手撕6大深度强化学习算法(DDPG PPO TRPO SAC TD3 MADDPG):原理+代码+实战
本文系统介绍了六种主流深度强化学习算法的原理与应用。DDPG适用于连续动作空间控制,PPO实现简单且性能稳定,TRPO理论严谨但实现复杂,SAC具有良好探索能力,TD3是DDPG的改进版本,MADDPG则专为多智能体系统设计。文章通过Pendulum-v1环境对比了这些算法的性能,提供了完整的代码实现和训练流程。结果表明,PPO和SAC通常表现最优,而TD3比DDPG更稳定。文章建议初学者从PPO
一、通俗案例:强化学习特工训练营
想象你在训练一批AI特工:
-
DDPG 是沉稳的狙击手,擅长在连续动作空间中精准命中目标
-
PPO 是适应力极强的特种兵,在任何环境都能快速调整策略
-
TRPO 是谨慎的战略家,每一步决策都确保整体策略稳步提升
-
SAC 是神秘的特工,在不确定性环境中总能找到最优路径
-
TD3 是DDPG的升级版,学会了"声东击西"的技巧
-
MADDPG 是特工小队,擅长团队协作完成复杂任务
这些算法就像不同类型的特工,各有所长,共同组成了深度强化学习的"复仇者联盟"。
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/ZYbscAfVluTyu7dzCwL3bg
https://mp.weixin.qq.com/s/ZYbscAfVluTyu7dzCwL3bg
二、核心原理详解
1. DDPG(Deep Deterministic Policy Gradient)
DDPG结合了DQN和确定性策略梯度,适用于连续动作空间:
-
核心思想:使用 Actor-Critic 框架,Actor 输出确定性动作,Critic 评估该动作的价值
-
关键创新:经验回放和目标网络(同DQN),解决样本相关性和训练不稳定性
数学公式:
-
Actor 目标:
-
策略梯度:
-
目标网络更新:(软更新,)
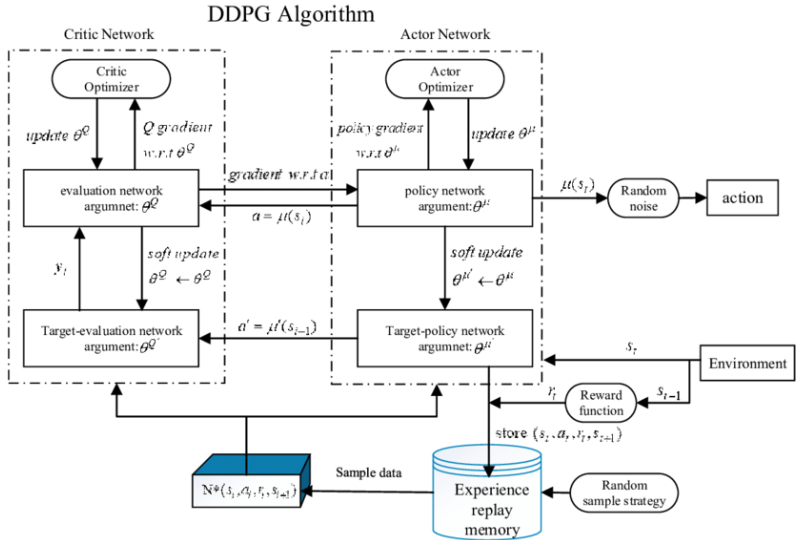
DDPG算法
2. PPO(Proximal Policy Optimization)
PPO是目前最流行的强化学习算法之一,平衡了性能和实现复杂度:
-
核心思想:限制策略更新的幅度,确保新策略与旧策略不会相差太大
-
关键创新:使用剪辑目标函数(clipped objective)限制策略更新
数学公式:
-
目标函数:
-
其中 是策略比率
-
通常取0.1或0.2,控制更新幅度
3. TRPO(Trust Region Policy Optimization)
TRPO是PPO的前身,理论更严谨但实现复杂:
-
核心思想:在信任域(trust region)内更新策略,保证策略性能单调提升
-
关键创新:使用KL散度约束策略更新幅度
数学公式:
-
优化目标:
-
约束条件:
-
通过自然梯度下降求解带约束优化问题
4. SAC(Soft Actor-Critic)
SAC是一种基于最大熵的强化学习算法,具有良好的探索能力和稳定性:
-
核心思想:在最大化累积奖励的同时最大化策略熵(鼓励探索)
-
关键创新:软策略迭代和双Q网络
数学公式:
-
目标函数:
-
其中 是策略熵
-
是温度参数,控制探索与利用的平衡
5. TD3(Twin Delayed DDPG)
TD3是DDPG的改进版,解决了DDPG过估计和训练不稳定问题:
-
核心思想:通过延迟策略更新和双Q网络减轻过估计偏差
-
关键创新:双Q网络、延迟策略更新、目标策略平滑
数学公式:
-
目标值计算:
-
其中 是小噪声,用于平滑目标策略
-
策略更新频率低于Q网络更新(通常为2-10倍)
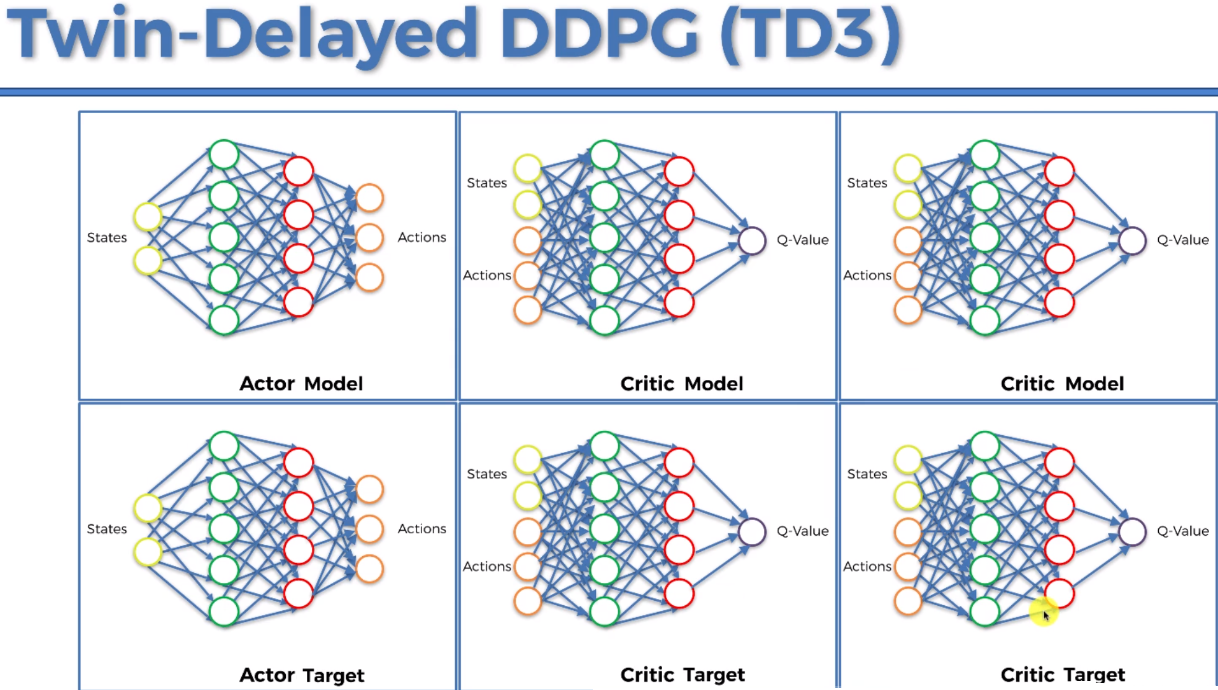
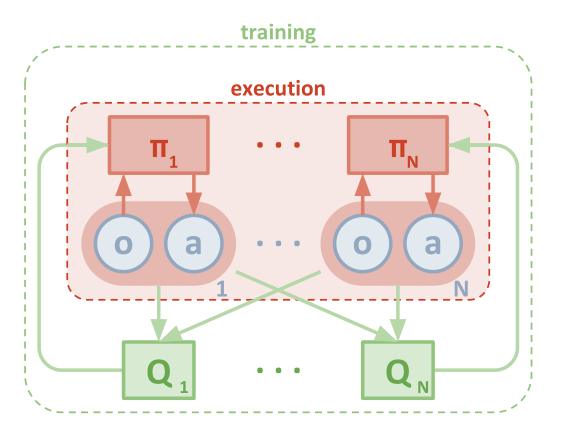
6. MADDPG(Multi-Agent DDPG)
MADDPG是适用于多智能体系统的强化学习算法:
-
核心思想:每个智能体有自己的Actor,但Critic可以访问所有智能体的信息
-
关键创新:集中式训练、分布式执行(CTDE)框架
数学公式:
-
单个智能体策略:,其中 是智能体i的观测
-
集中式Critic:,其中 是所有智能体的动作序列
-
策略梯度:
三、算法对比与适用场景
| 算法 | 核心优势 | 主要缺点 | 适用场景 |
|---|---|---|---|
| DDPG | 适用于连续动作空间 | 易过估计,稳定性差 | 简单机器人控制 |
| PPO | 性能优异,实现简单 | 理论基础不如TRPO | 几乎所有场景,推荐首选 |
| TRPO | 保证策略单调提升 | 实现复杂,计算量大 | 需要严格保证稳定性的场景 |
| SAC | 探索能力强,样本效率高 | 调参复杂 | 需要充分探索的环境 |
| TD3 | 比DDPG更稳定 | 比PPO复杂 | 连续动作空间,需要高稳定性 |
| MADDPG | 适用于多智能体系统 | 扩展性差,需大量训练 | 多机器人协作,游戏AI |
四、实操项目:多算法连续控制任务大比拼
