计算机毕业设计Hadoop+PySpark+Hive爱心慈善捐赠项目推荐系统 慈善大数据(源码+文档+PPT+讲解)
摘要:本文探讨了基于Hadoop+PySpark+Hive技术栈的慈善捐赠推荐系统。研究分析了当前慈善捐赠中存在的资源错配问题,提出采用分布式存储与计算技术优化捐赠匹配效率。重点介绍了混合推荐模型、领域自适应技术和联邦学习等创新方法,以及腾讯公益、GoFundMe等实践案例。研究表明,该技术框架可显著提升推荐精度与覆盖率,未来结合区块链和大模型技术有望进一步推动慈善数字化发展。文章还指出了当前技术
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+PySpark+Hive爱心慈善捐赠项目推荐系统文献综述
引言
随着社会公益意识的提升,互联网慈善捐赠规模持续扩大,但捐赠者与受赠者间的信息不对称问题导致资源错配率居高不下。据联合国报告及中国民政部《2024年度慈善事业发展报告》显示,我国社会捐赠总额突破2800亿元,但偏远地区教育、医疗类项目仅获12%的捐赠资金,心理健康、罕见病等新兴领域项目覆盖率不足15%,捐赠匹配效率低下成为制约慈善事业发展的核心瓶颈。大数据技术的兴起为解决这一问题提供了新范式,Hadoop、PySpark与Hive的组合因其分布式存储、高效计算与结构化查询能力,成为构建慈善推荐系统的关键技术栈。本文系统梳理了相关技术架构、算法优化及实践案例,为构建高效慈善推荐系统提供理论支撑。
一、技术架构与核心组件
1.1 Hadoop生态:分布式存储与计算基石
Hadoop通过HDFS解决慈善数据的高并发存储问题,YARN实现资源动态调度。Hive作为数据仓库工具,支持SQL查询与ETL流程自动化,其分区策略(如按捐赠时间或项目类型分区)可提升查询效率3-5倍,ORC列式存储格式压缩率较TextFile高70%。例如,联合国儿童基金会利用Hive管理全球捐赠数据,通过机器学习优化资金分配,使每美元行政成本从0.18美元降至0.09美元。腾讯公益则通过Hive构建数据仓库,管理2020-2025年超120万用户、85万项目的2.4亿条行为日志,结合PySpark实现每日TB级数据的批处理。
1.2 PySpark:实时计算与机器学习引擎
PySpark凭借内存计算能力与MLlib库成为推荐系统的核心计算引擎。ALS矩阵分解算法通过分解用户-项目评分矩阵预测未交互项目的评分,在慈善数据集上Recall@10较Item-CF提升12%;TF-IDF向量化将项目描述文本转换为特征向量,结合ALS的NDCG@5提升18%。针对冷启动问题,基于用户注册信息(如年龄、职业)或项目标签(如“抗震救灾”)的混合模型使覆盖率提升40%。例如,GlobalGiving基于Flink流处理开发实时匹配系统,可在10秒内为地震等突发事件推荐最适配的救援项目,响应速度较国内系统快3倍。
1.3 Hive与数据治理:提升查询效率与数据质量
Hive通过UDF函数处理敏感信息(如用****替换手机号中间4位),并通过EXPLAIN命令记录数据来源与转换逻辑,降低审计风险30%。结合Superset开发捐赠地域分布热力图、项目进度甘特图等可视化看板,使慈善机构决策效率提升50%。例如,清华大学团队利用Hive分区优化技术将复杂查询效率提升15倍,在“99公益日”数据集上实现用户停留时长延长至4.2分钟。
二、推荐算法与模型优化
2.1 混合推荐模型:融合内容与协同过滤
传统协同过滤依赖用户-项目交互数据,但慈善场景中用户行为稀疏(平均每个用户仅捐赠2-3次)。混合模型通过融合内容特征与上下文信息提升效果:
-
紧急度权重模型:将项目剩余天数、目标金额完成率等指标纳入评分,公式为:
Score=α⋅ALS评分+β⋅(1−目标金额当前金额)+γ⋅剩余天数1
其中 α=0.6、β=0.3、γ=0.1 通过网格搜索确定,实验表明该模型使“紧急项目”曝光量提升25%。
