告别脏数据!大模型数据清洗实战,从0到1,效率提升100倍!(附代码)
最近,团队小伙伴在一台带 4 \* RTX 2080 TI 显卡的服务器上,用 Ollma 部署了 QWQ 32b。正好,这两天需要把数据库里,一张表的某个字段内容给翻译整理一下,因为原始数据的内容实在是太乱了,完全不能看。
最近,团队小伙伴在一台带 4 * RTX 2080 TI 显卡的服务器上,用 Ollma 部署了 QWQ 32b。
正好,这两天需要把数据库里,一张表的某个字段内容给翻译整理一下,因为原始数据的内容实在是太乱了,完全不能看。
具体什么内容呢,来瞅一眼:
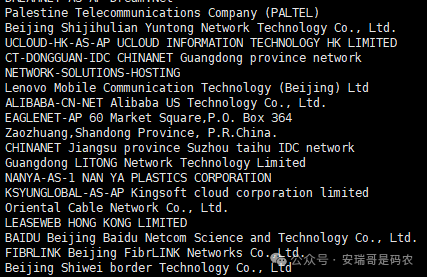
这是一个「网络运营商」字段,里面记录了全世界各地、各种稀奇古怪、牛鬼蛇神的、听都没听过的网络运营商名字,如果不翻译,完全看不懂。
0. 要解决的问题
目前这个数据字段存在的问题是:
1,内容格式不统一,同一个运营商,在英文表达上可能都不一样(用不同的单词,但意思一样,有的简写,有的用全称);
2,大小写没有统一,有的全部大小,有的全部小写,有的大小写随心所欲;
而这种情况,我觉得用「见多识广」的大模型,来把它们翻译成一个统一的名字再合适不过了。
一来,可以帮我完成这个数据处理的「脏活」;二来,也可以检验一下这个 qwq 模型的翻译水平。
1. 获取模型 API
老实说,我是第一次用 API 的方式来使用本地部署的大模型,具体怎么玩,一开始心里是没谱的。
不怕,可以问它自家在线的 Qwen 就好了
喂给它相关的提示词后,很快,它就给了我一个比较满意的 Java API(毕竟这个很简单)。
当然,对于它给出的回答,还需要额外根据具体要求进行微调。
比如,因为当前本地部署的这个 qwq 是思考模型,默认它会把整个过程也做输出。
而我不需要这部分内容,所以需要在代码里,把这部分给剔除掉:
// 构建JSON请求体,指定使用qwq模型 String jsonBody = "{ \"prompt\": \"" + prompt + "\", \"model\": \"qwq\"}"; // 创建HttpClient实例 CloseableHttpClient httpClient = HttpClients.createDefault(); // 创建POST请求 HttpPost post = new HttpPost(OLLAMA_URL); post.setHeader("Content-Type", "application/json"); // 设置请求体 StringEntity entity = new StringEntity(jsonBody, "UTF-8"); post.setEntity(entity); // 发送请求并获取响应 HttpResponse response = httpClient.execute(post); // 检查响应状态码 int statusCode = response.getStatusLine().getStatusCode(); if (statusCode == 200) { // 读取响应内容(流式输出) StringBuilder fullResponse = new StringBuilder(); BufferedReader reader = new BufferedReader(new InputStreamReader(response.getEntity().getContent(), "UTF-8")); String line; boolean inThinkTag = true; while ((line = reader.readLine()) != null) { // 解析每一行JSON //System.out.println("Raw Response: " + line); // 打印原始响应(调试用) String eachResponse = JSON.parseObject(line).getString("response"); if (eachResponse.equals("</think>")){/**去掉think的过程*/ inThinkTag = false; } if (!inThinkTag && !eachResponse.equals("</think>")) fullResponse.append(eachResponse); //System.out.println(eachResponse); } return fullResponse.toString(); } else { return "Error:" + statusCode; }
不解释了,都在代码里头。
2. 跑起来还要调
别以为 API 写好就万事大吉,实际跑起来后,发现没那么简单。
一开始,我给它翻译字段内容的 prompt 是这样的:
String prompt = String.format("把这个数据库字段的内容,翻译成标准的中文内容: %s", operatorName);
比如,当这个网络运营商的名字叫下面这个时:

虽然上面 API 已经把思考过程给剔除了,但它会在输出时,默认给出类似下面这样一堆解析过程,真是防不胜防。

所以怎么办呢?
调整1:优化 prompt
改成下面这样后,那堆罗里吧嗦的内容就没有了,能直接输出结果:
String prompt = String.format("把这个数据库字段(网络运营商)的英文内容,全部翻译成标准的中文内容,不要思考过程,不要解析过程,只要最终结果,且结果要包含国家和省份名称: %s", operatorName);
但,依然有个小细节需要注意,那就是输出后的内容,虽然去掉了所有我不想看到的内容,但输出的内容是这样的:

所以还得调。
调整2:优化 API
把输出从之前的这个:

调整成这个:

继续观察翻译的结果,又发现了异样。
比如这个:

又比如这个:

明明内容一毛一样,但一前一后的翻译,居然都可以缺斤少两。
咋整呢?又不能用交互的方式纠正它。
调整3:将字段值去重
很简单,在用 SQL 取这张表的这个字段时,加上 distinct 关键字,
select distinct(as_operator) from table where as_operator !="" and as_operator_chinese =""
这样取出来的值,就不会重复了。
最后,通过下面这种方式,把翻译后的内容,给更新到表里:
PreparedStatement ps = conn.prepareStatement("ALTER TABLE table UPDATE `as_operator_chinese` = ? where `as_operator` = ?");ps.setString(1, operatorChinese);ps.setString(2, operatorName);ps.executeUpdate();
最后
利用 qwq 本地部署的 API,根据以上这些步骤跟调整,最终把这张有着几十万杂乱网络运营商记录的表,给全部翻译成了可用的值。
最终入库后的结果长这样:

看着确实还挺像那么回事的,虽然谈不上完美,但基本符合预期。
这是一个典型的,难度不大,但如果纯人工来解决,就要费时费力又恶心的活,把它交给 AI,也许是当下最好的解决方案之一。
但这种通过调用大模型接口解决问题的玩法,最大的缺点——比较慢!
核心原因在于,模型在执行每一次翻译的时候,需要花时间思考,另外,跟部署这台服务器的硬件资源也应该有一定关系。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。

RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。 
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。

模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。 
顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调 
大厂绿色直通车,冲击行业高薪岗位

文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献286条内容
已为社区贡献286条内容

所有评论(0)