Spring AI--Prompt、多轮对话实现方案
摘要:Prompt工程是通过设计优化输入提示引导AI生成高质量输出的技术。核心内容包括提示词分类(按角色分为用户/系统/助手Prompt,按功能分为指令/对话/创意型等)、Token成本优化技巧(精简系统提示、清理对话历史等)以及基础与进阶提示技巧(明确任务角色、提供示例、思维链提示等)。系统架构设计涉及系统提示词、多轮对话实现(通过ChatMemory管理上下文)和ChatClient特性(支持
目录
1.指令型提示词(Instructional Prompts)
2.对话型提示词(ConversationalPrompts)
4.角色扮演提示词(Role-Playing Prompts)
1.思维链提示法(Chain-of-Thought, CoT)
Prompt工程
基本概念
Prompt工程(PromptEngineering)又叫提示词工程,简单来说,就是输入给Al的指令。
学习Prompt工程的目标是:通过精心设计和优化输入提示来引l导AI模型生成符合预期的高质量输出。
提示词分类
基于角色的分类
1.用户Prompt(UserPrompt)
这是用户向Al提供的实际问题、指令或信息,传达了用户的直接需求。用户Prompt告诉AI模型“做什么",比如回答问题、编写代码、生成创意内容等。
2.系统Prompt(SystemPrompt)
这是设置Al模型行为规则和角色定位的隐藏指令,用户通常不能直接看到。系统Prompt相当于给AI设定人格和能力边界,即告诉Al“你是谁?你能做什么?“。
不同的系统prompt可以让同一个AI模型表现出完全不同的应用特性。
3.助手Prompt(AssistantPrompt)
这是Al模型的响应内容。在多轮对话中,之前的助手回复也会成为当前上下文的一部分,影响后续对话的理解和生成。某些场景下,开发者可以主动预设一些助手消息作为对话历史的一部分,引导后续互动。
基于功能的分类
除了基于角色的分类外,我们还可以从功能角度对提示词进行分类,仅作了解即可。
1.指令型提示词(Instructional Prompts)
明确告诉Al模型需要执行的任务,通常以命令式语句开头。例:翻译以下文本为英文:春天来了,花儿开了。
2.对话型提示词(ConversationalPrompts)
模拟自然对话,以问答形式与Al模型交互。例:你认为人工智能会在未来取代人类工作吗?
3.创意型提示词(Creative Prompts)
引导 Al模型进行创意内容生成,如故事、诗歌、广告文案等。例:写一个发生在未来太空殖民地的短篇科幻故事,主角是一位机器人工程师。
4.角色扮演提示词(Role-Playing Prompts)
让 Al扮演特定角色或人物进行回答。例:假设你是爱因斯坦,如何用简单的语言解释相对论?
5.少样本学习提示词(Few-ShotPrompts)
提供一些示例,引I导Al理解所需的输出格式和风格。
将以下句子改写为正式商务语言:
示例1:
原句:这个想法不错。
改写:该提案展现了相当的潜力和创新性。
示例2:
原句:我们明天见。
改写:期待明日与您会面,继续我们的商务讨论。
现在请改写:这个价格太高了。
基于复杂度的分类
1.简单提示词(SimplePrompts)
单一指令或者问题,没有复杂的背景或者约束条件。例:什么是人工智能?
