强化学习2.4 MDP作业汇总(持续更新)
考虑一个具有三个状态的马尔可夫决策过程(MDP),用于捕捉机器人足球的得分情况:无(None)、对方得分(Against)、我方得分(For),对应奖励分别为0、-1、+1(图3)。奖励函数仅与(即( r = r(s) ))。动作隐含了三个状态之间的上述转移概率,其中( * )表示任意三个状态。例如,(T(*, a,For) )是从任意状态出发,执行动作( a ),转移到“我方得分(For)”状态
问题1
考虑一个具有三个状态的马尔可夫决策过程(MDP),用于捕捉机器人足球的得分情况:无(None)、对方得分(Against)、我方得分(For),对应奖励分别为0、-1、+1(图3)。奖励函数仅与当前状态相关(即( r = r(s) ))。同时,考虑三种捕捉比赛策略的动作:
- 平衡(Balanced):我方得分概率5%;对方得分概率5%。
- 进攻(Offensive):我方得分概率25%;对方得分概率50%。
- 防守(Defensive):我方得分概率1%;对方得分概率2%。
动作隐含了三个状态之间的上述转移概率,其中( * )表示任意三个状态。例如,(T(*, a,For) )是从任意状态出发,执行动作( a ),转移到“我方得分(For)”状态的概率。

(1) 该MDP的策略总数是多少?
(2) 折扣因子为0.5时,使用策略迭代求解此MDP。提示:为便于手动计算,选择在所有状态下执行“平衡(Balanced)”动作作为初始策略。对于该状态-动作空间较小的问题,无需迭代执行策略评估,可直接一次性求解贝尔曼方程以获得价值。
(3) 对于给定的特定MDP,不同的折扣因子会改变最优策略吗?请给出充分的证明。一般情况下呢?
(1)
** 策略(policy)** 的定义:策略是从 “状态到动作的映射”,即每个状态下选择一个动作。
已知该 MDP 有 3 个状态(None、Against、For),每个状态下有 3 个可选动作(Balanced、Offensive、Defensive)。
对于每个状态,我们有 3 种动作选择;3 个状态的选择相互独立,因此策略总数为:3×3×3=3^3=27
(2)
这意味着由于该MDP的状态和动作数量极少,我们可以把贝尔曼方程转化为线性方程组,通过直接求解方程组的方式一次性得到状态价值,而不需要像常规策略评估那样进行迭代计算(比如迭代更新状态价值直到收敛)。
以问题(b)中的初始策略(所有状态选“Balanced”动作)为例,我们来具体解释:
贝尔曼方程的线性化
对于每个状态( s ),贝尔曼方程为:
Vπ(s)=r(s)+γ∑s′T(s,π(s),s′)Vπ(s′)V_{\pi}(s) = r(s) + \gamma \sum_{s'} T(s, \pi(s), s') V_{\pi}(s')Vπ(s)=r(s)+γ∑s′T(s,π(s),s′)Vπ(s′)
其中,Vπ(s)V_{\pi}(s)Vπ(s)是策略在状态( s )下选择的动作(这里所有状态都选“Balanced”),T(s,a,s′)T(s, a, s')T(s,a,s′)是转移概率。
由于状态只有3个(None、Against、For),我们可以将其表示为一个三元一次线性方程组:
{v1=0+0.5×(0.9v1+0.05v2+0.05v3)v2=−1+0.5×(0.9v1+0.05v2+0.05v3)v3=1+0.5×(0.9v1+0.05v2+0.05v3) \begin{cases} v_1 = 0 + 0.5 \times (0.9v_1 + 0.05v_2 + 0.05v_3) \\ v_2 = -1 + 0.5 \times (0.9v_1 + 0.05v_2 + 0.05v_3) \\ v_3 = 1 + 0.5 \times (0.9v_1 + 0.05v_2 + 0.05v_3) \end{cases} ⎩
⎨
⎧v1=0+0.5×(0.9v1+0.05v2+0.05v3)v2=−1+0.5×(0.9v1+0.05v2+0.05v3)v3=1+0.5×(0.9v1+0.05v2+0.05v3)
整理得到
{0.55v1−0.025v2−0.025v3=0−0.45v1+0.975v2−0.025v3=−1−0.45v1−0.025v2+0.975v3=1 \begin{cases} 0.55 v_1 - 0.025 v_2 - 0.025 v_3 = 0 \\ -0.45 v_1 + 0.975 v_2 - 0.025 v_3 = -1 \\ -0.45 v_1 - 0.025 v_2 + 0.975 v_3 = 1 \end{cases} ⎩
⎨
⎧0.55v1−0.025v2−0.025v3=0−0.45v1+0.975v2−0.025v3=−1−0.45v1−0.025v2+0.975v3=1
通过代数方法(如消元法、矩阵求逆)可直接解出:
V({None}) = 0, \quad V(\text{Against}) = -1, \quad V(\text{For}) = 1 ]
为何可以这样做?
