0.2B 参数逆袭 GPT-4.1:组合推理的技术革命与评估范式重构
摘要:加州大学研究团队提出创新性GroupMatch指标和Test-Time Matching(TTM)算法,使小参数模型实现超越性表现。仅0.2B参数的SigLIP-B16在组合推理基准测试中超越GPT-4.1,GPT-4.1更首次在Winoground测试中突破人类水平。该研究揭示了传统AI评估体系的局限性,通过测试阶段优化挖掘模型潜在能力,为小模型逆袭大模型提供了新思路。TTM算法通过伪标签
0.2B 参数逆袭 GPT-4.1:组合推理的技术革命与评估范式重构
大家好,我是AI算法工程师七月,曾在华为、阿里任职,技术栈广泛,爱好广泛,喜欢摄影、羽毛球。目前个人在烟台有一家企业星瀚科技。
- 关注公众号:量子基态,获取最新观察、思考和文章推送。
- 关注知乎:量子基态,获取最新观察、思考和文章推送。
- 关注CSDN:量子基态,获取最新观察、思考和文章推送。
- 关注稀土掘金:量子基态,获取最新观察、思考和文章推送。
- 网站1 :七月
- 网站2:zerodesk
我会在这里分享关于 编程技术、独立开发、行业资讯,思考感悟 等内容。爱好交友,想加群滴滴我,wx:swk15688532358,交流分享
如果本文能给你提供启发或帮助,欢迎动动小手指,一键三连 (点赞、评论、转发),给我一些支持和鼓励,谢谢。
作者:七月 链接:http://www.xinghehuimeng.com.cn 来源:七月 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
传送门
博客链接:https://yinglunz.com/blogs/ttm.html
论文链接:https://arxiv.org/pdf/2510.07632
代码链接:https://github.com/yinglunz/tes
加州大学研究
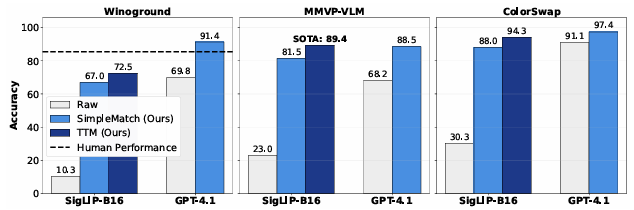
加州大学河滨分校 Yinglun Zhu 团队的研究如同一道惊雷:仅 0.2B 参数的 SigLIP-B16 模型,在 MMVP-VLM 组合推理基准测试中超越 GPT-4.1,GPT-4.1 更是在 Winoground 测试中首次实现对人类的超越。这一突破并非源于模型架构的颠覆性革新,而是直指 AI 评估体系的核心缺陷 —— 长期被忽视的 “指标偏见” 与 “测试阶段潜力解锁”。
添加图片注释,不超过 140 字(可选)
团队据此提出了新的GroupMatch指标,能够挖掘被现有评测掩盖的潜在能力,使GPT-4.1首次在Winoground基准测试上超越人类表现。
基于这一洞见,团队进一步提出一种无需外部监督、能够自我改进的迭代算法Test-Time Matching(TTM),可在模型推理阶段显著提升性能。
得益于TTM,仅0.2B参数的SigLIP-B16就在MMVP-VLM基准测试上超越了GPT-4.1,刷新了当前最优结果。
组合推理
组合推理是什么???
组合推理(compositional reasoning)是衡量 AI 智能水平的核心维度,它要求模型能够将对象、属性和关系重新组合,理解从未见过的新情境,本质上是 “举一反三” 的能力。在多模态场景中,这种能力尤为关键 —— 例如理解 “红色杯子在蓝色桌子上” 与 “蓝色杯子在红色桌子上” 的语义差异,并精准匹配对应图像。
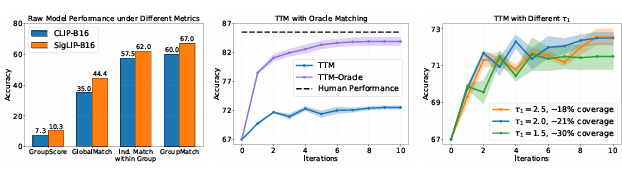
当前主流评测指标对AI模型的要求过于严苛,往往以“全对即得分”的二元标准评判结果,忽略了模型在语义关联和逻辑推导中的潜在理解能力。
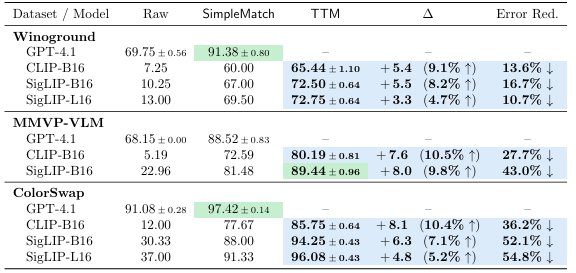