2.复合提示词(CompoundPrompts)
包含多个相关指令或步骤的提示词。例:分析下面这段代码,解释它的功能,找出潜在的错误,并提供改进建议。
3.链式提示词(ChainPrompts)
一系列连续的、相互依赖的提示词,每个提示词基于前一个提示词的输出。
第一步:生成一个科幻故事的基本情节。
第二步:基于情节创建三个主要角色,包括他们的背景和动机。
第三步:利用这些角色和情节,撰写故事的开篇段落。
4.模板提示词(TemplatePrompts)
包含可替换变量的标准化提示词结构,常用于大规模应用。
你是一位专业的{领域}专家。请回答以下关于{主题}的问题:{具体问题}。
回答应包含{要点数量}个关键点,并使用{风格}的语言风格。
Token
Token是大模型处理文本的基本单位,可能是单词或标点符号,模型的输入和输出都是按Token计算的,一般Token越多,成本越高,并且输出速度越慢。
Token成本优化技巧
1>精简系统提示词:移除冗余表述,保留核心指令。比如将“你是一个非常专业、经验丰富且非常有耐心的编程导师”简化为“你是编程导师"。
2>定期清理对话历史:对话上下文会随着交互不断累积Token。在长对话中,可以定期请求Al总结之前的对话,然后以总结替代详细历史。
3>使用向量检索代替直接输入:对于需要处理大量参考文档的场景,不要直接将整个文档作为Prompt,而是使用向量数据库和检索技术(RAG)获取相关段落。后续教程会带大家实战。
4>结构化替代自然语言:使用表格、列表等结构化格式代替长段落描述。
基础提示技巧
这部分是Prompt设计的“基本功”,解决“模型误解需求”的核心问题。
1.明确指定任务和角色
含义:告诉模型“做什么”(任务)和“扮演谁”(角色),避免模糊。
作用:模型会调整语气和内容,符合角色定位(如“小学老师” vs “资深程序员”)。
示例:“你是一名小学科学老师,需要用简单的语言解释‘为什么树叶会变黄’,适合6-8岁的孩子听。”(模型会用“比如秋天到了,树叶里的叶绿素宝宝睡觉了”这样的童趣表达)。
2.提供详细说明和具体示例
含义:给模型“参考样例”或“具体要求”,减少歧义。
作用:模型会模仿示例的结构/风格,输出更符合预期的结果。
示例:“写一个Python函数,接收一个列表,返回其中偶数的平方和。示例:输入[1,2,3,4],输出20(2²+4²=20)。”(模型会用列表推导式实现,如sum(x² for x in list if x%2==0))。
3.使用结构化格式引导思维
含义:用编号、 bullet 点、表格等结构化格式,引导模型“有序思考”。
作用:避免模型输出混乱,结构更清晰。
示例:“分析‘用户 churn’的原因,用以下结构:1. 可能的因素(如价格、服务);2. 每个因素的影响;3. 解决建议。”(模型会按“因素→影响→建议”的逻辑输出)。
4.明确输出格式要求
含义:指定模型的输出形式(如JSON、表格、markdown),方便后续处理。
作用:避免“自由发挥”,输出直接可用。
示例:“列出3个Python常用库及其用途,用JSON格式输出,键为‘库名’,值为‘用途’。”(模型会返回{"requests": "网络请求", "pandas": "数据处理", "matplotlib": "数据可视化"})。
进阶提示技巧
这部分是Prompt优化的“高阶思维”,解决“模型输出不深入”的问题。
1.思维链提示法(Chain-of-Thought, CoT)
含义:让模型“一步步写出思考过程”,再给出答案(如“首先分析问题→然后查找原因→最后得出结论”)。
作用:强制模型“慢思考”,减少错误(尤其适合逻辑推理题)。
示例:“解决数学题:2x + 5 = 15,要求写出思考过程。”(模型会输出“步骤1:两边减5得2x=10;步骤2:两边除以2得x=5;答案:x=5”)。
2.少样本学习(Few-Shot Learning)
含义:给模型1-3个示例,让它“模仿”示例的逻辑回答问题。
作用:无需大量数据,快速让模型适应特定任务(如代码生成、翻译)。
示例:“翻译以下句子为中文,示例:‘Hello, world’→‘你好,世界’;‘How are you?’→‘你好吗?’;现在翻译‘I love AI.’”(模型会输出“我喜欢AI”)。
3.分步指引(Step-by-Step)
含义:把复杂任务拆分成多个小步骤,引导模型逐步完成。
作用:避免模型“跳步”,输出更全面。