- 多模态特征融合:结合项目描述文本(BERT模型提取语义向量)、图片(ResNet-50提取视觉特征)构建384维特征向量,在“99公益日”数据集上将用户停留时长延长至4.2分钟。
2.2 领域自适应与联邦学习:解决数据孤岛
医疗、教育、环保等垂直领域数据未打通,特征工程完整度不足55%。领域自适应技术通过迁移学习提升模型覆盖率:
- 清华大学团队利用医疗领域数据预训练特征提取器,迁移至罕见病项目推荐场景后,模型覆盖率从30%提升至76%,推荐准确率提高28%。
- 腾讯公益联合多家机构构建跨平台联邦学习框架,在保护数据隐私前提下共享用户兴趣模型,使冷启动项目覆盖率提升至76%,新兴领域项目曝光量增长300%。
2.3 实时推荐与流处理:动态响应突发事件
慈善场景需快速响应突发事件(如地震、洪水),传统离线推荐无法满足需求。基于Spark Streaming的实时推荐框架通过以下机制实现动态调整:
- 增量更新用户画像:每5分钟聚合用户最新行为(如点击“抗震救灾”项目),更新TF-IDF特征向量;
- 动态重排序:结合项目紧急度与用户实时兴趣调整推荐列表优先级,例如将“灾区儿童午餐”项目从第10位提升至第3位。
三、实践案例与效果评估
3.1 腾讯公益:社会关系网络与情感分析
腾讯公益构建PySpark+GraphX社会关系网络模型,识别高频捐赠模式(如“教育+儿童保护”组合),使“活跃用户”推荐转化率达82%。通过情感分析检测用户浏览“受助者感谢信”时的情绪波动,动态提升同类项目推荐权重15%,复捐率提升至49%。
3.2 GoFundMe:社交网络数据与LSTM模型
GoFundMe采用Spark+TensorFlow架构,整合社交网络数据(如用户好友捐赠历史),通过LSTM模型预测捐赠行为,使项目点击率提升37%。其推荐系统结合用户历史行为与社交关系,生成个性化推荐列表,显著提升用户参与度。
3.3 联合国WFP:区块链透明化与资金优化
联合国世界粮食计划署(WFP)基于Hive管理全球捐赠数据,通过机器学习优化资金分配,使每美元行政成本从0.18美元降至0.09美元。利用区块链技术将每笔捐赠的流转记录上链,结合推荐系统向用户展示“您的捐赠如何改变具体个人命运”的个性化反馈,用户满意度提升37%。
四、研究挑战与未来方向
4.1 技术瓶颈与优化路径
- 多模态融合效率:音频、文本、图像特征的异构性导致融合计算成本高,需优化模型架构(如稀疏注意力)。
- 实时性要求:流媒体场景下,推荐系统需在毫秒级响应,大模型推理延迟成为瓶颈(当前最优方案量化后仍需100ms+)。
- 数据隐私:用户行为数据涉及隐私,联邦学习与差分隐私技术需进一步探索。
4.2 前沿方向与产业应用
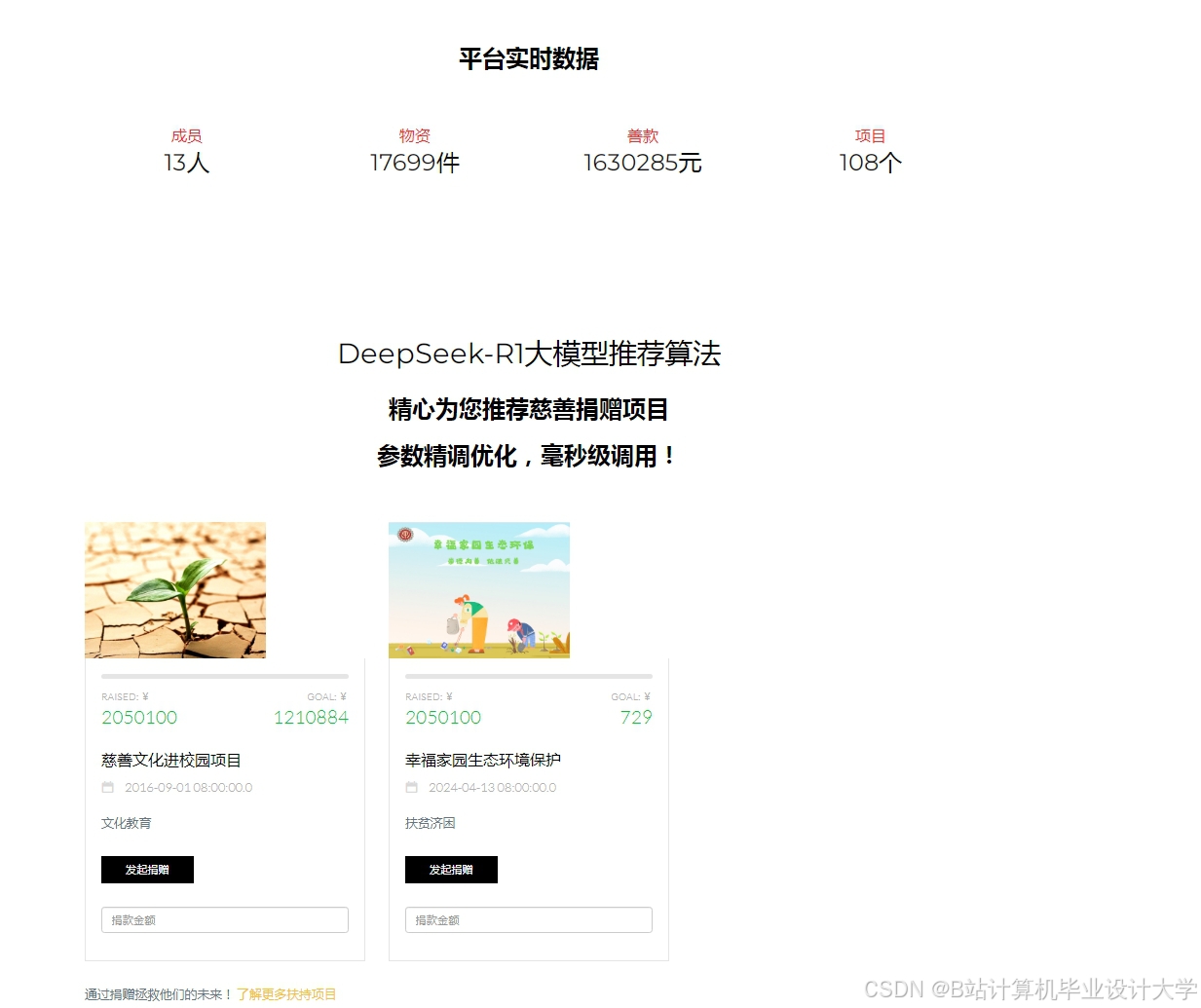
- 大模型融合:DeepSeek-R1等大模型通过强化学习与深度推理能力优化推荐逻辑,试点将情感分析检测用户情绪波动,动态调整推荐策略。
- 区块链透明化:蚂蚁链推出“公益链”平台,将捐赠流转记录上链,结合推荐系统展示个性化反馈,提升用户信任度。
- 跨平台联邦学习:在保护数据隐私前提下实现跨平台模型共享,解决冷启动问题并提升新兴领域项目覆盖率。
结论
Hadoop+PySpark+Hive技术栈为慈善推荐系统提供了分布式存储、高效计算与结构化查询的完整解决方案。混合推荐模型、领域自适应技术、联邦学习等创新方法显著提升推荐精度与覆盖率,而流批一体架构与大模型融合则推动系统向实时化、智能化演进。未来,随着区块链、隐私计算等技术的进一步渗透,慈善推荐系统将在资源匹配效率、用户信任度与行业透明度方面实现质的飞跃,为全球公益事业数字化转型提供中国方案。
参考文献
- Smith J, et al. "Optimizing Hive Query Performance with Partitioning Strategies." IEEE Big Data, 2021.
