不用繁琐调参!李飞飞团队MoMaGen:用极简数据,解决生成式AI的规模化落地难题
MOMAGEN 框架首先将数据生成过程形式化为一个约束优化问题。其目标是在满足一系列硬约束(Hard Constraints)的前提下,最小化一个由软约束(Soft Constraints)构成的成本函数L⋅L⋅。arg minat∈TL⋅s.t.st1fstat∀t∈T(系统动力学)Gkinstat≤0∀t∈T(运动学可行性)Gcollstat≥0∀t∈T(无碰撞)Gvissta。
一、导读
在机器人学习领域,模仿人类演示是教导机器人复杂技能的有效方法,但这需要大量且多样化的人类操作数据。对于多步骤双臂移动操纵这类复杂任务——即机器人不仅要移动身体,还要同时协调两只手臂进行操作——数据收集变得异常昂贵和耗时。现有数据生成技术在固定基座的操纵任务上表现尚可,但一遇到需要移动的机器人就束手无策,主要面临两大难题:一是如何智能地移动机器人基座以确保手臂能够得着目标物体(可达性问题);二是如何调整主动摄像头的视角,确保机器人能持续“看”到关键物体以做出正确决策(可见性问题)。
为解决这些挑战,本论文提出了一个名为 MOMAGEN 的数据自动生成框架,其核心思想是将数据生成过程转化为一个带约束的优化问题。该框架通过一系列精心设计的软硬约束(例如,可达性是必须满足的硬约束,导航时保持物体可见是尽量满足的软约束),仅需一个人类演示作为“种子”,就能为机器人自动生成海量、多样化且高质量的训练数据,显著提升了后续视觉模仿学习策略的性能与成功率。
二、论文基本信息

- 论文标题: MOMAGEN: GENERATING DEMONSTRATIONS UNDER SOFT AND HARD CONSTRAINTS FOR MULTI-STEP BIMANUAL MOBILE MANIPULATION
- 论文链接: https://arxiv.org/abs/2510.18316)
三、主要贡献与创新
- 提出了一个统一的约束优化框架来定义机器人数据的自动生成问题。
- 针对移动操纵,创新性地引入了可达性(硬约束)和可见性(软/硬约束)。
- 实现了仅用单个人类演示,就能为复杂双臂移动任务生成大量有效数据。
- 验证了生成数据可训练成功的模仿学习策略,并实现了高效的模拟到真实迁移。
四、研究方法与原理
该论文的核心思路是:将数据生成过程视为一个约束优化问题,通过同时满足可达性、可见性等硬性条件并优化软性指标,为双臂移动操纵任务自动创建多样化和高质量的演示数据。
【模型结构图】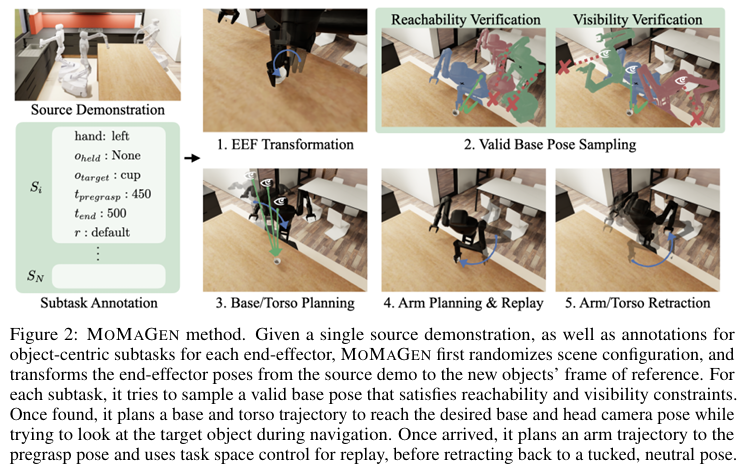
1. 将数据生成定义为约束优化问题
MOMAGEN 框架首先将数据生成过程形式化为一个约束优化问题。其目标是在满足一系列硬约束(Hard Constraints)的前提下,最小化一个由软约束(Soft Constraints)构成的成本函数 L(⋅)\mathcal{L}(\cdot)L(⋅)。
