时拼接多份文档;推理时检索 top-k、拼接,然后生成一份 unified LoRA 来生成答案——而不是像 PRAG/DyPRAG 那样为每份文档各自生成 LoRA 再相加或取平均。

Figure 1: Inference Paradigms for standard RAG, PRAG, DyPRAG, and DistilledPRAG. (1) Standard RAG inputs the plaintext documents and question. (2) PRAG generates QA pairs per document to fine-tune LoRA adapters, and sums them to obtain document aggregated representations for LLM injection. (3) DyPRAG translates individual documents to its LoRA and averages them to achieve document aggregation for LLM injection. (4) DistilledPRAG concatenates documents to parameter generator to create cross-document LoRA, and masks documents with question as input, more similar to standard RAG. [Source].
Figure 1 对比了 Standard RAG、PRAG、DyPRAG 与 DistilledPRAG 的推理模式。DistilledPRAG 会检索并拼接多份文档,然后“一次性”生成单个跨文档 LoRA——其输入流更接近 Standard RAG。
三、深入解析:DistilledPRAG 的三个核心组件
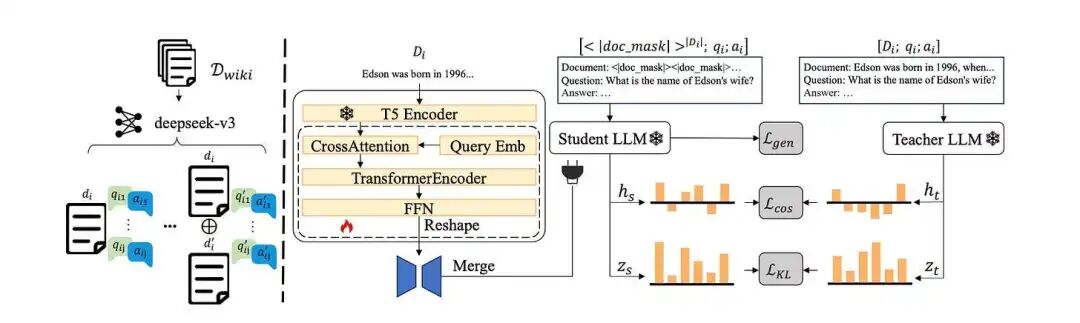
Figure 2: The Architecture of DistilledPRAG Model. 1. Use DeepSeek-V3 to mine knowledge from a single document and augmented cross-documents by random concatenation. 2. Train a parameter generator to map documents to a LoRA for student LLM, enabling it to mimic a teacher RAG’s reasoning by minimizing differences in hidden states and logits on synthetic data. [Source].
Figure 2 展示了 DistilledPRAG 中的 parameter generator 的工作方式:LongT5 对文档编码 → 按层索引的可学习 queries 执行 cross-attention pooling → self-attention encoder 进一步提炼信号 → FFN 产生目标 LoRA。仅训练 generator;base LLM 与 document encoder 均冻结。
合成数据:让跨文档推理成为默认模式
- 来源。随机从 2WQA 训练集采样 30,000 篇文档。生成约 139,723 个单文档 Q&A,再通过拼接生成约 149,356 个跨文档 Q&A——合计为 289,079。
- 目标。覆盖单文档事实,同时强化跨文档整合,让模型在多文档输入下学会生成单个、整体性的 LoRA。
parameter generator:从长文档到单个 LoRA 包
- Encoder。使用 LongT5 将文档映射为序列表征。
- Cross-attention。用按“layer”索引的可学习 queries 对文档表征做 cross-attention,得到 H0。