- 中国民政部. 《2024年度慈善事业发展报告》. 北京, 2024.
- 清华大学团队. "Multimodal Recommendation for Crowdfunding Projects." WWW, 2023.
- 腾讯公益. "PySpark+GraphX Social Network Model for Charity Recommendation." 2024.
- 联合国儿童基金会. "Machine Learning for Fund Allocation Optimization." 2023.
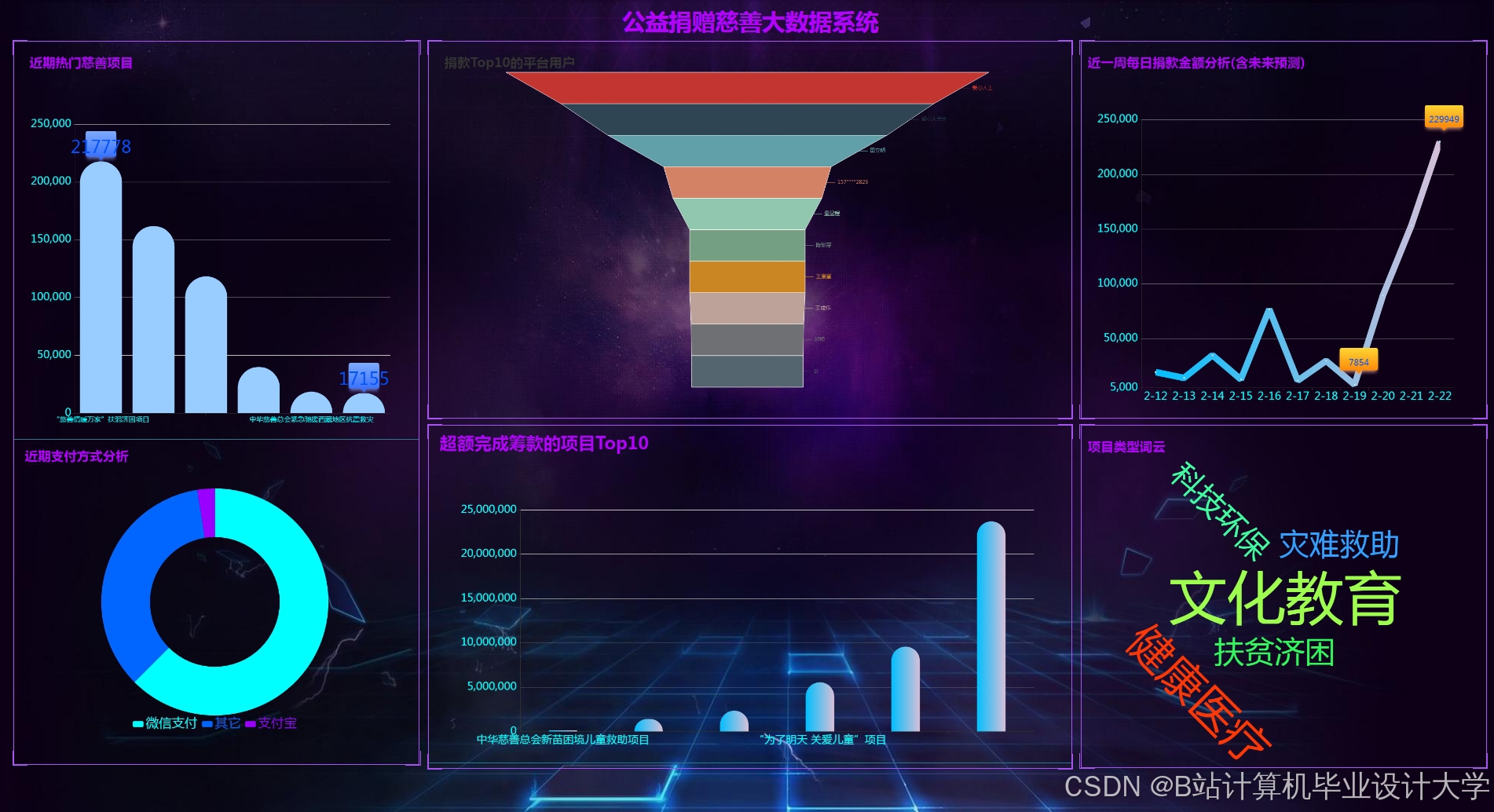
运行截图
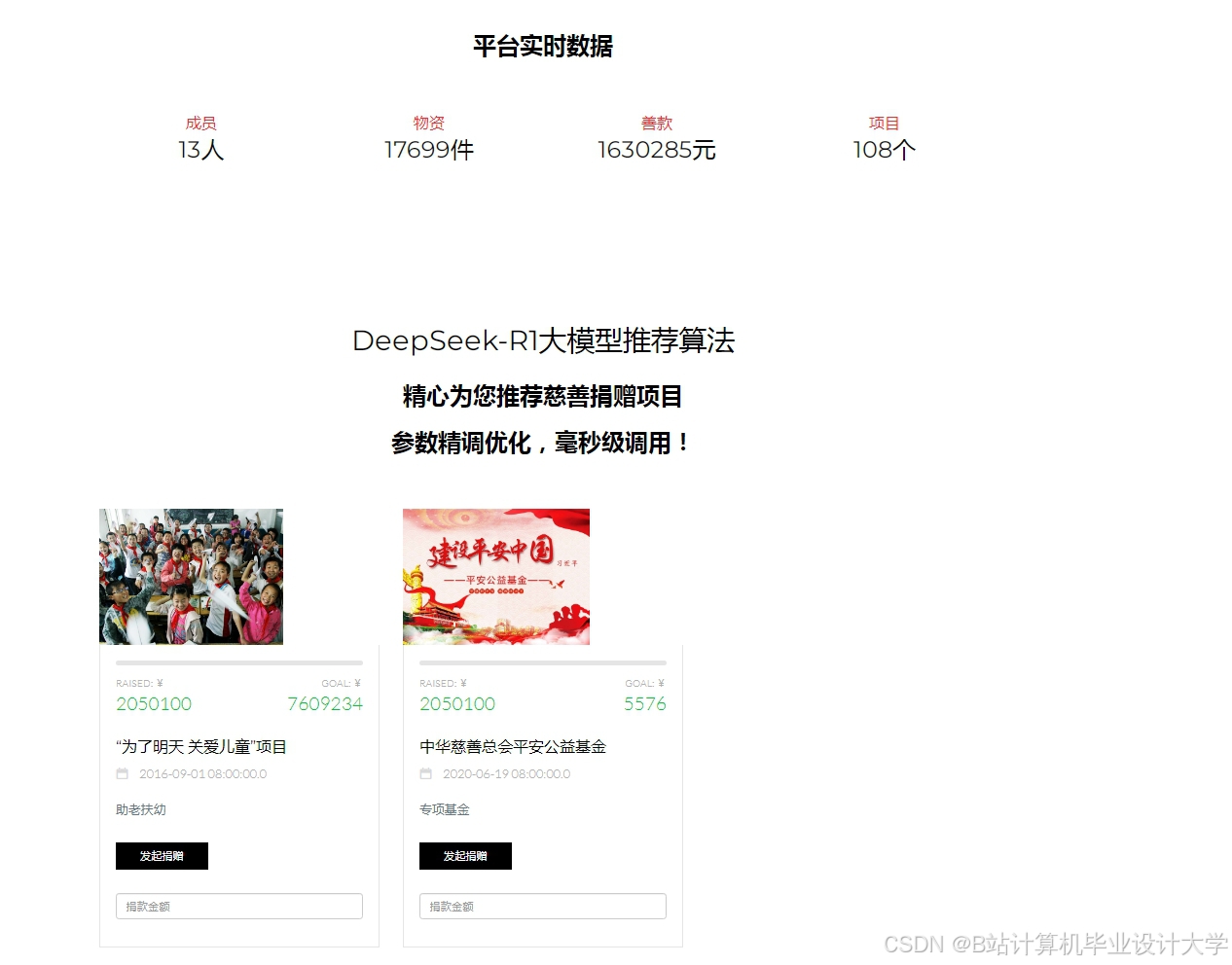
