deepseek1.5B-模型训练(矩池云)
我一般是配置的这个环境加上开启 VNC(首先要下载 VNC软件),然后通过给出的 VNC 的账号密码打开VNC后进行连接,这时候点开桌面的终端Terminal,因为矩池云的网盘默认根目录是 /mnt,所以首先要 cd /mnt 到根目录下,然后可以 ls,查看是否显示刚刚上传的 deepseek_train 文件夹,有的话就 cd 进入,没有那就要排查一下原因了。顺便说一下,在终端的时候如果文件有
目录
由于苯人已经开始实习,所以专门开个专栏来记录一下实习工作,今天上午进行了如题的训练,下面开始(顺便说一下,这是苯人第一次进行脚本式的模型训练,过程可能会很简陋,且苯人是在矩池云上进行训练的):
一、训练数据准备
负责人给到我的原始数据集是Excel形式,且没有表头,需要转换为大模型训练所需的json格式,处理代码如下:
import pandas as pd
import json
df = pd.read_excel("QW.xlsx", header=None) #没有表头
df.columns = ["question", "answer"] #所以手动设置列名
# 去掉空值
df = df.dropna(subset=["question", "answer"])
with open("QW.json", "w", encoding="utf-8") as f:
for _, row in df.iterrows():
record = {
#去掉首尾空格
"instruction": "你是一个生产数据分析助手,请根据生产数据回答以下问题:", #模型角色
"input": str(row["question"]).strip(), #用户输入
"output": str(row["answer"]).strip() #期望输出
}
f.write(json.dumps(record, ensure_ascii=False) + "\n")
# ensure_ascii :允许保存中文
print("已生成QW.json,样例:")
print(open("QW.json", "r", encoding="utf-8").readline())
运行后会生成 QW.json ,每行数据长这样:
{"instruction": "你是一个生产数据分析助手,请根据生产数据回答以下问题:", "input": "最近90天重庆生产汇报/扭力梁/C65的平均出勤人数是多少?", "output": "最近90天,重庆生产汇报中关于扭力梁/C65项目的平均出勤人数为4.03人。"}
二、模型训练
由于我是CPU,所以我写的脚本最终要在矩池云上运行,训练的流程我大概总结了:
设备检查 -> 加载模型和 tokenizer -> 配置 lora 参数 -> 加载数据集 -> 数据预处理(包括批处理) ->配置训练参数(顺便加上 trainer) -> 开始训练 -> 保存模型(在trainer里实现了)
1、设备检查
def train():
try:
# 检查设备
device = "cuda" if torch.cuda.is_available() else "cpu"2、加载模型和 tokenizer
# 加载模型和tokenizer
# model_path = "./deepseek-1.5B" #上传到矩池云用这个
model_path = "../deepseek-1.5B"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token #添加结束符
# 配置模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
device_map="auto",
trust_remote_code=True
)注意 model_path 这里,我本来的基础模型在项目文件夹的根目录,但是上传到矩池云的话就一个 project 目录,所以要注意目录层级
3、配置 LoRA
# 配置LoRA
lora_config = LoraConfig(
r=8, # 低秩维度
lora_alpha=16,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"], #针对transformer block
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()4、加载数据集
# 加载数据集
dataset = load_dataset('json', data_files='QW.json') # hf的dataset库
train_dataset = dataset['train'] #只提供一个数据集时默认全部作为训练集
# 或者加载时分割
# dataset = load_dataset('json', data_files='QW.json', split='train[:80%]')
print(f"训练数据集数: {len(train_dataset)}")这里我们只有一个数据集
5、数据预处理(加入数据批处理)
# 数据预处理
def preprocess_function(examples):
texts = []
for i in range(len(examples['instruction'])):
#构建训练文本格式
text = (
f"### Instruction:\n{examples['instruction'][i]}\n\n"
f"### Input:\n{examples['input'][i]}\n\n"
f"### Response:\n{examples['output'][i]}{tokenizer.eos_token}" #tokenizer.eos_token是结束标记
)
texts.append(text)
return tokenizer( #把文本变为 token 向量
texts,
truncation=True, #超过长度就截断
max_length=768, #最大输出
padding="max_length", #统一填充
return_tensors="pt" #返回张量
)
print("开始预处理数据...")
