保险行业智能体搭建:基于Qwen-Agent的Text2SQL技术探索
随着人工智能技术的快速发展,Text2SQL技术作为自然语言处理与数据库系统的桥梁,正在成为企业智能化应用的重要组成部分。本文将通过一个保险行业智能体的实际案例,深入探讨基于Qwen-Agent的Text2SQL技术实现原理、模型选择策略、性能评估方法以及在实际业务场景中的应用价值。我们将展示如何构建一个完整的保险行业智能查询系统,从基础的SQL生成到高级的Qwen-Agent智能体实现。
摘要
随着人工智能技术的快速发展,Text2SQL技术作为自然语言处理与数据库系统的桥梁,正在成为企业智能化应用的重要组成部分。本文将通过一个保险行业智能体的实际案例,深入探讨基于Qwen-Agent的Text2SQL技术实现原理、模型选择策略、性能评估方法以及在实际业务场景中的应用价值。我们将展示如何构建一个完整的保险行业智能查询系统,从基础的SQL生成到高级的Qwen-Agent智能体实现。
1. 引言
Text2SQL技术旨在将自然语言查询转换为等效的SQL语句,从而降低非技术人员访问数据库的门槛。在保险行业,业务人员需要频繁地从复杂的客户、保单、理赔等数据表中获取信息,传统的SQL查询方式不仅要求用户具备专业知识,还容易出现语法错误。Text2SQL技术的引入能够有效解决这一问题,实现更直观、高效的数据访问。
项目效果
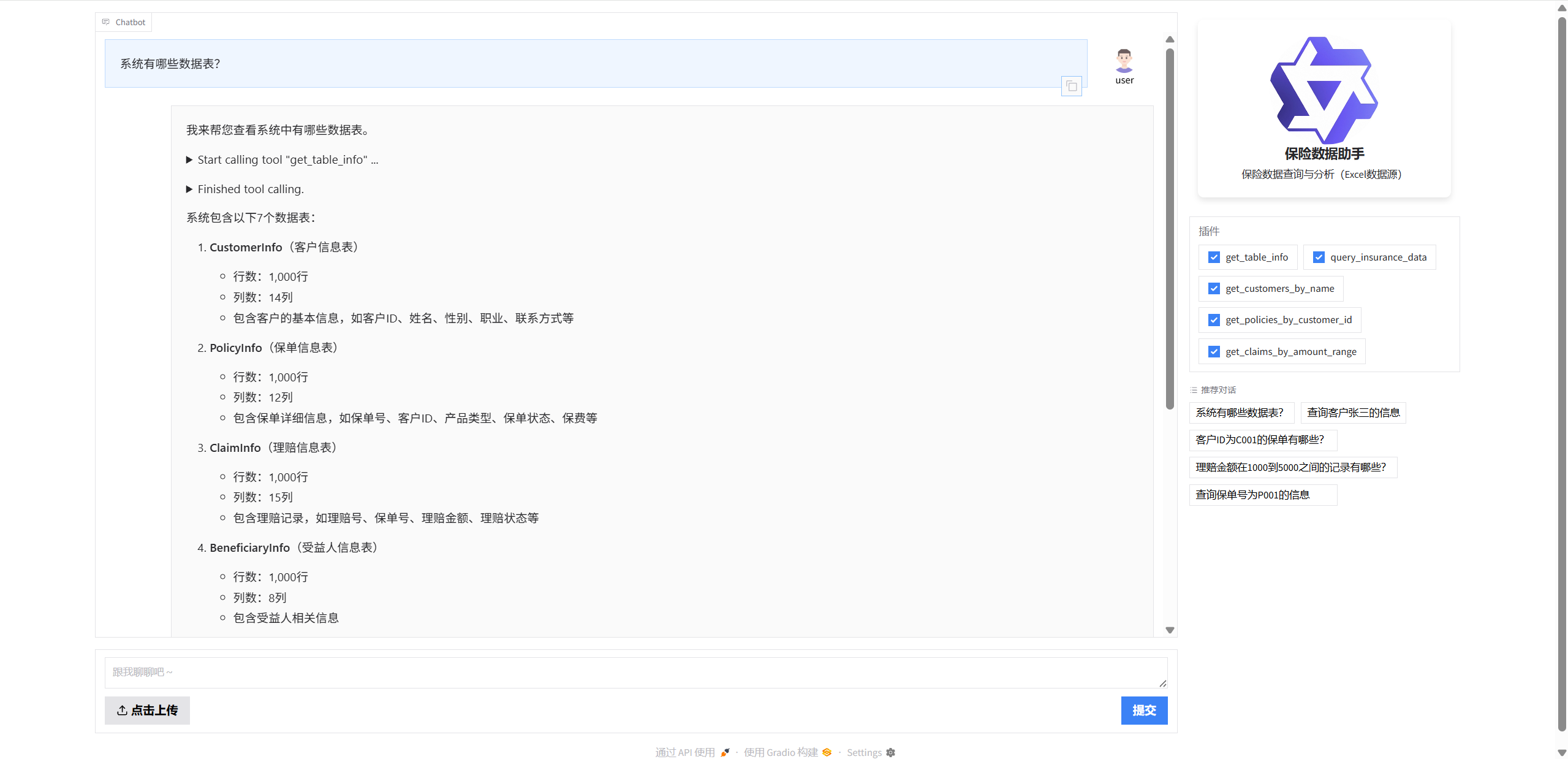
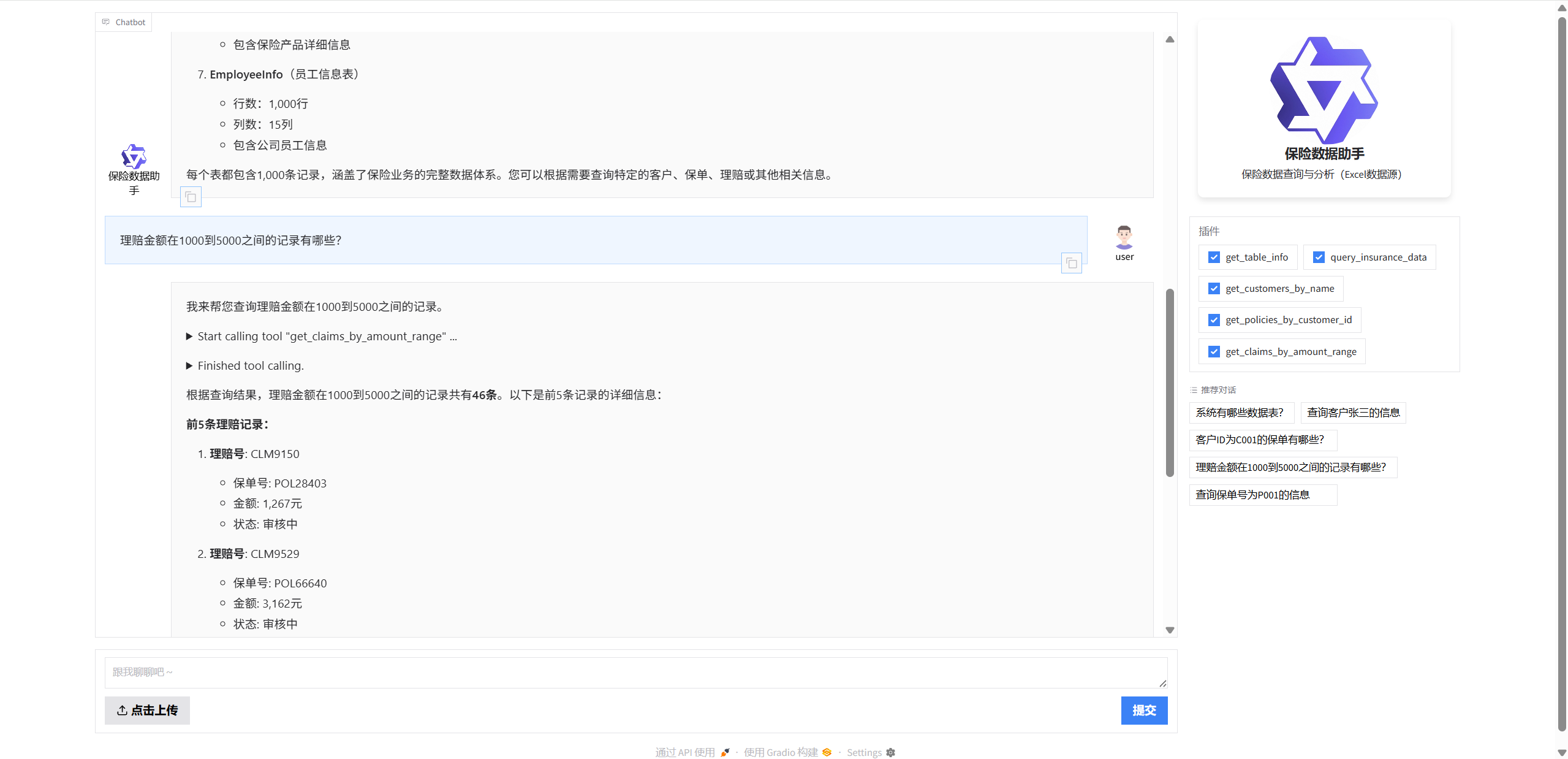
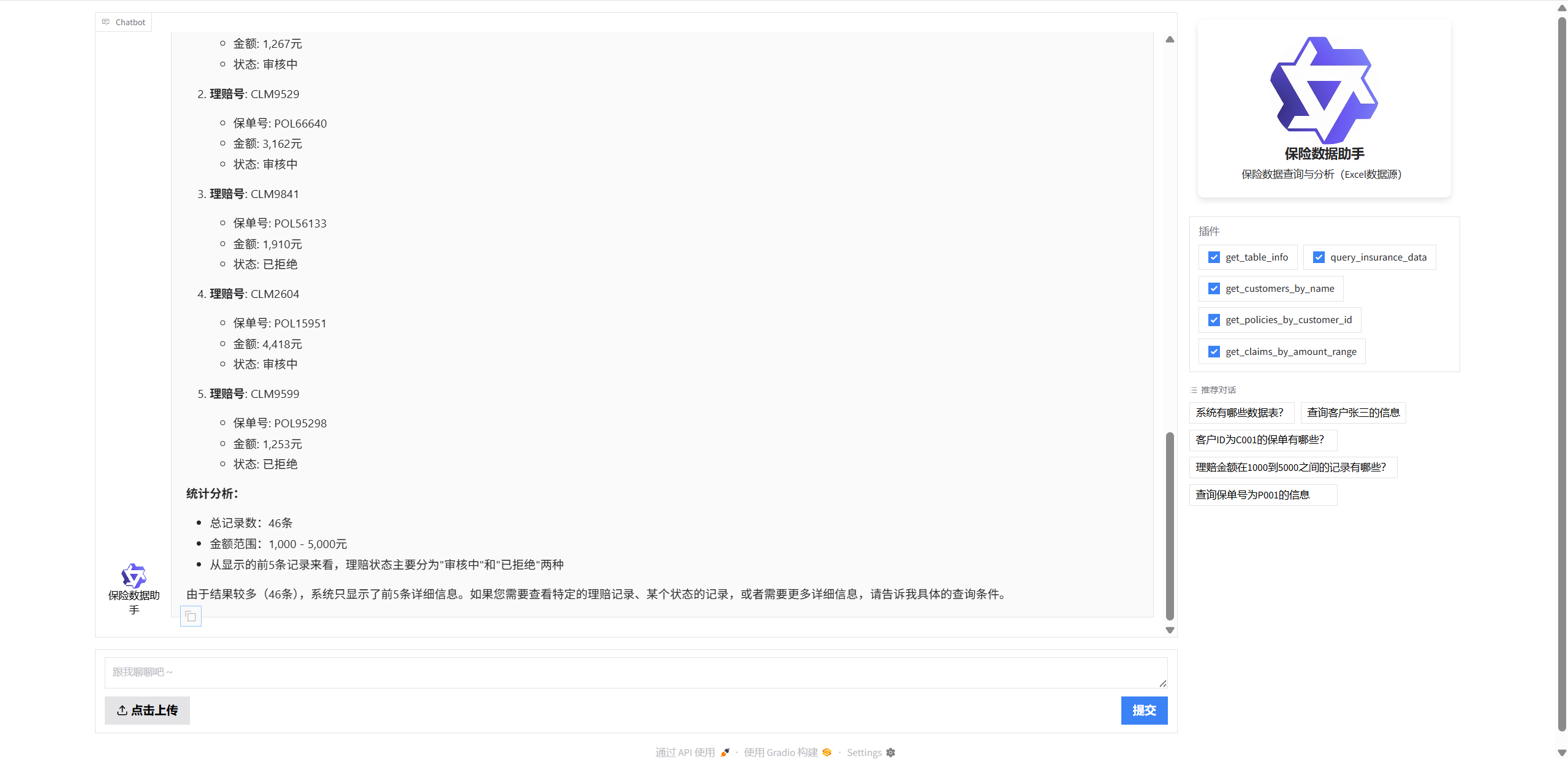
2. 系统架构设计
本文实现的Text2SQL系统包含三个核心模块:SQL生成模块、SQL评估模块和智能代理模块。
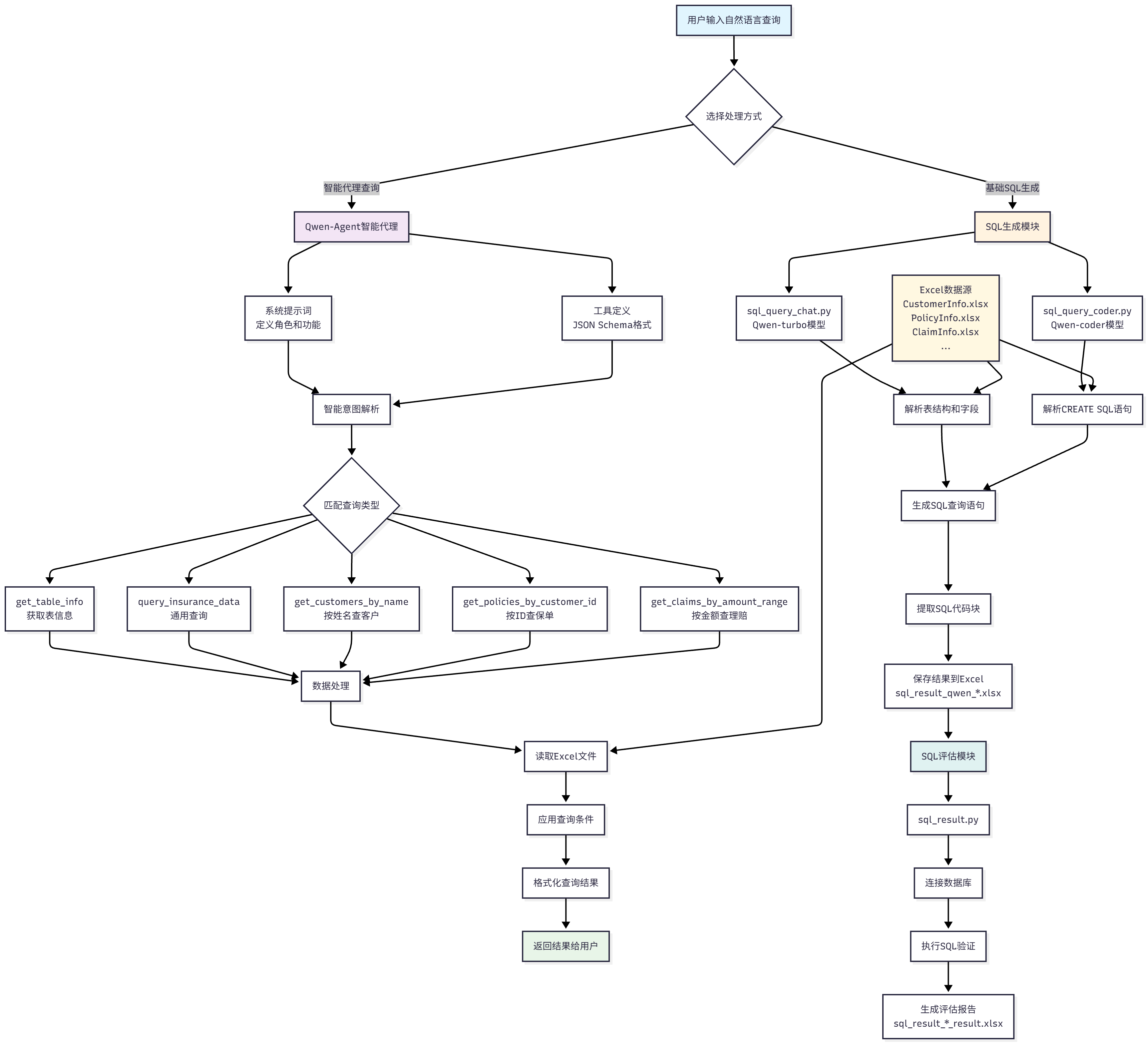
2.1 SQL生成模块
SQL生成模块负责将自然语言问题转换为SQL语句。我们实现了两种不同的生成策略:
- 基于对话模型的生成 (