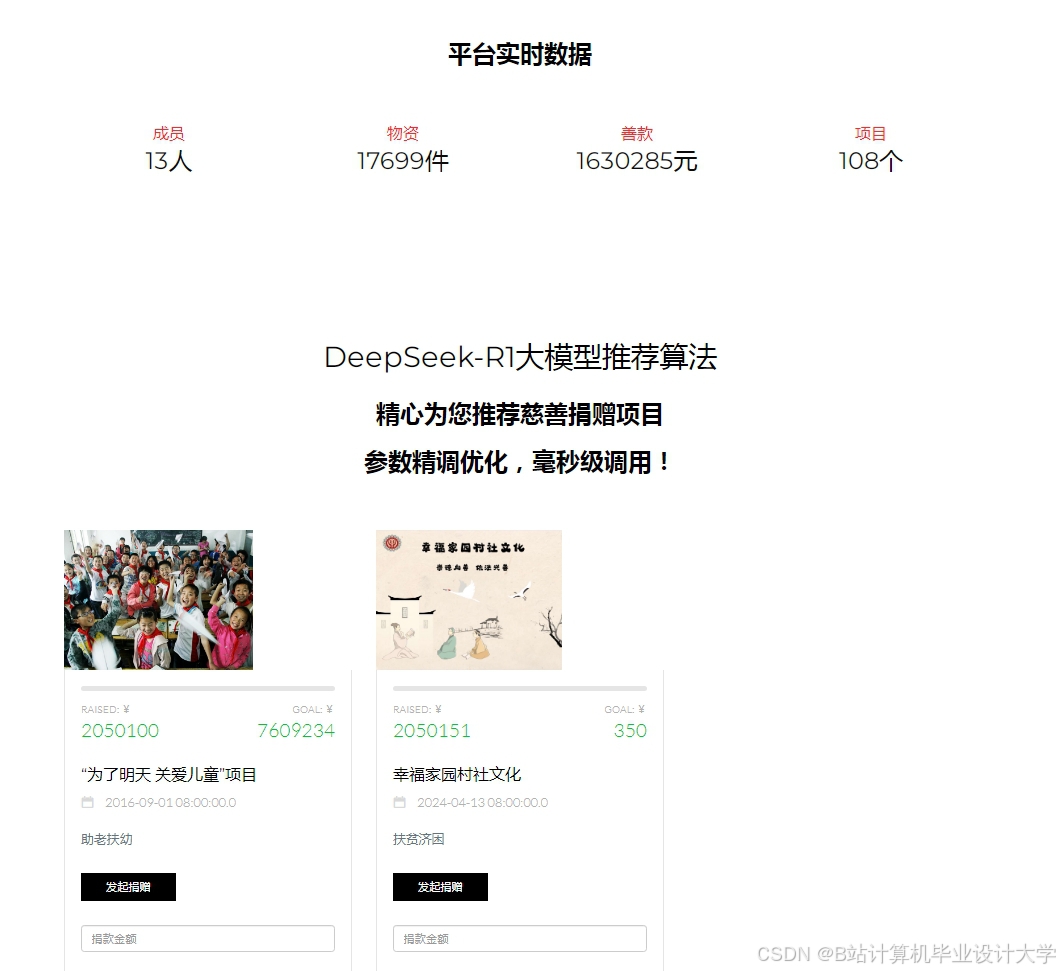
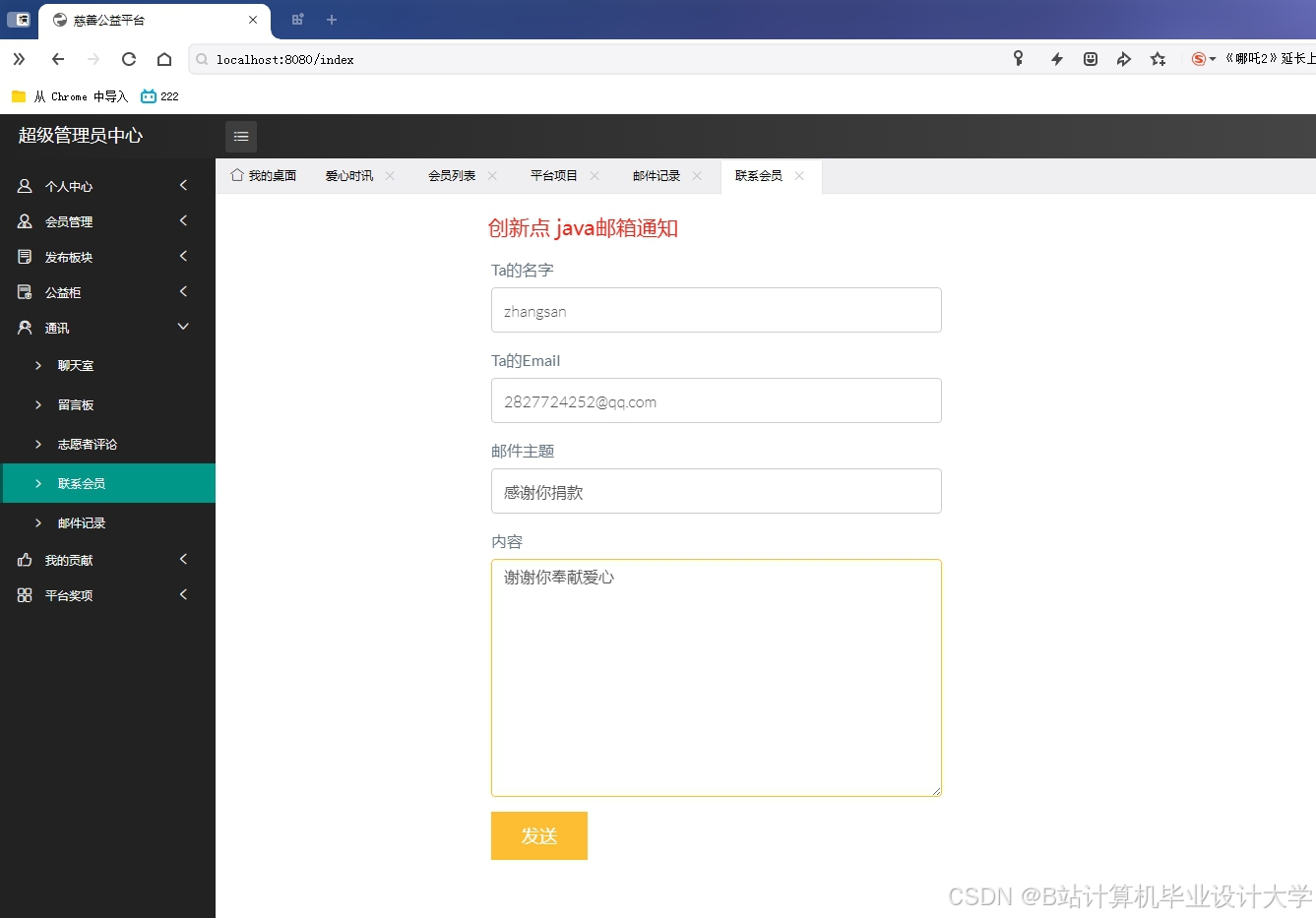
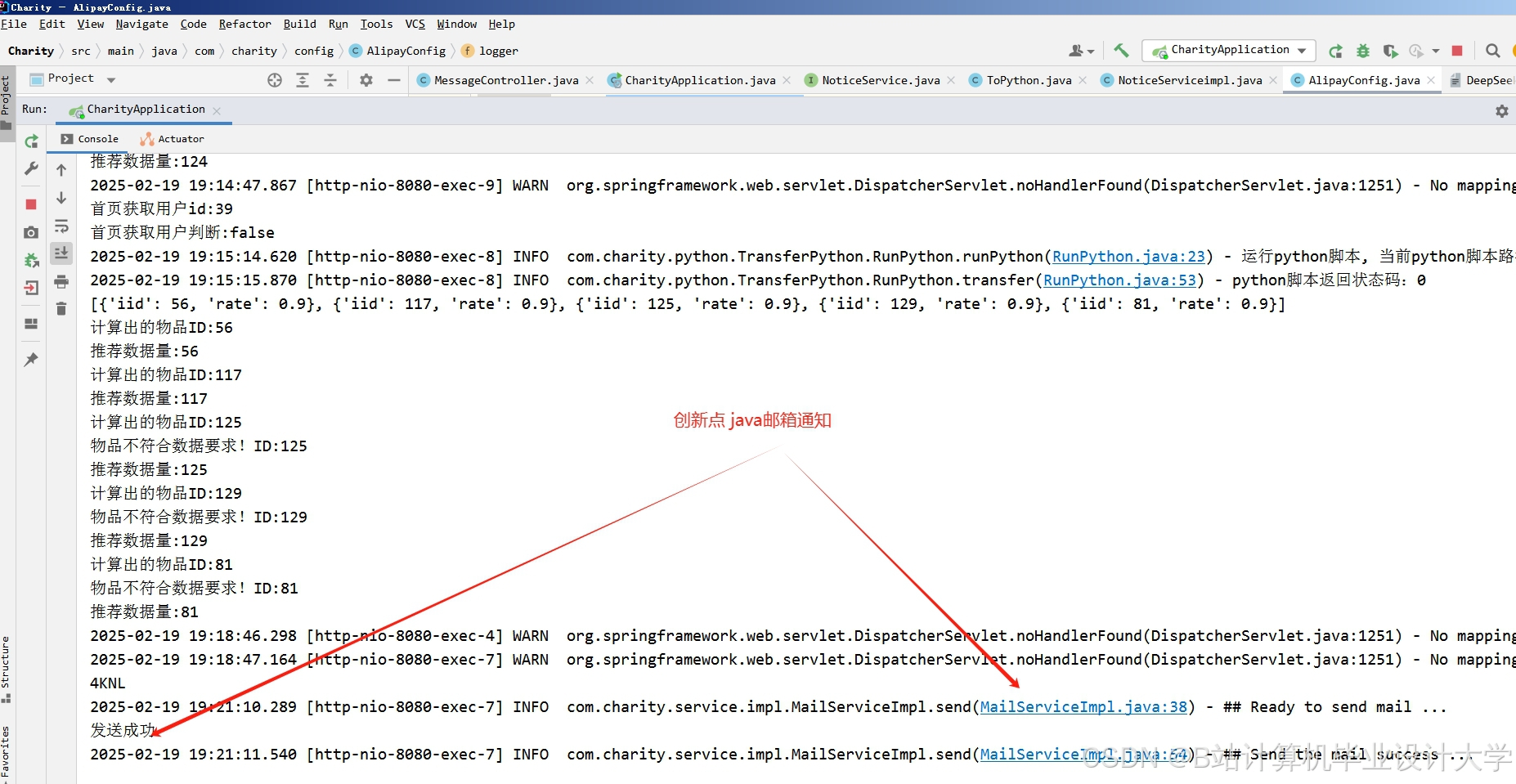