下面我们将在经典的Pendulum-v1环境中对比六种算法的性能。这个环境要求智能体控制一个单摆,使其保持向上直立的状态。
项目代码
以下是这段代码中最核心的部分,包含了主要的强化学习算法实现和训练逻辑:
-
经验回放缓冲区(用于离线强化学习算法)
class ReplayBuffer:
def __init__(self, capacity):
self.memory = deque(maxlen=capacity)
self.Transition = namedtuple('Transition', ('state', 'action', 'reward', 'next_state', 'done'))
def push(self, *args):
self.memory.append(self.Transition(*args))
def sample(self, batch_size):
transitions = random.sample(self.memory, batch_size)
batch = self.Transition(*zip(*transitions))
states = torch.tensor(batch.state, dtype=torch.float32).to(device)
actions = torch.tensor(batch.action, dtype=torch.float32).to(device)
rewards = torch.tensor(batch.reward, dtype=torch.float32).unsqueeze(1).to(device)
next_states = torch.tensor(batch.next_state, dtype=torch.float32).to(device)
dones = torch.tensor(batch.done, dtype=torch.float32).unsqueeze(1).to(device)
return states, actions, rewards, next_states, dones
-
基础网络结构
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.fc1 = nn.Linear(state_dim, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, action_dim)
self.max_action = max_action
def forward(self, state):
x = F.relu(self.fc1(state))
x = F.relu(self.fc2(x))
x = torch.tanh(self.fc3(x))
return x * self.max_action
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.fc1 = nn.Linear(state_dim + action_dim, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, 1)
def forward(self, state, action):
x = torch.cat([state, action], dim=1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
-
DDPG算法核心实现
class DDPG:
def __init__(self, state_dim, action_dim, max_action):
self.actor = Actor(state_dim, action_dim, max_action).to(device)
self.actor_target = Actor(state_dim, action_dim, max_action).to(device)
self.actor_target.load_state_dict(self.actor.state_dict())
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=1e-4)
self.critic = Critic(state_dim, action_dim).to(device)
self.critic_target = Critic(state_dim, action_dim).to(device)
self.critic_target.load_state_dict(self.critic.state_dict())
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=1e-3)
self.max_action = max_action
self.gamma = 0.99
self.tau = 0.005
def select_action(self, state, noise=0.1):