当状态数量( n )很小时(比如本题( n=3 )),贝尔曼方程对应的线性方程组规模很小,直接求解的计算成本远低于迭代法。而当状态数量很大时(比如几十、上百个状态),迭代法(如值迭代、策略迭代的迭代评估)会更高效,因为直接求解大规模线性方程组的计算复杂度会急剧上升。
import numpy as np
def policy_iteration():
# 定义状态和动作
states = ['None', 'Against', 'For']
actions = ['Balanced', 'Offensive', 'Defensive']
state_index = {s: i for i, s in enumerate(states)}
action_index = {a: i for i, a in enumerate(actions)}
# 奖励函数:r(None)=0, r(Against)=-1, r(For)=1
r = np.array([0, -1, 1])
# 转移概率:T[动作][从任意状态][到状态]
# T[0] = Balanced: For=0.05, Against=0.05, None=0.9
# T[1] = Offensive: For=0.25, Against=0.5, None=0.25
# T[2] = Defensive: For=0.01, Against=0.02, None=0.97
T = np.array([
[[0.9, 0.05, 0.05], # Balanced: [None, Against, For]
[0.9, 0.05, 0.05],
[0.9, 0.05, 0.05]],
[[0.25, 0.5, 0.25], # Offensive
[0.25, 0.5, 0.25],
[0.25, 0.5, 0.25]],
[[0.97, 0.02, 0.01], # Defensive
[0.97, 0.02, 0.01],
[0.97, 0.02, 0.01]]
])
gamma = 0.5 # 折扣因子
theta = 1e-6 # 收敛阈值
# 初始策略:所有状态选择Balanced(索引0)
policy = np.zeros(len(states), dtype=int) # [0, 0, 0]
while True:
# 1. 策略评估:求解当前策略的状态价值V
V = np.zeros(len(states))
while True:
delta = 0
for s in range(len(states)):
v = V[s]
a = policy[s]
# 贝尔曼方程:V(s) = r(s) + gamma * sum(T(s,a,s')*V(s'))
V[s] = r[s] + gamma * np.dot(T[a, s], V)
delta = max(delta, abs(v - V[s]))
if delta < theta:
break
# 2. 策略改进
policy_stable = True
for s in range(len(states)):
old_action = policy[s]
# 计算所有动作的Q值
Q = []
for a in range(len(actions)):
q = r[s] + gamma * np.dot(T[a, s], V)
Q.append(q)
# 选择Q值最大的动作
new_action = np.argmax(Q)
if new_action != old_action:
policy_stable = False
policy[s] = new_action
# 检查策略是否稳定
if policy_stable:
break
return V, policy, states, actions
# 执行策略迭代
V, policy, states, actions = policy_iteration()
# 输出结果
print("最优状态价值:")
for i, s in enumerate(states):
print(f"V({s}) = {V[i]:.4f}")
print("\n最优策略:")
for i, s in enumerate(states):
print(f"在状态{s}下选择动作: {actions[policy[i]]}")
结果如下所示
(3)