- Self-attention + FFN。进一步编码 H0,并直接回归目标 LoRA Δθ。
- 冻结部分。仅训练生成器 Genω;保持基础模型参数 θ 与文档编码器 ψ 冻结。
对齐目标:generation、hidden states 与 logits
- Generation loss。在文档被 mask、仅可见问题的输入条件下,最小化答案的 NLL。
- Hidden-state alignment。跨层的余弦损失 Lcos,采用逐层增权,靠近输出层权重更高。
- Logit alignment。token 级 KL 散度 LKL,用于对齐输出分布。
推理范式:与训练严格同构
用 BM25 检索 top-3 文档 → 按检索顺序拼接 → 用特殊的 mask tokens 替换文档得到 x~ → parameter generator 产出单个 LoRA Δθ → 使用适配后的基础模型 fθ+Δθ 回答。全程不暴露明文。
四、评价
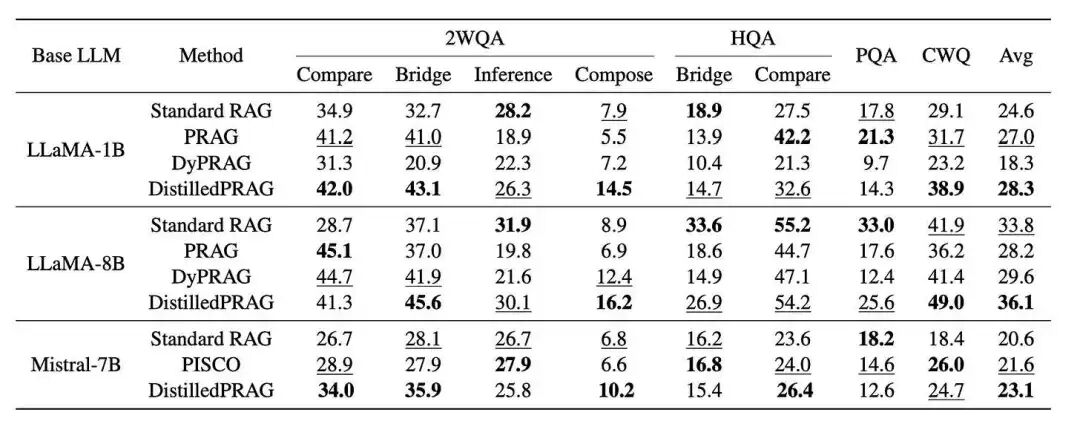
Figure 3: Overall F1(%) performance of DistilledPRAG and baselines on 2WQA, HQA, PQA and CWQ datasets. Bold indicates the best performance, and underlined indicates the second best. [Source].
设置。以各子任务 dev 集的前 300 个问题计算 F1 (%)。检索固定为 BM25(top-3)。训练仅使用 2WQA。基线包括 Standard RAG、PRAG、DyPRAG 与 PISCO。
主要结果:
- LLaMA-8B。DistilledPRAG 平均为 36.1,优于 Standard RAG(33.8),并明显领先 DyPRAG(29.6)与 PRAG(28.2)。在 CWQ(开放域复杂查询)上达到 49.0——在相同 base 的所有变体中最佳。
- LLaMA-1B。DistilledPRAG 为 28.3,对比 Standard RAG(24.6)、DyPRAG(18.3)与 PRAG(27.0)。
- Mistral-7B。DistilledPRAG 为 23.1,优于 Standard RAG(20.6)与 PISCO(21.6)。
结论。即便只在 2WQA 上训练,DistilledPRAG 在 HQA、PQA、CWQ 等 OOD 数据集上也能保持竞争力,甚至领先。证据表明,同时对齐结构与激活比单靠 synthetic QA 的迁移更有效。
五、思考
关键洞见在于把多文档证据压缩为一个跨文档的 LoRA,并用“二重对齐”(hidden states + logits)让学生模型在从未见过明文的情况下逼近教师的决策边界。本质上,这是把检索上下文从显式的 context window 转移到了隐式的 parameter channel。
两项现实成本值得注意:计算量随 mask 长度与 base model 规模增长;同时 generator 在 OOD 输入上的鲁棒性仍需压测。可以通过两点改进权衡:(a) 将单一、统计初始化的 mask 升级为分层、可组合的 token 集合;(b) 在 generator 中加入结构化稀疏与可验证的信息流约束——两者都旨在获得更好的延迟-隐私 Pareto。
进一步地,把“single LoRA”泛化为一个 task-graph-aware 的 LoRA 组件混合体,其中不同的证据簇激活可解释的低秩子空间;并行配套一个可审计的 retrieval trace,使多跳推理在可解释性与误差控制上同步增强,而非在多跳中累积失真。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献244条内容
已为社区贡献244条内容

所有评论(0)