state = torch.tensor(state, dtype=torch.float32).to(device)
action = self.actor(state).cpu().data.numpy()
if noise > 0:
action += np.random.normal(0, noise, size=action.shape)
return np.clip(action, -self.max_action, self.max_action)
def train(self, replay_buffer, batch_size=100):
if len(replay_buffer) < batch_size:
return 0
states, actions, rewards, next_states, dones = replay_buffer.sample(batch_size)
# 计算目标Q值
target_actions = self.actor_target(next_states)
target_q = self.critic_target(next_states, target_actions)
target_q = rewards + (1 - dones) * self.gamma * target_q
# 更新critic
current_q = self.critic(states, actions)
critic_loss = F.mse_loss(current_q, target_q)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 更新actor
actor_loss = -self.critic(states, self.actor(states)).mean()
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 软更新目标网络
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
return critic_loss.item()
-
PPO算法核心实现
class PPO:
def __init__(self, state_dim, action_dim, max_action):
self.actor = nn.Sequential(
nn.Linear(state_dim, 256),
nn.Tanh(),
nn.Linear(256, 256),
nn.Tanh(),
nn.Linear(256, 2 * action_dim)
).to(device)
self.critic = nn.Sequential(
nn.Linear(state_dim, 256),
nn.Tanh(),
nn.Linear(256, 256),
nn.Tanh(),
nn.Linear(256, 1)
).to(device)
self.optimizer = optim.Adam(list(self.actor.parameters()) + list(self.critic.parameters()), lr=3e-4)
self.gamma = 0.99
self.gae_lambda = 0.95
self.epsilon = 0.2
self.K_epochs = 10
self.max_action = max_action
def select_action(self, state, deterministic=False):
state = torch.tensor(state, dtype=torch.float32).to(device)
mu, log_std = self.actor(state).chunk(2, dim=-1)
std = log_std.exp()
dist = Normal(mu, std)
action = mu if deterministic else dist.sample()
log_prob = dist.log_prob(action).sum(-1, keepdim=True)
action = torch.tanh(action) * self.max_action
return action.cpu().detach().numpy(), log_prob.cpu().detach().numpy()
def train(self, states, actions, old_log_probs, returns, advantages):
states = torch.tensor(states, dtype=torch.float32).to(device)
actions = torch.tensor(actions, dtype=torch.float32).to(device)
old_log_probs = torch.tensor(old_log_probs, dtype=torch.float32).to(device)