1. 特定MDP的核心设定
- 奖励函数:仅与当前状态相关
r(None) = 0 ,r(Against) = -1, r(For) = +1 - 转移概率:仅与动作相关(与当前状态无关)
例如:动作Balanced在任意状态下,转移到For的概率为5%,Against为5%,None为90% - 最优状态价值:由问题(b)可知
r(None) = 0 ,r(Against) = -1, r(For) = +1
2. 证明:动作价值比较与gamma无关
(1)动作价值公式简化
动作价值( Q(s,a) )的定义为:
Q(s,a)=r(s)+γ∑s′T(a,s′)V∗(s′) Q(s,a) = r(s) + \gamma \sum_{s'} T(a,s') V^*(s') Q(s,a)=r(s)+γs′∑T(a,s′)V∗(s′)
由于转移概率( T(a,s’) )与当前状态( s )无关(题目中“*表示任意状态”),可令:
L(a)=∑s′T(a,s′)V∗(s′) L(a) = \sum_{s'} T(a,s') V^*(s') L(a)=s′∑T(a,s′)V∗(s′)
(( L(a) )为执行动作( a )后的长期奖励期望,仅与动作( a )相关)
因此,动作价值公式简化为:
Q(s,a)=r(s)+γ⋅L(a) Q(s,a) = r(s) + \gamma \cdot L(a) Q(s,a)=r(s)+γ⋅L(a)
这表明:同一状态下,不同动作的( Q )值差异仅由( L(a) )决定,与gammagammagamma无关。
(2)计算三种动作的( L(a) )
代入最优状态价值\ r(None) = 0 ,r(Against) = -1, r(For) = +1 :
-
动作Balanced:
L(Balanced)=T(∗,Balanced,None)⋅V∗(None)+T(∗,Balanced,Against)⋅V∗(Against)+T(∗,Balanced,For)⋅V∗(For) L(\text{Balanced}) = T(*, \text{Balanced}, \text{None}) \cdot V^*(\text{None}) + T(*, \text{Balanced}, \text{Against}) \cdot V^*(\text{Against}) + T(*, \text{Balanced}, \text{For}) \cdot V^*(\text{For}) L(Balanced)=T(∗,Balanced,None)⋅V∗(None)+T(∗,Balanced,Against)⋅V∗(Against)+T(∗,Balanced,For)⋅V∗(For)
=0.9×0+0.05×(−v)+0.05×v=0 = 0.9 \times 0 + 0.05 \times (-v) + 0.05 \times v = 0 =0.9×0+0.05×(−v)+0.05×v=0 -
动作Offensive:
L(Offensive)=0.25×0+0.5×(−v)+0.25×v=−0.25v L(\text{Offensive}) = 0.25 \times 0 + 0.5 \times (-v) + 0.25 \times v = -0.25v L(Offensive)=0.25×0+0.5×(−v)+0.25×v=−0.25v -
动作Defensive:
L(Defensive)=0.97×0+0.02×(−v)+0.01×v=−0.01v L(\text{Defensive}) = 0.97 \times 0 + 0.02 \times (-v) + 0.01 \times v = -0.01v L(Defensive)=0.97×0+0.02×(−v)+0.01×v=−0.01v
(3)对比( Q(s,a) )的大小
无论gamma∈[0,1)gamma \in [0,1)gamma∈[0,1)取何值,始终有:
L(Balanced)=0>L(Defensive)=−0.01v>L(Offensive)=−0.25v L(\text{Balanced}) = 0 > L(\text{Defensive}) = -0.01v > L(\text{Offensive}) = -0.25v L(Balanced)=0>L(Defensive)=−0.01v>L(Offensive)=−0.25v