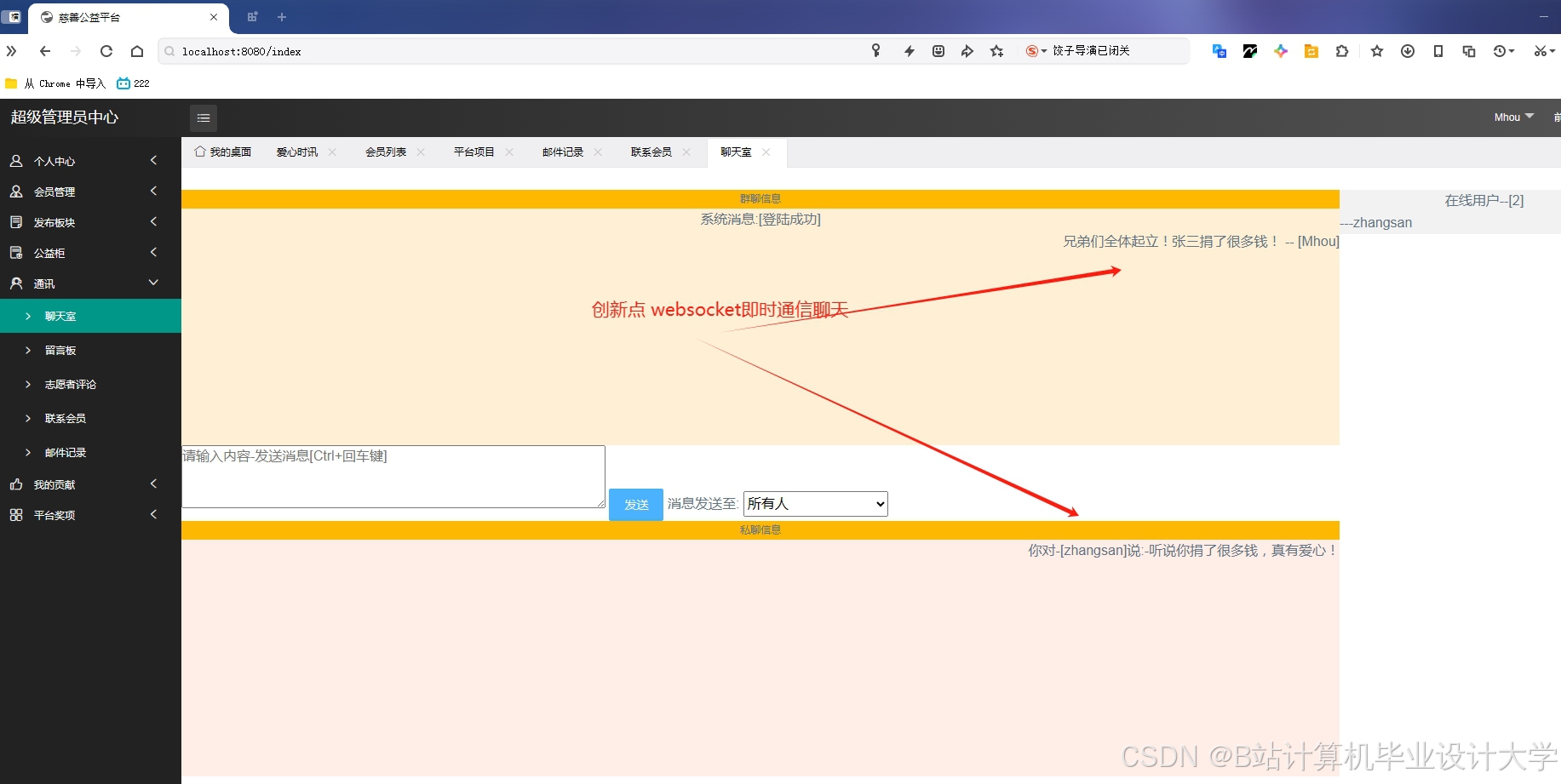
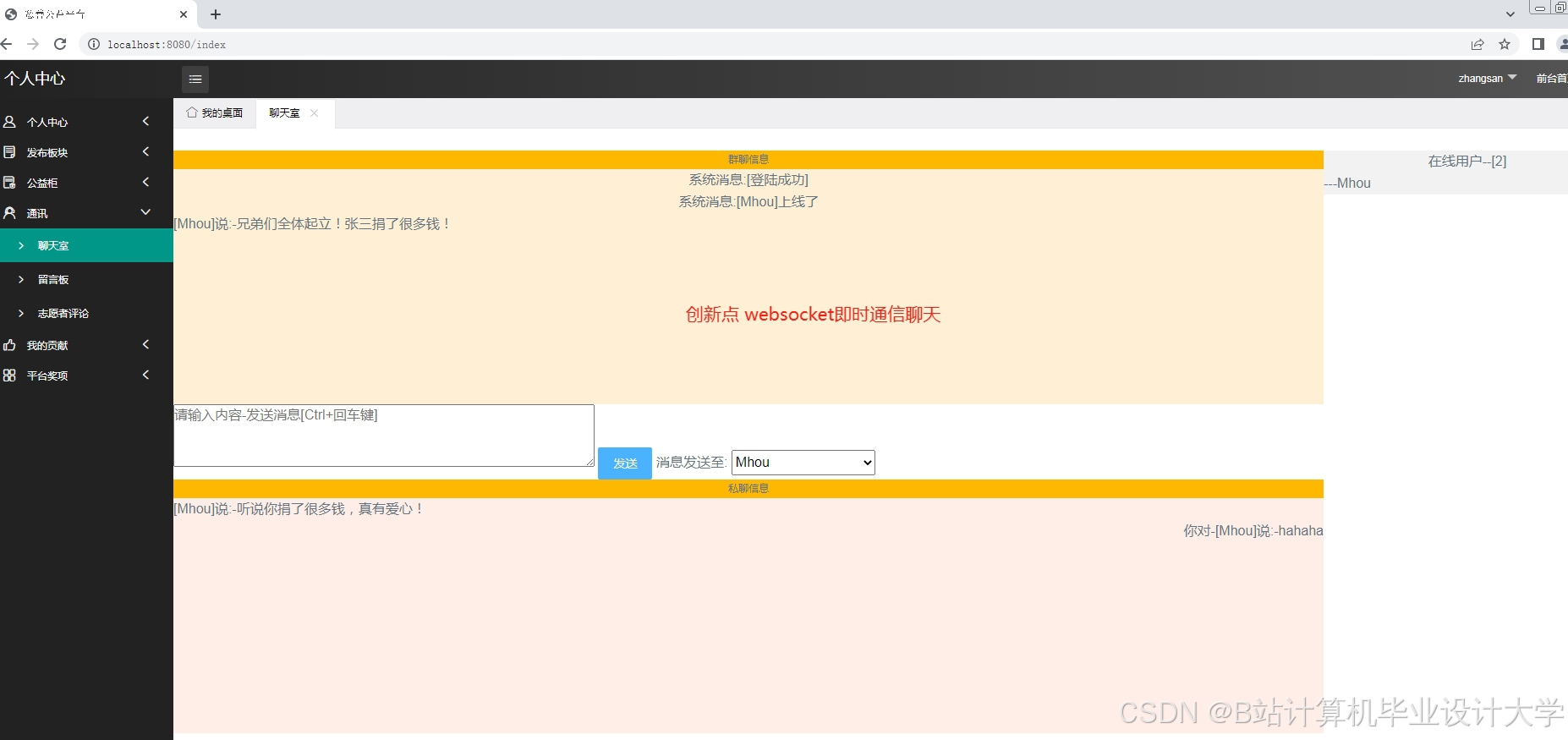