tokenized_dataset = train_dataset.map( #将整个预处理应用到完整数据集
preprocess_function,
batched=True, #批量处理
remove_columns=train_dataset.column_names #移除原始列,只保留tokenized后的数据
)这里我们进行数据处理是为了将原始的 json 数据转换成模型能直接学习的训练文本,并用 tokenizer 转为 token 向量,最终喂给模型训练,用一句话总结这个流程的话就是:
原始数据 → 拼成模型格式的训练句子 → tokenizer 转 token → batch 整理 → 送入 Trainer
还有一段数据批处理:
# 数据批处理
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
)就是负责的把单条 token 化后的数据打包成统一长度的 batch、自动生成 labels、自动处理 padding和 mask、为 GPT类模型提供“下一个token”,就像一个小管家一样负责整理数据、打包数据、确保格式正确
6、配置训练参数(加入Trainer)
# 训练参数
training_args = TrainingArguments(
output_dir="../deepseek-1.5b-lora", # 模型保存目录
# output_dir="./deepseek-1.5b-lora", # 模型保存目录
num_train_epochs=3, # 训练3轮
per_device_train_batch_size=2, # 批大小
gradient_accumulation_steps=4, # 累积4步,有效批大小=4
learning_rate=1e-4,
fp16=True, # GPU上使用半精度训练
#以下在上传矩池云时添加
logging_steps=10,
save_strategy="epoch",
warmup_steps=100, # 添加热身步骤
save_total_limit=2, # 只保存最后2个检查点
dataloader_pin_memory=False, # 避免内存问题
)这里就是配置训练的具体参数,每个参数怎么选可以参考:
-
output_dir:模型/检查点保存位置。路径别错就好。 -
num_train_epochs:一般 2–5 轮。看数据量、loss 曲线和过拟合风险。 -
per_device_train_batch_size:受显存限制,能大就大。 -
gradient_accumulation_steps:模拟大 batch。有效 batch=per_device * 累积 * GPU数。 -
learning_rate:LoRA 常见1e-4 ~ 3e-4;若发现不稳定/发散,先降到5e-5 ~ 1e-4。 -
fp16/bf16:如果 GPU 支持 bfloat16(如 A100、H100),可用bf16=True更稳;否则fp16=True。 -
logging_steps:日志频率。太小会频繁打印,太大看不到趋势。 -
save_strategy:"epoch"简单、占空间少;要更细粒度可用"steps"搭配save_steps。 -
warmup_steps:建议按数据规模改成“比例”更方便,比如warmup_ratio=0.03。 -
save_total_limit:控制磁盘占用。 -
dataloader_pin_memory:有些云平台开了反而不稳,这里关闭是求稳做法。
接下来是 Trainer:
# Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=data_collator,
)Trainer 其实是 HuggingFace Transformers 提供的 训练管理器(Training Manager),背后的逻辑其实就相当于:
for epoch in range(num_epochs):
for step, batch in enumerate(dataloader):
outputs = model(**batch)
loss = outputs.loss
loss.backward()
if step % gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
save_checkpoint() # save_strategy="epoch"
可以理解为:

并且还做了很多“增强功能”,比如梯度裁剪、日志记录、checkpoint清理等等,它就相当于大模型训练的全自动驾驶系统,只要给它方向(参数)、燃料(数据)、车(模型),它就负责跑完全程。
7、开始训练
# 开始训练
print("开始训练...")