arg minat∈[T]L(⋅)s.t.{st+1=f(st,at),∀t∈[T](系统动力学)Gkin(st,at)≤0,∀t∈[T](运动学可行性)Gcoll(st,at)≥0,∀t∈[T](无碰撞)Gvis(st,at,oi(t))≤0,∀t∈[T](可见性)TEkW=ToiW(Toi,srcW)−1TEk,srcW(接触任务的姿态保持)st∈Dsuccess(任务成功) \text{arg min}_{\mathbf{a}_t \in [T]} \mathcal{L}(\cdot) \quad \text{s.t.} \quad \begin{cases} s_{t+1} = f(s_t, a_t), \forall t \in [T] & \text{(系统动力学)}\\ G_{kin}(s_t, a_t) \le 0, \forall t \in [T] & \text{(运动学可行性)}\\ G_{coll}(s_t, a_t) \ge 0, \forall t \in [T] & \text{(无碰撞)}\\ G_{vis}(s_t, a_t, o_{i(t)}) \le 0, \forall t \in [T] & \text{(可见性)}\\ T_{E_k}^W = T_{o_i}^W (T_{o_{i,src}}^W)^{-1} T_{E_k, src}^W & \text{(接触任务的姿态保持)}\\ s_t \in \mathcal{D}_{\text{success}} & \text{(任务成功)} \end{cases} arg minat∈[T]L(⋅)s.t.⎩ ⎨ ⎧st+1=f(st,at),∀t∈[T]Gkin(st,at)≤0,∀t∈[T]Gcoll(st,at)≥0,∀t∈[T]Gvis(st,at,oi(t))≤0,∀t∈[T]TEkW=ToiW(Toi,srcW)−1TEk,srcWst∈Dsuccess(系统动力学)(运动学可行性)(无碰撞)(可见性)(接触任务的姿态保持)(任务成功)
上式中,sts_tst 和 ata_tat 分别代表状态和动作,f(⋅)f(\cdot)f(⋅) 是系统动力学模型。硬约束确保了生成轨迹的有效性,例如:轨迹必须符合机器人的运动学限制、不能发生碰撞、在操纵时关键物体必须可见、并且在进行抓取姿态时,末端执行器与目标物体间的相对姿态 TEkWT_{E_k}^WTEkW 必须与源演示中保持一致。
2. 为移动操纵设计的关键约束
MOMAGEN 的创新之处在于为移动操纵任务引入了几个关键的新约束:
-
可达性作为硬约束(Reachability as Hard Constraint): 这是解决移动操纵问题的核心。与之前方法直接复用源演示中的基座移动轨迹不同,MOMAGEN 会主动采样新的基座位置。它通过逆运动学(IK)求解来判断,在某个采样的基座姿态下,机器人的手臂是否能够到达后续操纵任务所需的所有末端执行器目标点。只有满足可达性,该基座姿态才被认为是有效的。
-
操纵过程中的物体可见性作为硬约束(Object Visibility during Manipulation as Hard Constraint): 为了让视觉策略能够工作,机器人在执行具体的操纵动作(如抓取、擦拭)时,其头部的摄像头必须能够清楚地看到任务相关的物体。MOMAGEN 通过检查从摄像头到物体的视线是否被遮挡来保证这一点。
-