sql_query_chat.py):使用Qwen-turbo模型,通过对话提示的方式理解表结构并生成SQL。 - 基于代码生成模型的生成 (
sql_query_coder.py):使用Qwen-coder模型,专门针对代码生成任务进行优化。
核心功能
- 自动解析数据表结构
- 智能识别查询意图
- 生成符合语法的SQL语句
- 结果保存和性能统计
实现细节
def get_sql(self, query, table_description):
sys_prompt = """我正在编写SQL,以下是数据库中的数据表和字段,
请思考:哪些数据表和字段是该SQL需要的,然后编写对应的SQL,
如果有多个查询语句,请尝试合并为一个。编写SQL请采用```sql"""
user_prompt = f"""{table_description}
=====
我要写的SQL是:{query}
请思考:哪些数据表和字段是该SQL需要的,然后编写对应的SQL"""
messages = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": user_prompt}
]
response = self.get_response(messages)
return response
2.2 SQL评估模块
SQL评估模块 (sql_result.py) 负责验证生成的SQL语句是否能够正确执行,并评估其性能。
功能特点
- 连接数据库执行SQL
- 捕获执行错误并提供详细反馈
- 生成结果预览(Markdown格式)
- 性能监控和统计
核心逻辑
def get_markdown_result(self, session, sql):
try:
result = session.execute(text(sql))
columns = result.keys()
rows = result.fetchall()
if not rows:
return 'Yes', '查询结果为空'
# 构建markdown表格
markdown = '| ' + ' | '.join(columns) + ' |\n'