结合Q(s,a)=r(s)+γ⋅L(a) Q(s,a) = r(s) + \gamma \cdot L(a) Q(s,a)=r(s)+γ⋅L(a) ,在所有状态下:
- None状态(( r=0 )):
Q(For,Balanced)=1+γ×0=1 Q(\text{For}, \text{Balanced}) = 1 + \gamma \times 0 = 1 Q(For,Balanced)=1+γ×0=1 ,大于另外两个动作的( Q )值(均为负数)。 - Against状态(( r=-1 )):
Q(For,Offensive)=1+γ×(−0.25v)=1−0.25γv Q(\text{For}, \text{Offensive}) = 1 + \gamma \times (-0.25v) = 1 - 0.25\gamma v Q(For,Offensive)=1+γ×(−0.25v)=1−0.25γv ,大于另外两个动作的( Q )值(更负)。 - For状态(( r=1 )):
Q(For,Defensive)=1+γ×(−0.01v)=1−0.01γv Q(\text{For}, \text{Defensive}) = 1 + \gamma \times (-0.01v) = 1 - 0.01\gamma v Q(For,Defensive)=1+γ×(−0.01v)=1−0.01γv ,大于另外两个动作的( Q )值(更小的正数)。
(4)结论
题目特定MDP中,折扣因子gamma不会改变最优策略,最优策略始终是“所有状态选择Balanced动作”。
| 场景 | 折扣因子是否改变最优策略 | 核心原因 |
|---|---|---|
| 题目特定MDP | 否 | 三种动作的长期奖励期望( L(a) )固定,Balanced的( L(a) )始终最大,与gamma无关 |
| 一般MDP | 可能 | gamma改变短期/长期奖励权重,当动作存在“短期-长期奖励权衡”时,最优策略变化 |
问题2
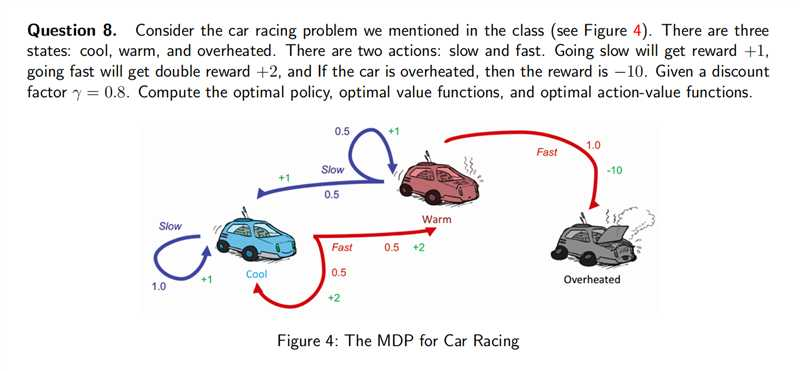
这是一个赛车MDP问题,问题描述如下:
| 维度 | 具体内容 |
|---|---|
| 状态 | Cool(凉爽)、Warm(温热)、Overheated(过热) |
| 动作 | Slow(慢速,奖励+1)、Fast(过热时奖励-10) |
| 转移概率 | - Cool:Slow→Cool(1.0);Fast→Cool(0.5)、Warm(0.5) - Warm:Slow→Cool(0.5)、Warm(0.5);Fast→Overheated(1.0) - Overheated:任何动作→Overheated(1.0) |
| 折扣因子 | gamma=0.8gamma = 0.8gamma=0.8 |
| 核心权衡 | 快速驾驶(高即时奖励)在 Warm 状态下会直接导致过热(100% 惩罚风险),需在 “短期高收益” 与 “避免不可逆故障惩罚” 间做选择 |
import numpy as np
def race_car_mdp_value_iteration():
# 1. 定义MDP核心参数
# 状态:0=Cool, 1=Warm, 2=Overheated
states = ["Cool", "Warm", "Overheated"]
n_states = len(states)
# 动作:0=Slow, 1=Fast
actions = ["Slow", "Fast"]
n_actions = len(actions)
# 奖励函数:rewards[状态][动作]
rewards = np.array([
[1, 2], # Cool状态:Slow=+1, Fast=+2
[1, 2], # Warm状态:Slow=+1, Fast=+2
[-10, -10] # Overheated状态:任何动作=-10
])
# 转移概率:trans_prob[动作][当前状态][下一状态]
trans_prob = np.array([
# 动作0:Slow
[
[1.0, 0.0, 0.0], # Cool→Cool (100%)
[0.5, 0.5, 0.0], # Warm→Cool(50%)、Warm(50%)
[0.0, 0.0, 1.0] # Overheated→Overheated (100%)
],