导航过程中的物体可见性作为软约束(Object Visibility during Navigation as Soft Constraint): 在机器人从A点移动到B点的过程中,虽然不是强制要求,但最好能一直看着目标物体。MOMAGEN 将此作为一个软约束,通过在运动规划中加入一个指向目标的成本项,引导机器人在导航时持续将摄像头朝向目标物体。
-
姿态回收作为软约束(Retraction as Soft Constraint): 在完成一个子任务后,机器人会将其手臂和躯干收回到一个紧凑的初始姿态。这不仅可以减小机器人的占用空间,为下一次导航做准备,还能使生成的动作更加规范和安全。
3. MOMAGEN 算法流程
结合上图和算法伪代码(Algorithm 1),MOMAGEN 为一个新的场景生成演示数据的流程如下:
- 场景随机化与子任务分解: 首先,在一个新的模拟环境中随机放置任务物体。原始的人类演示被预先分解为一系列有序的子任务(例如:导航到桌子前 -> 抓起杯子 -> 导航到水槽 -> 放下杯子)。
- 逐个子任务生成轨迹:
- 姿态变换与约束检查: 对于每个子任务,首先根据新场景中物体的姿态,计算出机器人末端执行器需要达到的新目标姿态。然后,在机器人当前基座位置下,检查是否同时满足可达性和操纵可见性这两个硬约束。
- 不满足则重规划基座: 如果当前基座位置不满足任一硬约束(比如太远够不着),MOMAGEN 会启动一个循环:不断在目标物体周围采样新的基座和摄像头姿态,直到找到一个既可达又可见的“黄金位置”。
- 移动到新位置: 找到有效位姿后,使用运动规划器规划一条从当前位置移动到目标位置的基座轨迹。此处的规划过程会受到导航可见性这个软约束的影响,使得机器人在移动时倾向于“回头看”目标物体。
- 执行操纵: 到达指定位置后,机器人开始执行操-作。它首先规划手臂动作到达预抓取姿态,然后通过任务空间控制来复现源演示中与物体交互的轨迹。
- 姿态回收: 子任务完成后,根据软约束选择性地执行回收动作。
- 循环: 重复以上步骤,直到所有子任务完成,一条全新的、完整的演示数据便生成了。
五、实验设计与结果分析
论文在 OmniGibson 模拟器中的四个家居任务上对 MOMAGEN 进行了评估,任务涵盖了长距离导航、双臂协同以及精细操作。
- 数据集与评测指标: 所有实验均基于单个人类演示生成数据。评估指标包括数据生成成功率、生成数据的多样性(物体姿态覆盖范围、基座和末端执行器动作范围)以及任务相关物体可见率。
- 随机化方案: 实验设置了三个难度递增的场景随机化等级(D0, D1, D2),从简单的物体位置微调到大范围随机摆放并增加障碍物。
对比实验
论文将 MOMAGEN 与两个先前的先进方法(SkillMimicGen, DexMimicGen)进行了比较。由于这两个基线方法无法自主生成新的基座移动轨迹,实验中让它们复用源演示的导航路径。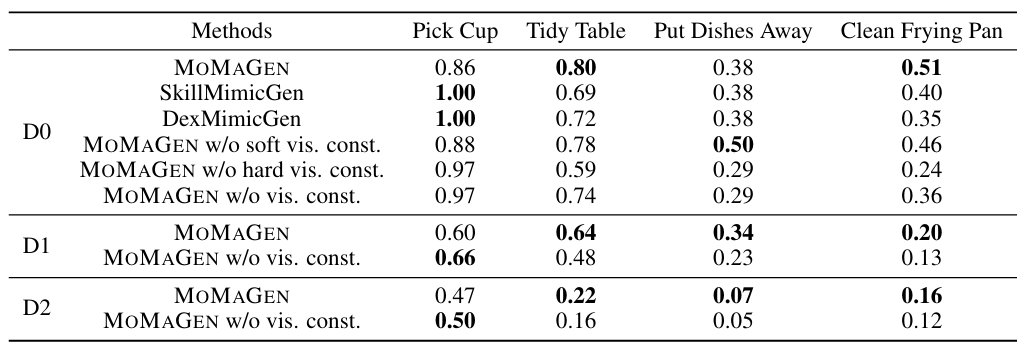
- 结果分析:
- 从上表可以看出,在简单的D0随机化下,基线方法尚能处理部分任务,但对于复杂的双臂协同任务(如Clean Frying Pan),成功率已经开始下降。
- 最关键的是,当进入D1和D2这种大范围随机化场景时,基线方法的成功率直接降为零,因为复用的导航路径无法使机器人到达新的物体位置。