markdown += '| ' + ' | '.join(['---' for _ in columns]) + ' |\n'
for row in rows:
markdown += '| ' + ' | '.join(str(cell) for cell in row) + ' |\n'
return 'Yes', markdown
except Exception as e:
return 'No', f'SQL执行错误: {str(e)}'
2.3 智能代理模块
智能代理模块 (insurance_customer_assistant.py) 提供了一个更高级的接口,可以直接从数据文件读取,无需数据库连接。该模块基于Qwen-Agent框架构建,实现了更加智能化的交互体验。
设计优势
- 支持多种数据源(Excel文件)
- 提供丰富的查询工具
- 智能解析用户意图
- 无需数据库环境依赖
- 基于Qwen-Agent框架,支持工具调用
系统提示词设计
系统提示词是Qwen-Agent智能行为的核心,定义了助手的角色定位和能力范围:
system_prompt = """我是保险数据助手,我可以直接从Excel文件读取保险相关数据,无需数据库连接。
我的功能包括:
1. 查询客户信息(客户ID、姓名、性别、职业、联系方式等)
2. 查询保单信息(保单号、产品类型、保单状态、保费等)
3. 查询理赔信息(理赔号、理赔金额、理赔状态等)
4. 查询受益人、代理人、产品、员工等相关信息
我支持的查询方式:
- 根据客户姓名查询客户信息
- 根据客户ID查询保单信息
- 根据理赔金额范围查询理赔记录
- 通用查询(包含关键词的查询)
每当工具返回结果时,我会提供详细的分析和数据展示。
"""
系统提示词设计要点:
- 角色定义:明确助手的定位为保险数据助手
- 功能说明:详细列出所有支持的功能
- 查询方式:说明可用的查询方法
- 输出规范:指导助手如何展示结果
工具定义
Qwen-Agent通过工具定义实现功能扩展,以下是核心工具的定义:
tools = [
{
