Prompt → Fine-tune → RAG → Agent:我踩过的坑,值 300 万!
在 2025 年,大语言模型(LLM)的应用方式已经从单一的“问答”演进到多种成熟范式。每一种范式都在特定场景下展现出独特优势,也伴随着不可忽视的代价理解 Prompt Engineering、Fine-Tuning、RAG(Retrieval-Augmented Generation)和完整 AI Agent 之间的本质差异,已成为每一个 AI 实践者的必修课。Prompt Engineerin
在 2025 年,大语言模型(LLM)的应用方式已经从单一的“问答”演进到多种成熟范式。每一种范式都在特定场景下展现出独特优势,也伴随着不可忽视的代价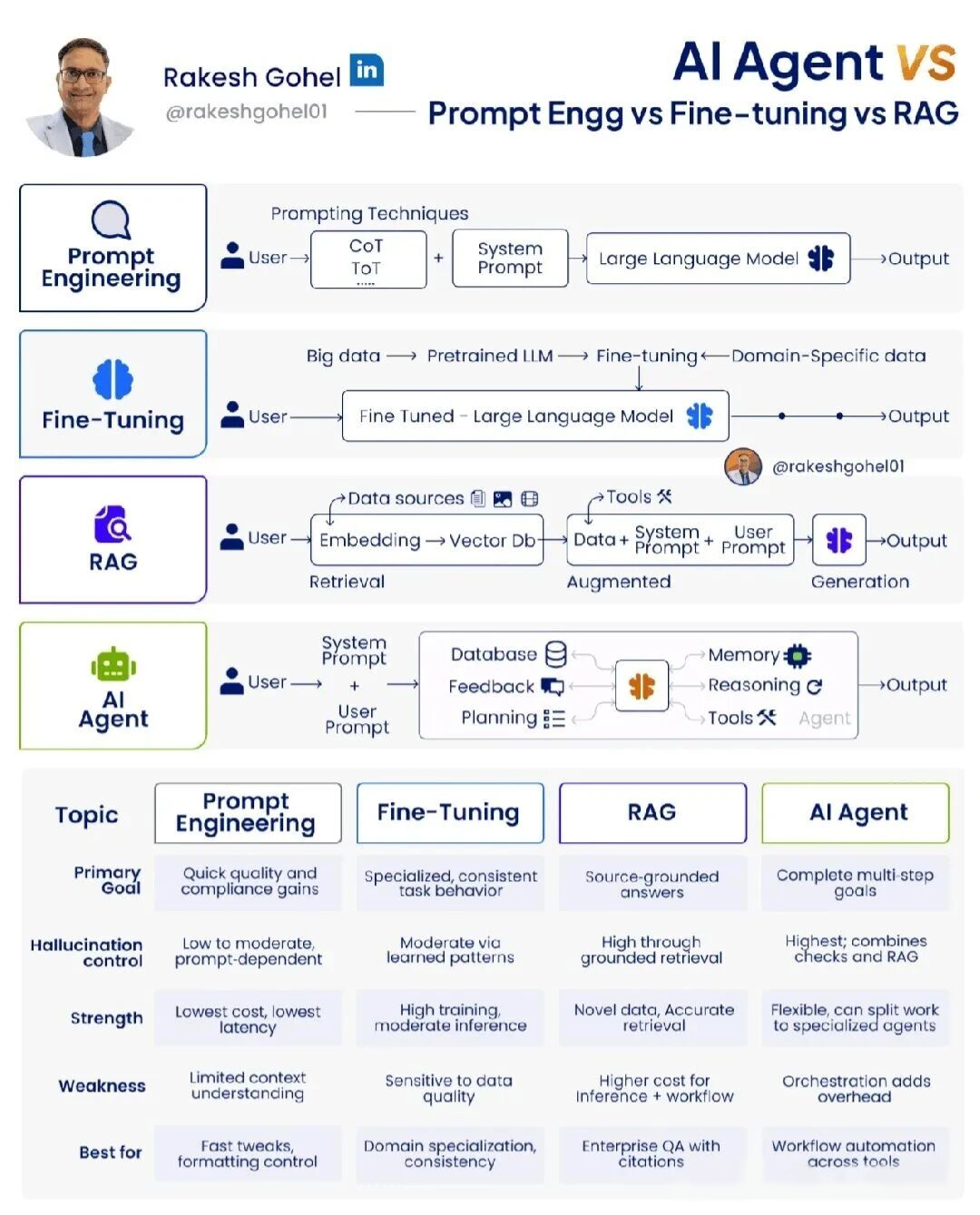
理解 Prompt Engineering、Fine-Tuning、RAG(Retrieval-Augmented Generation)和完整 AI Agent 之间的本质差异,已成为每一个 AI 实践者的必修课。
Prompt Engineering
Prompt Engineering 本质上是“用文字编程”。通过精心设计的 System Prompt、Chain-of-Thought(CoT)、Tree-of-Thought(ToT)、ReAct 等提示技巧,我们可以在零训练成本下让通用大模型表现出惊人的能力。
优势
-
成本最低、延迟最低:无需额外训练,直接调用 API 即可。
-
快速迭代:改几行 prompt 就能看到效果,适合格式化控制、快速实验。
-
兼容所有模型:不管是 Grok 4、Claude 3.5 还是 GPT-4o,只要支持系统提示即可。
局限
-
上下文窗口限制:所有知识必须塞进 prompt,超过 128k 就无能为力。
-
幻觉难根治:模型仍会根据训练数据“编造”答案,效果高度 prompt 依赖。
-
可扩展性差:企业级知识库动辄百万文档,根本塞不进 prompt。
适用场景:内部工具快速原型、内容生成格式化控制、个人效率工具的“fast tweaks”。
Fine-Tuning
Fine-Tuning 通过在领域特定数据上继续预训练或指令微调(Instruction Tuning),让模型从“懂常识”进化到“懂行话”。
优势
-
行为高度一致:同样的输入,99% 的情况下都会按预期输出。
-
减少幻觉:在训练数据覆盖的领域内,模型学会了“不会就说不会”。
-
支持复杂任务:法律文书生成、医疗报告撰写等需要深度领域知识的场景。
代价
-
训练成本高昂:即使是 QLoRA 也需要数万条高质量样本 + 数十小时 A100 时间。
-
数据敏感:训练数据一旦泄露或带有偏见,模型将永久记住。
-
更新困难:知识库更新后需要重新微调,难以做到实时。
适用场景:对一致性和专业性要求极高的垂直领域(如金融风控、医药研发)。
RAG(检索增强生成)
RAG(Retrieval-Augmented Generation)通过向量数据库 + 检索,让模型在生成前先“查资料”,从根本上解决了知识时效性和幻觉问题。
核心流程
用户问题 → Embedding → 向量数据库检索 Top-K 片段 → 注入提示 → LLM 生成 → 输出
优势
-
答案有源可溯:每句话都能对应到具体文档段落,企业合规必备。
-
知识永不过期:文档更新后无需重新训练,检索即更新。
-
成本可控:只需维护向量数据库,推理成本与原生 LLM 几乎一致。
挑战
-
检索质量决定上限:垃圾检索 = 垃圾答案。
-
复杂推理仍需 LLM:RAG 只解决“知道什么”,不解决“怎么思考”。
-
工作流干扰成本:多了一次向量检索 + 上下文拼接,延迟通常增加 200-800ms。
适用场景:企业级问答系统、内部知识库、法规查询、带引文的学术助手。
AI Agent