示例:“写一篇关于‘AI在医疗中的应用’的文章,步骤:1. 介绍AI医疗的背景;2. 举例说明‘影像诊断’和‘药物研发’的应用;3. 讨论挑战(如隐私);4. 总结未来趋势。”(模型会按步骤输出,结构清晰)。
4.自我评估和修正
含义:让模型“检查自己的回答”,并修正错误(如“请确认你的回答是否正确,若有错误请修正”)。
作用:减少模型的“自信错误”(如编造事实)。
示例:“回答‘中国的首都是哪里?’,然后检查是否正确。”(模型会输出“北京,正确”)。
5.知识检索和引用
含义:让模型调用外部知识(如最新数据、文献),并引用来源(如“请使用2023年的统计数据回答”)。
作用:提高回答的准确性和可信度(尤其适合需要实时数据的任务)。
示例:“2023年全球AI市场规模是多少?请引用来源。”(模型会输出“2023年全球AI市场规模约为1.3万亿美元(来源:Gartner)”)。
6.多视角分析(重点)
含义:让模型从多个角度/立场思考问题(如用户、商家、社会),输出更全面的结论。
核心价值:避免“单一视角偏见”,适合需要综合判断的任务(如政策评估、产品设计)。
示例:“分析快递柜超时收费’的影响,从消费者(方便性)、商家(效率)、快递员(工作量)三个角度回答。”(模型会输出:消费者:“觉得不方便,可能转向其他快递方式”;商家:“提高快递柜使用率,降低人工成本”;快递员:“减少等待时间,提高派件效率”)。
7.多模态思维
含义:让模型结合文本、图像、语音等多种形式回答问题(如“分析这张图片中的产品缺陷”)。
作用:拓展模型的“感知能力”,适合需要视觉信息的任务(如产品检测、医疗影像分析)。
示例:“请分析这张手机屏幕的图片,指出是否有划痕,并描述位置。”(模型会输出“屏幕左上角有一道约2cm的划痕”)。
AI应用方案设计
1.系统提示词设计
定义:系统提示是给A模型的初始指令,用于定义其角色、行为准则、回答风格,相当于给模型“定规矩”。
作用:
引导模型的语气(如"友好、专业");
限制回答范围(如"只回答Java技术问题");
规范输出格式(如“用bullet点列出步骤")。
示例:
// 用Spring AI的ChatClient设置系统提示
ChatClient chatClient = ChatClient.builder()
.model("gpt-4")
.systemPrompt("你是一个帮助用户解决Spring框架问题的助手,用简洁的语言解释,避免复杂术语。")
.build();最佳实践:
明确、具体(避免“你是一个助手“这种模糊描述);
包含角色定位(如"技术支持")、任务目标(如"解决配置问题")、输出要求(如"步骤清晰");
可动态调整(如根据用户身份切换提示,比如对新手更基础,对专家更深入)。
2.多轮对话实现
核心需求:多轮对话需要保持上下文(即记住用户之前的问题和模型的回答),否则模型会"断片”(比如用户问"它有哪些组件?”,模型不知道“它"指的是之前提到的"SpringAl")。
SpringAl的解决方式:通过ChatMemory(对话记忆)存储历史消息,让模型能理解上下文。
实现流程:
1>用户发送第1条消息(如"什么是SpringAl?");
2>模型返回回答(如"SpringAl是用于构建Al应用的Spring生态组件");
3>将用户消息和模型回答存储到ChatMemory中;
4>用户发送第2条消息(如"它有哪些组件?");
5>模型从ChatMemory中获取历史消息,理解“它"指"SpringAl",并回答组件列表。
ChatClient特性
定义:ChatClient是SpringAl中与LLM(大模型)交互的核心客户端,简化了调用复杂模型(如OpenAl、AzureOpenAl、Ollama)的流程。
核心特性:
1>简化API调用:无需手动构造HTTP请求,用链式API即可发送消息;
示例:
String response = chatClient.prompt()
.user("什么是Spring AI?")
.call()
.content(); // 获取模型回答的文本内容2>支持多模态:兼容文本、图像等输入(如GPT-4V);示例(发送图像+文本):
String response = chatClient.prompt()
.user("分析这张图片中的Spring配置文件问题", new File("application.yml"))
.call()
.content();3>集成ChatMemory:通过添加ChatMemoryAdvisor,自动管理上下文(见下文);
4>支持多LLM:切换模型只需修改配置(如从“gpt-4"改为"ollama/llama3");示例:
ChatClient ollamaClient = ChatClient.builder()
.baseUrl("http://localhost:11434") // Ollama本地服务地址
.model("llama3")
.build();Advisors(增强组件)
原理图:
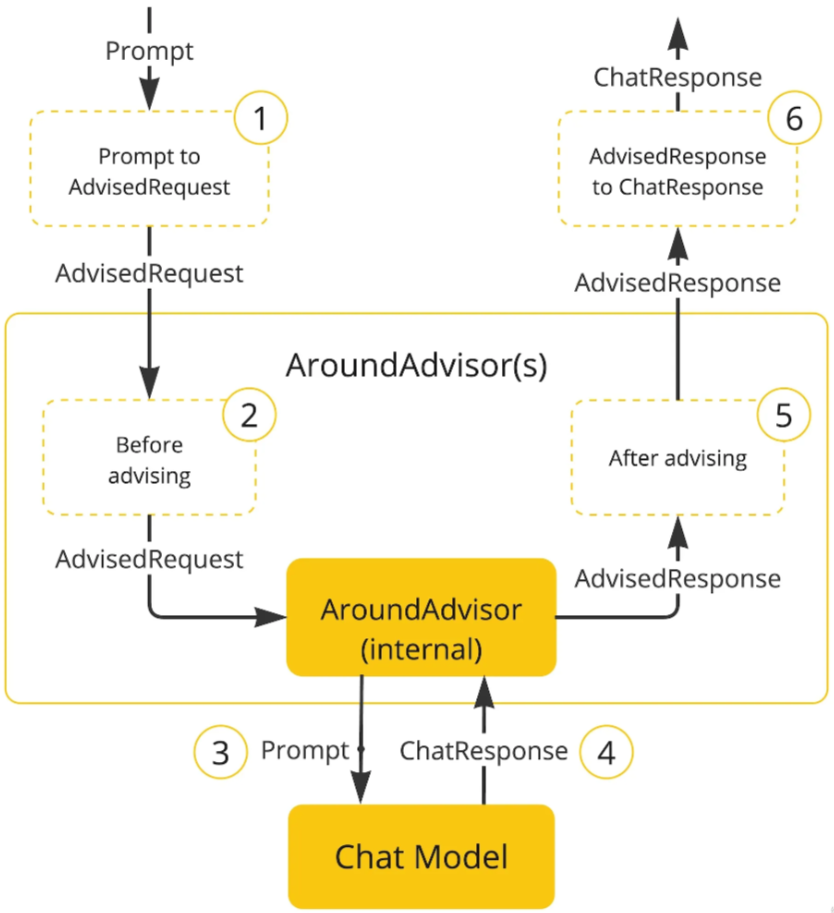
以Chat Memory Advisor为例
定义:Advisors是SpringAl中的切面组件(基于AOP),用于扩展ChatClient的功能(如自动管理上下文、记录日志、修改请求参数)。
ChatMemoryAdvisor的作用:自动将历史对话添加到当前请求中,无需手动拼接上下文。
工作流程:
1>用户发送新消息(如"它有哪些组件?");
2>ChatMemoryAdvisor拦截ChatClient的请求;
3>从ChatMemory中获取之前的对话历史(如"用户:什么是SpringAl?→模型:SpringAl是.");
4>将历史消息合并到当前请求的上下文中(如:“用户之前问了什么是SpringAl,现在问它的组件");
5>将修改后的请求发送给模型,模型基于完整上下文回答。示例(添ChatMemoryAdvisor):
// 1. 创建Chat Memory(内存存储,适合开发)
ChatMemory chatMemory = new InMemoryChatMemory();
// 2. 创建Chat Memory Advisor,关联Chat Memory
ChatMemoryAdvisor memoryAdvisor = new ChatMemoryAdvisor(chatMemory);
// 3. 将Advisor添加到ChatClient中
ChatClient chatClient = ChatClient.builder()
.model("gpt-4")
.addAdvisor(memoryAdvisor) // 自动管理上下文
.build();
// 4. 发送多轮消息(无需手动拼接历史)
String response1 = chatClient.prompt().user("什么是Spring AI?").call().content();
String response2 = chatClient.prompt().user("它有哪些组件?").call().content(); // 模型理解“它”指Spring AIChat Memory (对话记忆)
定义:ChatMemory是存储对话历史的组件,支持不同的存储方式(内存、Redis、数据库),用于多轮对话的上下文管理。
核心接口与实现:
ChatMemory(接口):定义了对话记忆的基本操作(如addMessage、getMessages、clear);
InMemoryChatMemory(内存存储):适合开发环境,重启后数据丢失;
RedisChatMemory(Redis存储):适合生产环境,支持分布式部署;
JdbcChatMemory(数据库存储):适合需要持久化的场景(如用户对话记录留存)。示例(使用Redis存储对话历史):
// 1. 配置Redis连接
RedisConnectionFactory redisConnectionFactory = new LettuceConnectionFactory("localhost", 6379);
// 2. 创建RedisChatMemory
ChatMemory chatMemory = new RedisChatMemory(
redisConnectionFactory,
"user:123" // 每个用户的对话历史用唯一键区分
);
// 3. 关联到Chat Memory Advisor
ChatMemoryAdvisor memoryAdvisor = new ChatMemoryAdvisor(chatMemory);总结:各组件的关系
系统提示:给模型“定规矩”,引导其行为;
ChatClient:是对话系统的"入口”,用于和模型交互;
ChatMemory:存储对话历史,解决多轮对话的"断片"问题;
ChatMemoryAdvisor:自动将历史对话添加到当前请求中,简化上下文管理;
多轮对话:通过上述组件的配合,实现“连续、连贯“的对话。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)