"name": "get_table_info",
"description": "获取所有表格的基本信息,包括表名、行数和列数",
"parameters": {}
},
{
"name": "query_insurance_data",
"description": "通用查询保险数据,支持客户、保单、理赔、受益人、代理人、产品、员工等信息的查询",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "查询语句,可以包含客户姓名、ID、保单号、金额范围等信息"
}
},
"required": ["query"]
}
},
{
"name": "get_customers_by_name",
"description": "根据姓名查询客户信息",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "客户姓名"
}
},
"required": ["name"]
}
},
{
"name": "get_policies_by_customer_id",
"description": "根据客户ID查询保单信息",
"parameters": {
"type": "object",
"properties": {
"customer_id": {
"type": "string",
"description": "客户ID"
}
},
"required": ["customer_id"]
}
},
{
"name": "get_claims_by_amount_range",
"description": "根据金额范围查询理赔信息",
"parameters": {
"type": "object",
"properties": {
"min_amount": {
"type": "number",
"description": "最小理赔金额"
},
"max_amount": {
"type": "number",
"description": "最大理赔金额"
}
},
"required": ["min_amount", "max_amount"]
}
}
]
工具定义的关键要素:
- 工具名称:唯一标识符,便于模型调用
- 功能描述:清晰说明工具的作用
- 参数定义:使用JSON Schema规范定义参数类型和要求
- 必需参数:明确标识哪些参数是必需的
工具注册与实现
每个工具都需要通过Qwen-Agent的装饰器进行注册:
@register_tool('get_table_info')
class GetTableInfoTool(BaseTool):
description = '获取所有表格的基本信息,包括表名、行数和列数'
parameters = [{
'name': 'args',
'type': 'object',
'description': '空参数',
'required': []
}]
def call(self, params: str, **kwargs) -> str:
result = insurance_assistant.get_table_info()
return result
这种设计模式的优点:
- 模块化:每个工具独立实现,便于维护
- 可扩展:可以轻松添加新的功能工具
- 标准化:统一的接口规范,便于模型理解
- 灵活性:支持复杂的参数组合和返回格式
3. 模型对比分析
我们使用了两种不同的大语言模型进行对比测试:
3.1 Qwen-turbo模型
- 特点:通用对话模型,对表结构理解能力强
- 优势:能够处理复杂的数据表结构描述
- 适用场景:表结构复杂、字段众多的场景
3.2 Qwen-coder模型
- 特点:专门优化的代码生成模型
- 优势:SQL语法准确性高,代码规范性好
- 适用场景:对SQL语法要求严格的场景
3.3 性能对比
- 生成速度:Qwen-turbo在处理复杂表结构时更稳定
- 准确性:Qwen-coder在SQL语法准确性方面表现更佳
- 适用性:根据具体场景选择合适的模型
4. 技术实现要点
4.1 SQL提取算法
def get_sql_code(self, response):