trainer.train()
print("训练完成!模型保存成功")直接调用就可以了,上面也说过 trainer 里已经自动保存了模型,只需要加入最后一行输出就可以确定是否是训练完了,当然可以再加一个错误显示:
#添加错误显示和进度处理
except Exception as e:
print(f"训练出错: {e}")
import traceback
traceback.print_exc()这样训练脚本基本就写完了,接下来就可以去矩池云租算力,也就是开始烧钱了(〒︿〒)
三、矩池云
矩池云这个平台我就不介绍了,就是一个租 GPU 的平台,这里我记录一下整个流程(因为苯人当时训练时没有截图对应的终端,只能文字描述了,图片也只能放本地的):
1、上传整个项目文件夹
上传到矩池云网盘的代码需要包含以下几个文件:
原始模型:
数据集:
训练脚本: (注意要改成英文名,因为矩池云终端识别不了中文,我这里是本地文件,可以在矩池云网盘上传后再重命名,比如 model_train.py)
(注意要改成英文名,因为矩池云终端识别不了中文,我这里是本地文件,可以在矩池云网盘上传后再重命名,比如 model_train.py)
将这整个文件夹命名为 deepseek_train 然后上传到矩池云网盘
2、开始训练
首先租用一张显卡,注意一定要是上传文件夹的那个区:
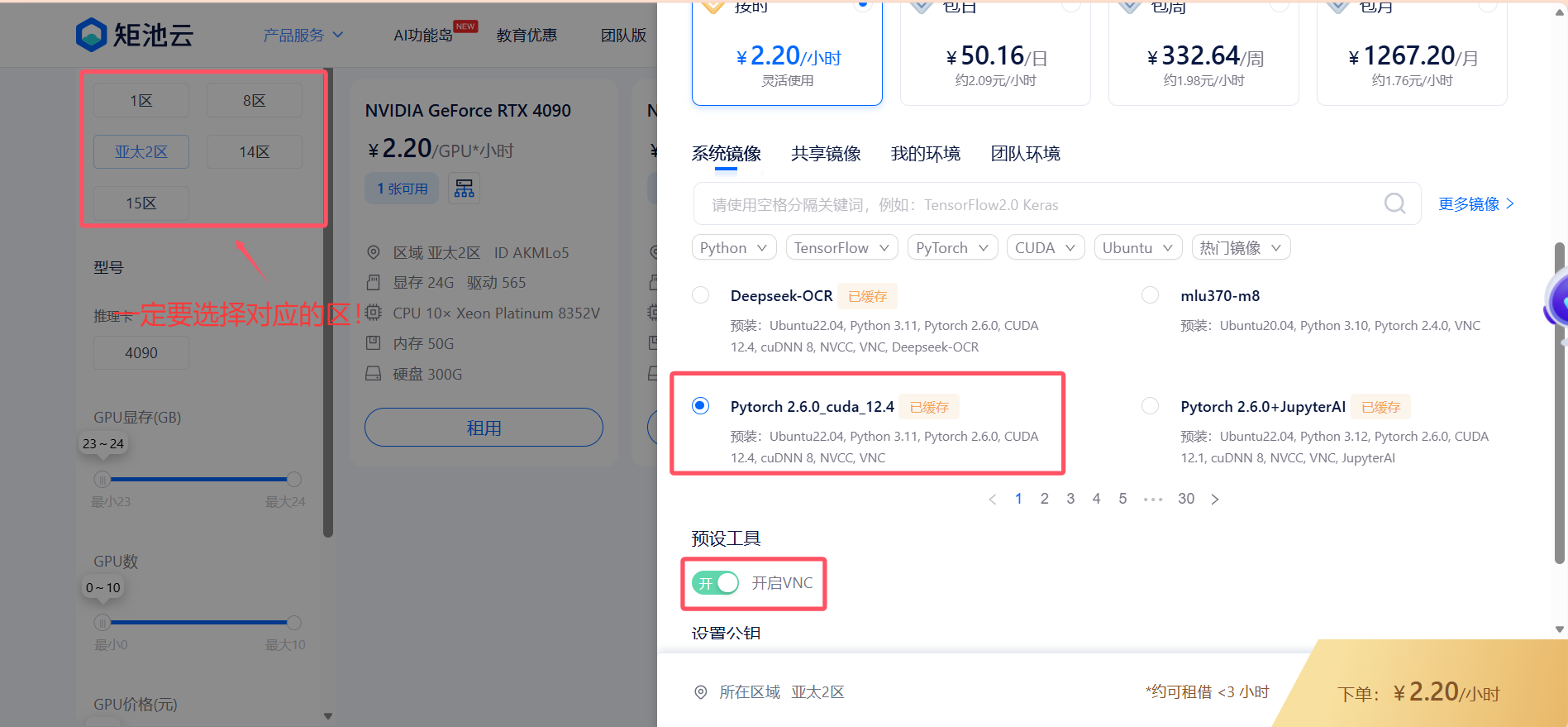
我一般是配置的这个环境加上开启 VNC(首先要下载 VNC软件),然后通过给出的 VNC 的账号密码打开VNC后进行连接,这时候点开桌面的终端Terminal,因为矩池云的网盘默认根目录是 /mnt,所以首先要 cd /mnt 到根目录下,然后可以 ls,查看是否显示刚刚上传的 deepseek_train 文件夹,有的话就 cd 进入,没有那就要排查一下原因了
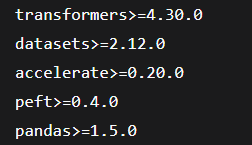