returns = torch.tensor(returns, dtype=torch.float32).to(device).unsqueeze(1)
advantages = torch.tensor(advantages, dtype=torch.float32).to(device).unsqueeze(1)
# 标准化优势
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
for _ in range(self.K_epochs):
log_probs, values, entropy = self.evaluate(states, actions)
# 计算比率
ratio = torch.exp(log_probs - old_log_probs.detach())
# 计算剪辑损失
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - self.epsilon, 1 + self.epsilon) * advantages
actor_loss = -torch.min(surr1, surr2).mean()
# 计算价值损失
critic_loss = F.mse_loss(returns, values)
# 总损失
loss = actor_loss + 0.5 * critic_loss - 0.01 * entropy.mean()
# 优化
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.item()
-
主要训练函数示例(以DDPG为例)
def train_ddpg(env, agent, episodes=200, max_steps=200):
replay_buffer = ReplayBuffer(100000)
scores = []
avg_scores = []
for episode in tqdm(range(episodes), desc="DDPG Training"):
state = env.reset()
if isinstance(state, tuple):
state = state[0]
score = 0
for _ in range(max_steps):
action = agent.select_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
replay_buffer.push(state, action, reward, next_state, done)
agent.train(replay_buffer)
state = next_state
score += reward
if done:
break
scores.append(score)
avg_score = np.mean(scores[-100:]) if len(scores) >= 100 else np.mean(scores)
avg_scores.append(avg_score)
return scores, avg_scores
-
主函数
def main():
# 创建环境
env = gym.make('Pendulum-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
# 初始化算法
ddpg_agent = DDPG(state_dim, action_dim, max_action)
ppo_agent = PPO(state_dim, action_dim, max_action)
trpo_agent = TRPO(state_dim, action_dim, max_action)
sac_agent = SAC(state_dim, action_dim, max_action)
td3_agent = TD3(state_dim, action_dim, max_action)
maddpg_agent = MADDPG(state_dim, action_dim, max_action)
algorithms = ["DDPG", "PPO", "TRPO", "SAC", "TD3", "MADDPG"]
agents = [ddpg_agent, ppo_agent, trpo_agent, sac_agent, td3_agent, maddpg_agent]
train_functions = [train_ddpg, train_ppo, train_trpo, train_sac, train_td3, train_maddpg]
# 训练所有算法
scores_list = []
avg_scores_list = []
for i, (alg, agent, train_func) in enumerate(zip(algorithms, agents, train_functions)):
print(f"\nStarting training for {alg}...")