# 查找```sql和```之间的内容
pattern = r'```sql(.*?)```'
match = re.search(pattern, response.output.choices[0].message.content, re.DOTALL)
if match:
return match.group(1).strip()
else:
# 如果没有找到```sql标记,尝试查找任何```之间的内容
pattern = r'```(.*?)```'
match = re.search(pattern, response.output.choices[0].message.content, re.DOTALL)
if match:
return match.group(1).strip()
else:
# 如果没有找到任何代码块,返回整个响应
return response.output.choices[0].message.content
4.2 智能查询解析
系统通过关键词匹配自动识别用户的查询意图:
def _parse_query(self, query: str):
# 根据关键词识别查询表
table_mapping = {
'customerinfo': ['客户', 'customer', '姓名', 'name', '性别', 'gender'],
'policyinfo': ['保单', 'policy', '保单号', 'policy number', '投保'],
'claiminfo': ['理赔', 'claim', '理赔号', 'claim number', '理赔金额']
}
# 提取ID、姓名、金额等条件
# ...
return parsed_query
5. 评估方法
5.1 评估指标
- 语法正确性:SQL是否能被数据库正确解析
- 语义准确性:SQL是否正确回答了原始问题
- 执行效率:SQL执行时间和资源消耗
- 鲁棒性:对不同表达方式的适应能力
5.2 评估流程
- 使用SQL生成模块批量生成SQL语句
- 通过评估模块验证SQL执行结果