# 动作1:Fast
[
[0.5, 0.5, 0.0], # Cool→Cool(50%)、Warm(50%)
[0.0, 0.0, 1.0], # Warm→Overheated (100%)
[0.0, 0.0, 1.0] # Overheated→Overheated (100%)
]
])
gamma = 0.8 # 折扣因子
theta = 1e-6 # 收敛阈值(价值变化小于此值则停止迭代)
max_iter = 100 # 最大迭代次数(防止无限循环)
# 2. 初始化价值函数(所有状态初始值为0)
V = np.zeros(n_states)
iteration = 0
# 3. 值迭代主循环
while iteration < max_iter:
delta = 0 # 记录本轮最大价值变化
new_V = V.copy() # 存储新的价值函数
# 遍历每个状态,更新最优价值
for s in range(n_states):
# 计算当前状态下所有动作的价值
action_values = []
for a in range(n_actions):
# 贝尔曼最优方程:Q(s,a) = r(s,a) + γ * sum(T(s,a,s')*V(s'))
q = rewards[s, a] + gamma * np.dot(trans_prob[a, s], V)
action_values.append(q)
# 取最大动作价值作为当前状态的最优价值
new_V[s] = max(action_values)
# 更新最大价值变化
delta = max(delta, abs(new_V[s] - V[s]))
# 更新价值函数
V = new_V
iteration += 1
# 满足收敛条件则停止迭代
if delta < theta:
break
# 4. 推导最优策略(每个状态选择使Q值最大的动作)
optimal_policy = np.zeros(n_states, dtype=int)
# 推导最优动作价值函数Q*(s,a)
optimal_Q = np.zeros((n_states, n_actions))
for s in range(n_states):
for a in range(n_actions):
optimal_Q[s, a] = rewards[s, a] + gamma * np.dot(trans_prob[a, s], V)
# 选择Q值最大的动作(0=Slow,1=Fast)
optimal_policy[s] = np.argmax(optimal_Q[s])
# 5. 格式化输出结果
print("=" * 60)
print("赛车MDP问题求解结果(值迭代)")
print("=" * 60)
print(f"迭代次数:{iteration}")
print("\n1. 最优价值函数 V*:")
for s in range(n_states):
print(f"V*({states[s]}) = {V[s]:.4f}")
print("\n2. 最优策略 π*:")
policy_map = {0: "Slow", 1: "Fast"}
for s in range(n_states):
print(f"π*({states[s]}) = {policy_map[optimal_policy[s]]}")
print("\n3. 最优动作价值函数 Q*:")
for s in range(n_states):
print(f"\nQ*({states[s]}, ·):")
for a in range(n_actions):
print(f"Q*({states[s]}, {actions[a]}) = {optimal_Q[s, a]:.4f}")
print("=" * 60)
return V, optimal_policy, optimal_Q, states, actions
# 执行求解
V, optimal_policy, optimal_Q, states, actions = race_car_mdp_value_iteration()
代码执行结果如下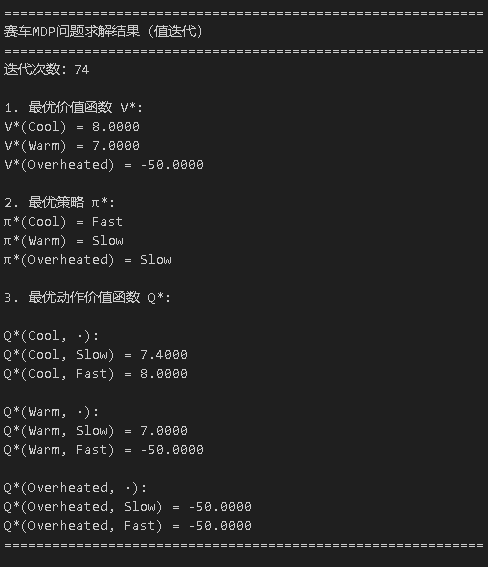

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)