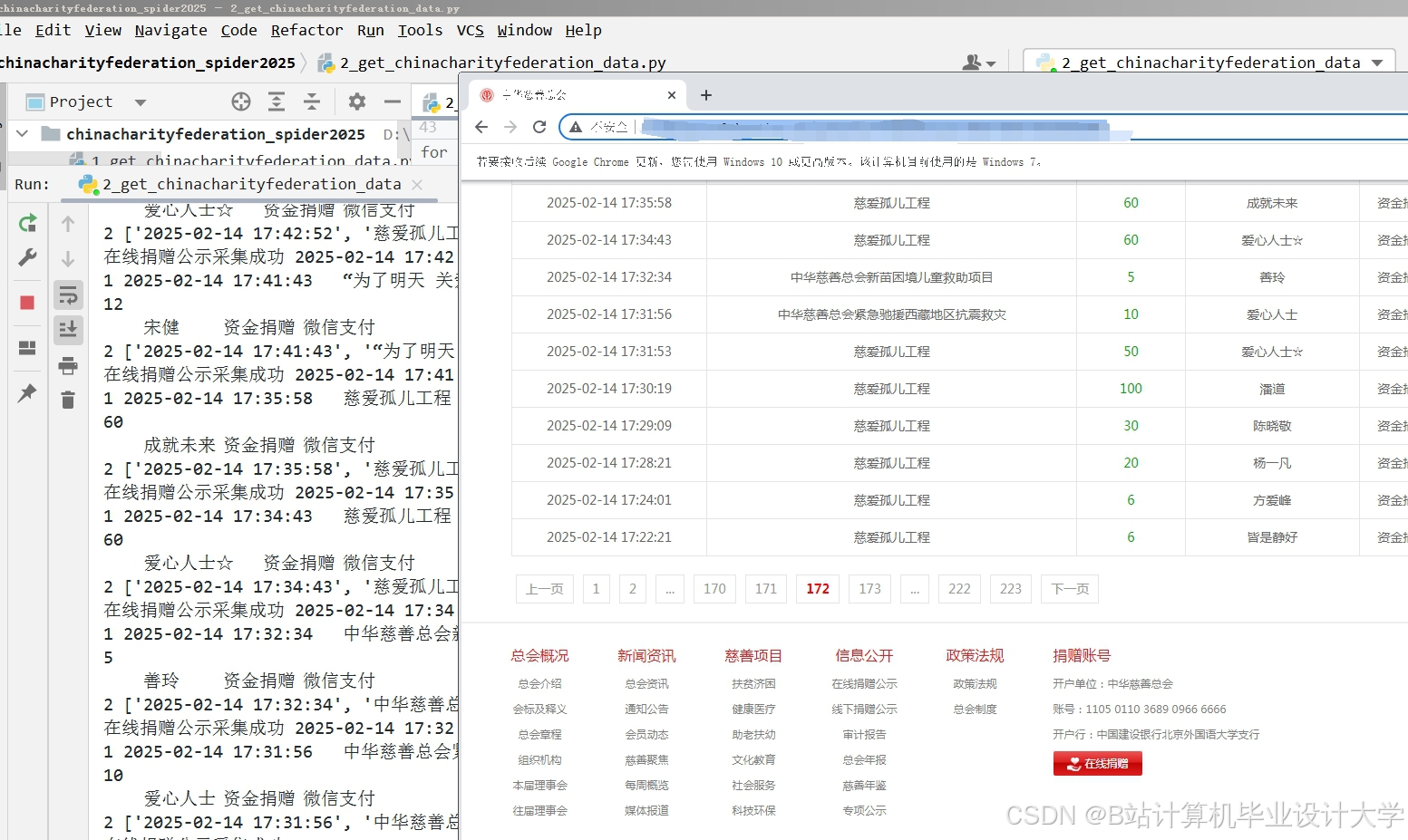
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献366条内容
已为社区贡献366条内容

所有评论(0)