- 统计成功执行率和错误类型
- 分析性能瓶颈和优化方向
6. 实际应用效果
6.1 业务价值
- 降低技术门槛:业务人员无需SQL知识即可查询数据
- 提高工作效率:从小时级的查询开发缩短到秒级响应
- 减少错误:避免手动编写SQL时的语法和逻辑错误
6.2 使用场景
- 客户信息查询
- 保单状态跟踪
- 理赔数据分析
- 产品销售统计
7. 挑战与优化
7.1 主要挑战
- 复杂查询理解:多表关联、嵌套查询的解析
- 语义歧义处理:同义词、模糊表述的处理
- 性能优化:大规模数据查询的效率问题
7.2 优化策略
- 提示工程:优化系统提示词提高生成质量
- 后处理规则:添加SQL语法检查和优化规则
- 缓存机制:对常见查询进行缓存加速
8. 总结与展望
Text2SQL技术为企业智能化转型提供了重要支撑。通过本文的实现案例,我们可以看到该技术在简化数据访问、提高业务效率方面的显著价值。未来的发展方向包括:
- 模型优化:持续优化模型在特定领域的表现
- 多模态支持:结合图表、语音等多种输入方式
- 实时学习:支持用户反馈的在线模型优化
- 安全增强:加强SQL注入等安全防护能力
随着大语言模型技术的不断进步,Text2SQL技术将在更多业务场景中发挥重要作用,推动企业数据驱动决策的深度应用。
附录:代码结构说明
insurance-sql-colpilot/
├── sql_query_chat.py # 基于Qwen-turbo的SQL生成器
├── sql_query_coder.py # 基于Qwen-coder的SQL生成器
├── sql_result.py # SQL结果评估器
├── insurance_customer_assistant.py # 智能代理接口
├── results/ # 生成结果存储目录
└── data/ # 原始数据存储目录
该系统为Text2SQL技术的实际应用提供了一个完整的解决方案,可作为企业智能化数据访问的参考实现。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)