进入项目文件夹后把依赖包安装好,好像有 transformers、datasets、accelerate、peft、pandas这些,torch 不需要因为我们选择的环境里已经有了,参考版本:
然后直接运行 python model_train.py,就开始训练了,还好训练的图我截了:
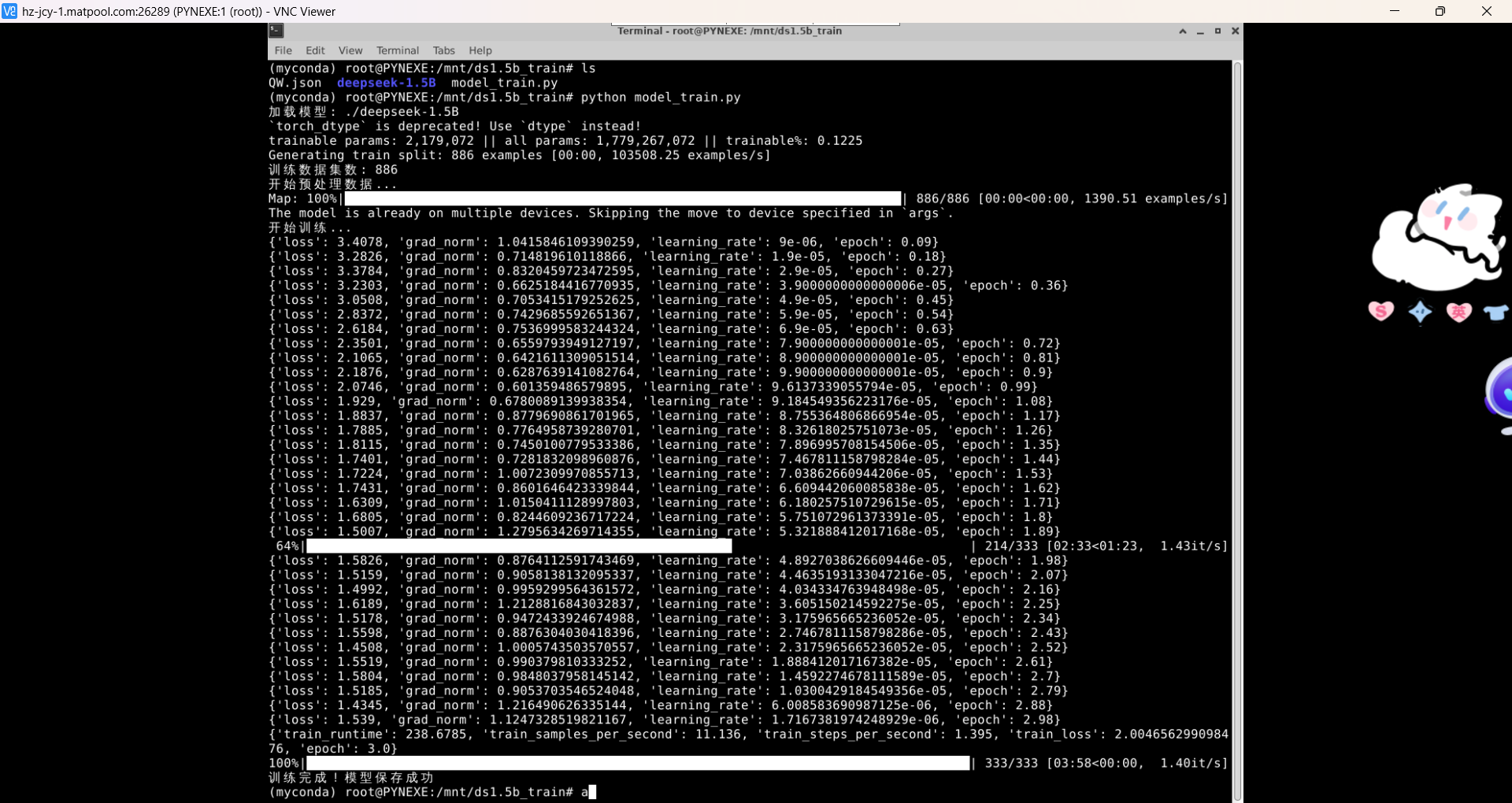
训练完后看到保存了检查点就说明模型保存成功了:
![]()
这里的333其实表示的是训练步数,我这里的333是因为首先 epoch=3,batch_size=2,梯度累计步数=4,首先每轮的步数是 886/(2*4)=111,然后有3轮所以 111*3=333步,我又设置的只保存最后一轮检查点的模型参数,所以就是这个文件夹了,然后不带一秒犹豫地停止租用并退出(´▽`)ノ
顺便说一下,在终端的时候如果文件有任何问题都是可以修改的,可以直接在外部把有问题的文件删除然后再重新上传(建议下载一个矩池云网盘);也可以直接打开 jupyternotebook,就在复制VNC账号密码的地方,与VNC一排的有 jupyternotebook,下面有一个“点击打开”,然后就会弹出网页了,同样在这上面也可以增删改查文件。
三、模型测试
将矩池云上保存的模型下载到本地后就可以在本地进行模型测试了,写一个测试文件:
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
import torch
# 加载微调模型和基础模型
model_path = "../ds1.5b_lora-checkpoint-333" # 微调权重路径
base_model = "../deepseek-1.5B" # 基础模型路径
# 模型配置(加载基础模型的分词器-> 加载原始模型-> 将lora适配器加载到基础模型上)
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(base_model)
model = PeftModel.from_pretrained(model, model_path) #PeftModel:加载适配器