- 相比之下,MOMAGEN 在所有难度等级和所有任务上都保持了可观的成功率,证明了其处理移动操纵任务的强大能力。
可视化对比
通过可视化生成的数据分布,可以直观地看到 MOMAGEN 的优势。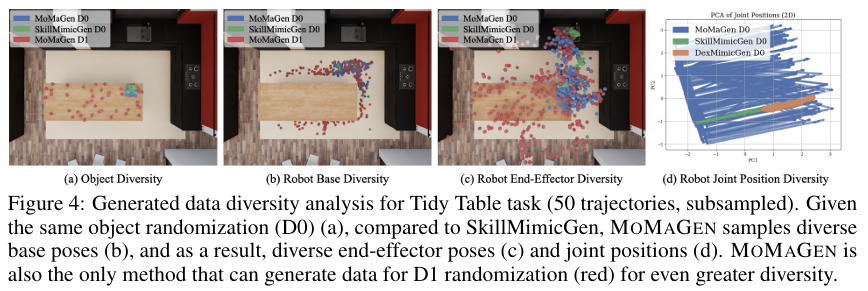
- 结果分析:
- 在上图中,红色代表 MOMAGEN (D1) 生成的数据,蓝色和绿色代表基线方法和MOMAGEN (D0)。
- 图(a)显示了物体姿态的覆盖范围,MOMAGEN (D1) 覆盖了整个台面,远超其他方法。
- 这种广泛的物体分布,得益于MOMAGEN能够生成多样化的基座轨迹(图b),进而驱动了更多样的末端执行器轨迹(图c)和关节动作(图d)。这表明 MOMAGEN 生成的数据集在状态空间和动作空间上都具有更高的多样性。
消融实验
为了验证所提出的可见性约束的有效性,论文进行了消融研究。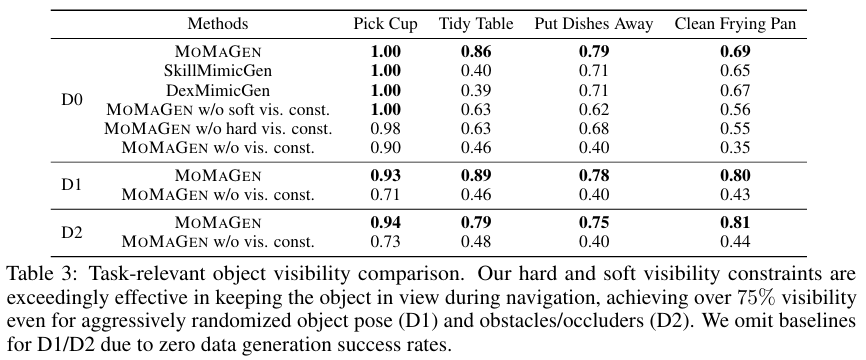
- 结果分析:
- 上表数据显示,完整版的 MOMAGEN 在导航过程中的物体可见率远高于移除了可见性约束的版本(w/o vis. const.)。即使在有障碍物和遮挡的D2场景下,可见率依然能保持在75%以上。
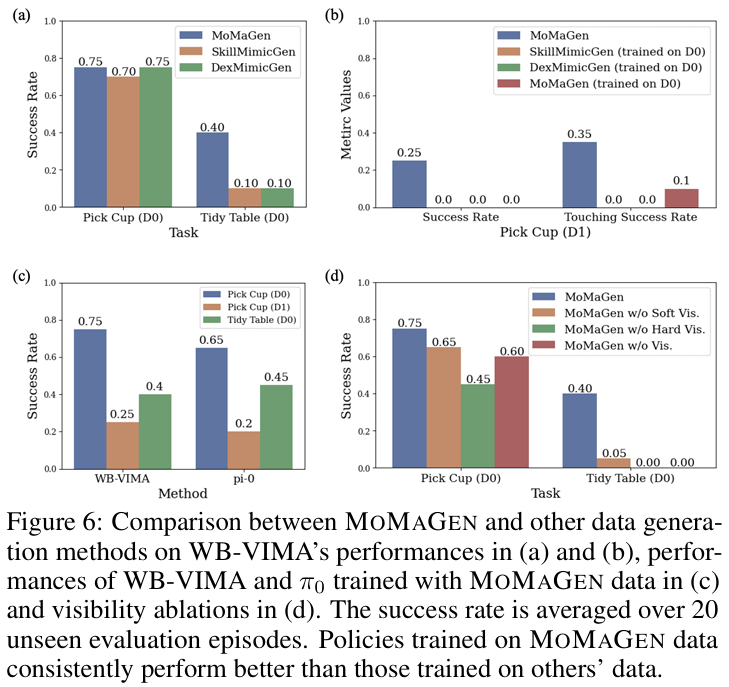
- 这直接证明了论文提出的软、硬可见性约束对于生成高质量的视觉数据至关重要,这反过来也极大地帮助了下游视觉模仿策略的训练(如图6(d)所示,更高可见率的数据训练出的策略成功率也更高)。
六、论文结论与评价
本文的核心结论是,通过将数据生成过程构建为一个带有特定领域约束(如可达性和可见性)的优化问题,可以有效解决以往方法在复杂移动操纵任务上数据生成失败的难题。MOMAGEN 框架仅需极少量的人类演示,就能自动化地生成规模和多样性远超以往的数据集。实验证明,使用这些数据训练的模仿学习策略不仅在仿真中表现优异,而且在迁移到真实机器人时也展现出巨大潜力——例如,在使用少量真实数据对 π0\pi^0π0 模型进行微调时,经过MOMAGEN数据预训练的模型取得了60%的成功率,而没有预训练的模型成功率为0%。
- 优点: 本文提出的约束优化框架具有很强的通用性和扩展性,为未来更复杂任务(如开门、全身协调运动)的数据生成研究提供了一个坚实的理论基础。方法创新点明确,直接解决了移动操纵中的核心痛点。
- 缺点与局限: 当前方法在生成数据时,依赖于仿真环境中完整的场景信息(如物体的精确位姿和几何模型),这在真实世界中难以直接获取,限制了其直接在真实环境中生成数据的能力。此外,该方法目前主要处理导航和操纵交替进行的任务,对于需要导航与操纵同时进行的全身协同任务(whole-body manipulation)还未深入探索。
- 批判性思考与启示: 该工作有力地证明了“高质量的合成数据”对于机器人学习的巨大价值。未来的研究方向可以探索如何将场景感知模块(如使用视觉大模型进行物体位姿估计)与MOMAGEN框架结合,以减少对仿真环境精确信息的依赖,使其更接近真实世界应用。同时,可以尝试将软约束设计得更加丰富,例如引入能耗、平顺度甚至“拟人化”等指标,以生成更符合特定需求的机器人行为。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)