以经典的 Winoground 基准测试为例,该测试采用 2×2 群组设计:两组文本用词完全相同但顺序不同,每组文本仅对应一张图像,要求模型完成精准匹配。尽管 GPT-4V 等前沿模型在多模态任务中表现突出,但在该测试中此前的最佳得分仅为 58.75,远低于人类的 85.5 分。
添加图片注释,不超过 140 字(可选)
核心原因,在于传统评测指标的设计缺陷。广泛使用的 GroupScore 指标采用 “孤立成对验证” 逻辑:要求每张图像与每条文本必须精准匹配,只要出现一次错配,整组得分便判为 0。
GroupMatch
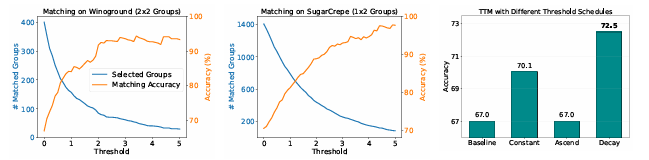
GroupMatch 的核心创新在于,不再逐一检查图像与文本的孤立匹配关系,而是考虑群组内所有可能的匹配组合(共 k! 种),选择全局一致性最优的匹配方案作为评估依据。
该方法不再要求AI输出与标准答案完全一致,而是通过分析多个候选答案之间的语义群组关系,判断模型是否达到了合理的推理层级。这种更具包容性的评估机制,能够识别出那些虽未精准命中但逻辑路径正确的回答,从而更公平地衡量AI的深层理解能力。
主要分为两步:
- 使用 GroupMatch 指标对模型的输出结果进行评估,筛选出全局一致性最优的匹配方案;
- 测试阶段过拟合:将筛选出的最优匹配作为目标,在测试阶段对模型进行针对性微调,使模型精准输出该匹配结果。
它没有改变模型的训练过程,而是通过 “评估引导优化” 的思路,让模型原本就具备的组合推理能力得以显现。
SimpleMatch 仅通过这两步简单操作,就让 0.2B 参数的 SigLIP-B16 模型在 Winoground 测试中超越了此前所有模型的表现,同时使 GPT-4.1 的得分突破人类水平阈值。
添加图片注释,不超过 140 字(可选)
Test-Time Matching(TTM)
这是一种不需要外部监督的方法,通过测试阶段的自我训练,放大模型的组合推理潜力,成为小模型逆袭大模型的关键推手。
TTM算法的本质其实就是融合子训练、半监督学习和主动学习的核心。主要通过三次迭代过程实现性能的持续提升。
- 模型对所有测试群组进行初步匹配预测,生成基础匹配结果
- 设定置信度阈值,仅保留得分差距超过阈值的高置信匹配结果作为 “伪标签”
- 基于伪标签对模型进行自我微调,提升模型在相似场景下的匹配精度;同时随着迭代次数增加,逐步放宽置信度阈值,将更多中等置信度的样本纳入训练范围,实现 “从易到难” 的渐进式学习
TTM的核心在于两点:
- 基于GroupMatch的伪标签能更有效地利用群组结构,提供更强的监督信号;
- 阈值的逐步衰减机制让模型先从高置信数据学习,再逐步扩展覆盖范围。
添加图片注释,不超过 140 字(可选)
从研究中的实验结果来看的话效果明显。
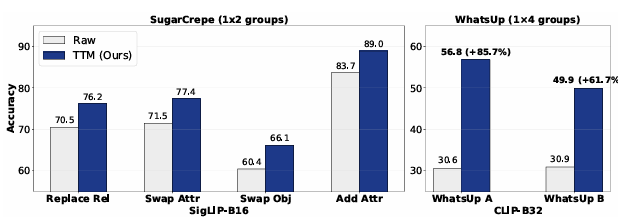
TTM 算法的相对性能提升最高可达 10.5%,相对错误率下降 54.8%
在 ColorSwap 数据集上让 SigLIP-L16 模型达到 GPT-4.1 的水平
在 MMVP-VLM 数据集上助力 SigLIP-B16(0.2B)超越 GPT-4.1,刷新了该基准的SOTA。
这些数字表明TTM算法的这个效果还是很不错的。
效果
研究人员在Winoground 测试:GPT-4.1 在 GroupMatch 指标与 SimpleMatch 方法的加持下,首次突破人类 85.5 分的基准线。
添加图片注释,不超过 140 字(可选)
他们对0.2B参数的SigLIP-B16进行TTM算法的优化,优化之后发现其性能超越了GPT4.1。
在多个其他的数据集上面。TTM的算法进行改进之后的性能都是提升的,并且WhatsUp的数据集的性能直接达到了85.7%。

添加图片注释,不超过 140 字(可选)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)