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
# 测试输入文本 按照训练的格式
test_text = "### Instruction:\n最近90天完成率的趋势如何?\n\n### Response:\n"
# 转换输入
inputs = tokenizer(test_text, return_tensors="pt").to(device)
# 生成输出
outputs = model.generate(
**inputs, #输入token
max_length=512,
temperature=0.7, #控制随机性
pad_token_id=tokenizer.eos_token_id # 设置结束符
)
# 解码并输出生成结果
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
测试流程大概是:
加载原始模型及微调模型 -> 模型配置 (加载基础模型的分词器 -> 加载原始模型 -> 将lora适配器加载到基础模型上 -> )-> 输入测试文本转换输入,生成输出并解码
运行结果我就不贴了(因为苯人没截图,且已经把原始模型删了),反正肯定能回答出来,只是精准度的问题
以上就是这篇,其实下一个任务是训练 qwen1.5b,负责人告诉我他们通过官方的方法微调了一个,我就想在 LlaMA-Factory 上微调一个试试,结果这一试试出了好多问题。。本来下一篇我想写这个的,根本写不出来。。最终还是脚本训练的,虽然训练的结果还可以因为我是全参数微调,但是基本逻辑跟这篇差不多了,我始终认为应该是数据集的配置 dataset_info.json 有问题,跟数据集格式就是一直没对齐 (ー̀дー́),等我下次准备好了再试一次
以上有问题可以指出 (๑•̀ㅂ•́)و✧

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)