真正的 AI Agent 已经不再是“增强生成”,而是一个完整的自主循环系统:
System Prompt + User Prompt
↓
Planning(规划) → Tool Calling(调用工具)
↓
Memory(短期 + 长期记忆)
↓
Reasoning(多步推理) → Feedback(自检)
↓
最终 Output
代表框架
-
LangChain / LlamaIndex 的 Agent
-
AutoGPT、BabyAGI 系列
-
Microsoft AutoGen、OpenAI Swarm
-
xAI Grok 4 的原生 Agent 模式
优势
-
完整多步目标:可以拆解任务、调用十几个工具、自我纠错。
-
工具生态融合:浏览器、代码解释器、数据库、邮件、日历、API 全都可调用。
-
可组合性:一个 Agent 解决不了?拆成 10 个子 Agent 协作。
代价
-
最高复杂度和延迟:每一步 Tool Call 都可能耗时数秒。
-
可观测性挑战:黑盒中的黑盒,调试如同大海捞针。
-
成本失控风险:一个复杂任务可能触发 50 次 LLM 调用。
适用场景:工作流自动化(报销审批全流程)、个人全能助理、复杂研究任务(文献调研 + 数据分析 + 报告撰写)。
五大维度终极对比表
|
维度 |
Prompt Engineering |
Fine-Tuning |
RAG |
AI Agent |
|---|---|---|---|---|
| 主要目标 |
快速合规输出 |
专业一致性 |
有源可溯答案 |
完整多步闭环任务 |
| 幻觉控制 |
低-中(prompt 依赖) |
中(学到的模式) |
高(检索 grounding) |
最高(检索 + 自检) |
| 成本结构 |
最低 |
高训练+中推理 |
中(向量 DB+推理) |
最高(多轮调用) |
| 知识更新难度 |
不可能 |
极高(重训练) |
极低(更新文档) |
低(记忆+检索) |
| 适用场景 |
格式化快调 |
垂直领域深度 |
企业知识库查询 |
跨工具工作流自动化 |
最佳实践
聪明的团队早已不再“选边站”,而是分层叠加:
-
底层:Grok 4 / Claude 3.5 Sonnet 作为基座模型
-
知识层:RAG(企业级向量数据库 + HyDE + Parent Document)
-
行为层:Fine-Tuning(关键垂直任务,如法律条款生成)
-
执行层:Agent 框架(AutoGen + 自定义 Tools)
-
兜底层:Prompt Engineering(CoT + ReAct + Self-Consistency)
这种“Agent + RAG + Fine-Tuned Specialist”的组合,已经在多家 Fortune 500 公司内部落地,单人效率提升 6-12 倍。
总结
没有哪种技术会彻底淘汰其他,而是场景决定武器:
-
需要 3 秒出答案、格式完美 → Prompt Engineering
-
需要 99.9% 专业一致性 → Fine-Tuning
-
需要答案带原文出处、永不过期 → RAG
-
需要从 0 到 1 完成整件复杂事务 → AI Agent
2025 年的 AI 工程师,不再是“prompt 调教师”,而是系统架构师:懂得在正确的时间、正确的层级,使用正确的武器。
接下来,我也为读者朋友们准备了一份 “完整版” 大模型资源,里面包含了论文、书籍、面试题、项目源码和课程等。如果你想快速学会大模型,只需在GONGZHONGHAO【小灰熊大模型】后台对我发出接头暗号:【111】 ,我就会把完整资料包发送给你。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 23
23 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)