scores, avg_scores = train_func(env, agent, episodes=200, max_steps=200)
scores_list.append(scores)
avg_scores_list.append(avg_scores)
# 保存结果
save_results(algorithms, avg_scores_list, scores_list)
env.close()
代码说明
这个项目实现了六种深度强化学习算法,并在OpenAI Gym的Pendulum-v1环境中进行对比。主要特点:
-
环境选择:Pendulum-v1是一个经典的连续控制任务,智能体需要控制单摆保持直立
-
算法实现:完整实现了DDPG、PPO、TRPO、SAC、TD3和MADDPG六种算法
-
结果可视化:生成四种不同类型的结果图,包括平均得分对比、单个算法性能、最终性能分布和学习速度对比
-
服务器友好:所有结果图都会保存到results文件夹,不需要显示界面
如何运行
-
安装必要的依赖:
pip install gym torch numpy matplotlib tqdm
-
运行代码:
python reinforcement_learning_comparison.py
-
查看结果:程序会自动创建results文件夹,并保存所有结果图
五、预期结果与分析
(因为小编未进行细致调参,要得到更好的结果还需继续微调~)
运行代码后,你将得到四个结果图:
-
平均得分对比图:展示六种算法在训练过程中的平均得分变化,直观比较整体性能
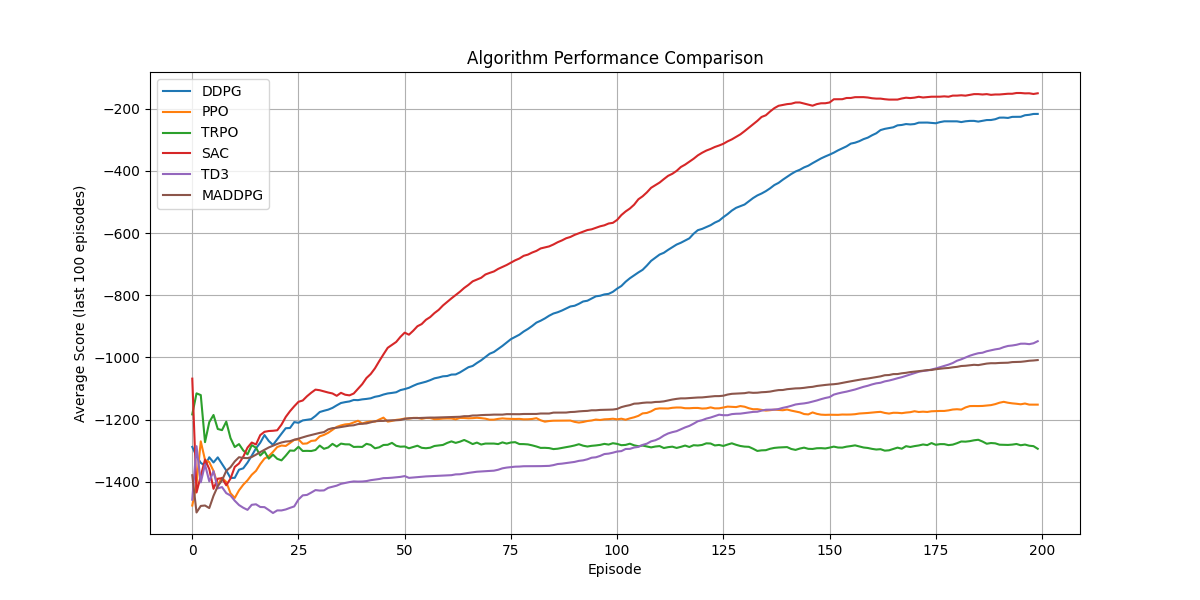
-
单个算法性能图:每个算法单独的得分曲线,包括每 episode 的得分和平均得分
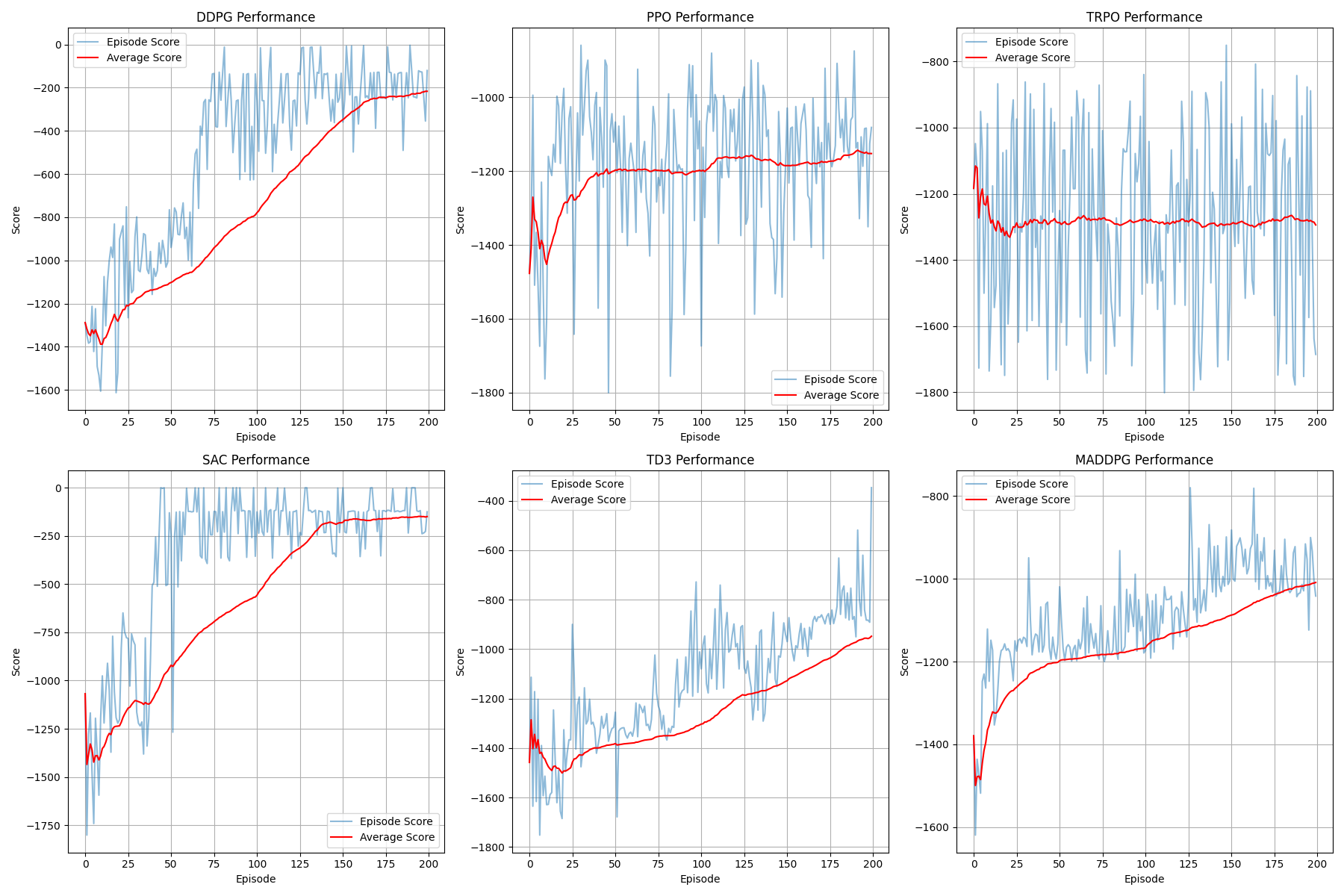
单个算法性能图
-
最终性能箱线图:展示每种算法在最后100个episode的得分分布,反映算法的稳定性
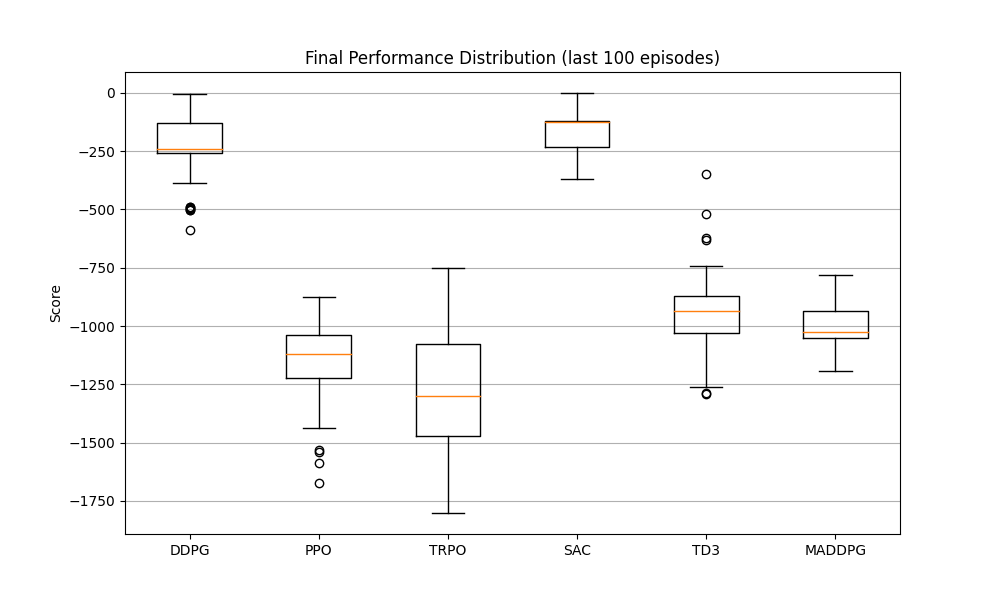
-
学习速度对比图:比较每种算法达到目标分数所需的episode数量,反映学习效率
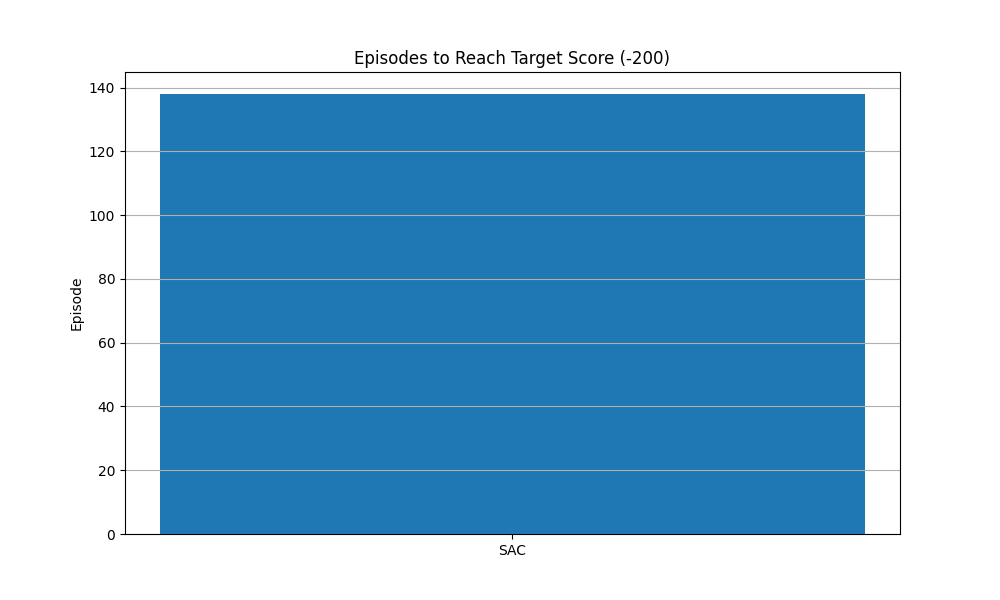 在Pendulum-v1环境中,通常表现较好的算法是PPO和SAC,它们能更快地收敛到较高的分数。TD3作为DDPG的改进版,通常比DDPG表现更稳定。TRPO虽然理论上更优,但在实际应用中往往不如PPO表现好,且实现更复杂。MADDPG在这个单智能体环境中可能表现不如其他专门为单智能体设计的算法。
在Pendulum-v1环境中,通常表现较好的算法是PPO和SAC,它们能更快地收敛到较高的分数。TD3作为DDPG的改进版,通常比DDPG表现更稳定。TRPO虽然理论上更优,但在实际应用中往往不如PPO表现好,且实现更复杂。MADDPG在这个单智能体环境中可能表现不如其他专门为单智能体设计的算法。
六、总结与扩展
本项目展示了六种主流深度强化学习算法的核心原理和实际应用。通过在相同环境中的对比,你可以直观地了解它们的优缺点和适用场景。
对于小白来说,建议从PPO开始学习和使用,它平衡了性能、稳定性和实现复杂度。当你熟悉基础后,可以尝试SAC或TD3等更先进的算法。
扩展方向:
-
在更复杂的环境(如HalfCheetah-v4)中测试这些算法
-
调整超参数,观察对算法性能的影响
-
尝试实现更先进的算法(如PPO的改进版PPO2、或者基于模型的强化学习算法)
-
将MADDPG应用到真正的多智能体环境(如Multi-Agent Particle Environment)
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/ZYbscAfVluTyu7dzCwL3bg
https://mp.weixin.qq.com/s/ZYbscAfVluTyu7dzCwL3bg

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)