使用Google AI Studio打造AI发型顾问:从想法到实现的全流程开发指南
教你仅用半小时开发一款AI发型顾问应用,包含智能发型推荐和发型融合两大核心功能,零成本快速实现从想法到落地的完整项目
文章目录
🍃作者介绍:25届双非本科网络工程专业,阿里云专家博主,专注于 AI 原理、AI 应用开发、AI 产品设计。大学期间具备扎实的 Java 后端基础,现从业于AI应用领域
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻github地址:XZL-CODE-AI-Hair-Stylist-and-Advisor
✈ 您的一键三连,是我创作的最大动力🌹
前言
近年来,AI图像生成技术突飞猛进,从DALL-E到Midjourney,再到最近的Google Nano Banana模型,这些模型不仅能够理解图像内容,更能根据用户的描述生成高质量的图像。
所以我也一直想探索如何将AI图像生成技术应用到实际场景中。
今天,我利用Google AI Studio开发了一款AI发型顾问应用,它能够分析用户的面部特征,提供个性化的发型推荐,并生成逼真的效果图。更重要的是,还支持"换发"功能——将任意参考发型无缝融合到用户的照片上。
本文将分享这个项目的完整开发过程,包括技术选型、核心实现、踩坑经验等,希望能给同样想探索AI应用开发的开发者们一些参考。
项目概述
核心功能
AI发型顾问应用主要包含两种模式:
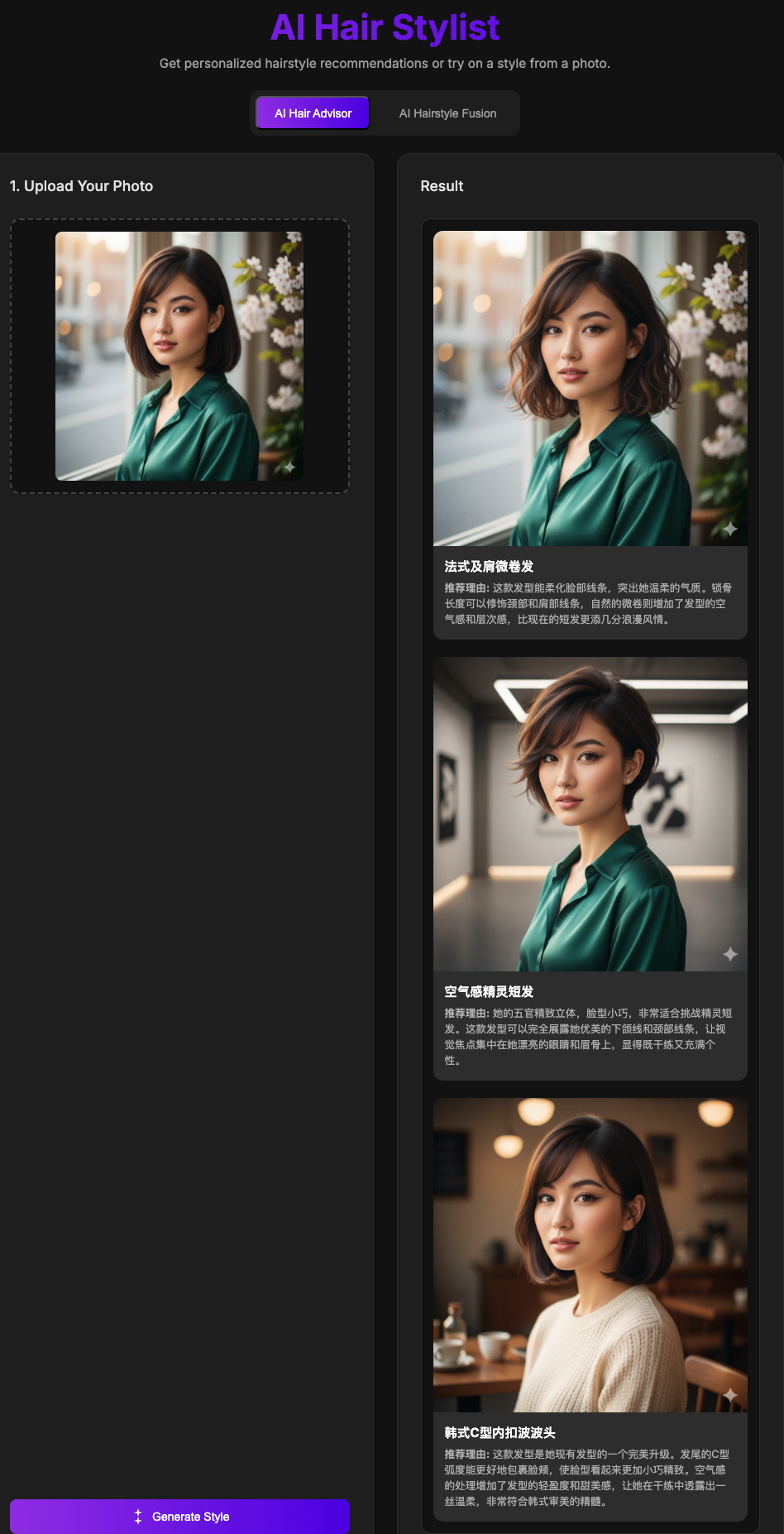
- AI发型顾问模式 - 智能分析用户面部特征,推荐3款个性化发型,并生成视觉效果图
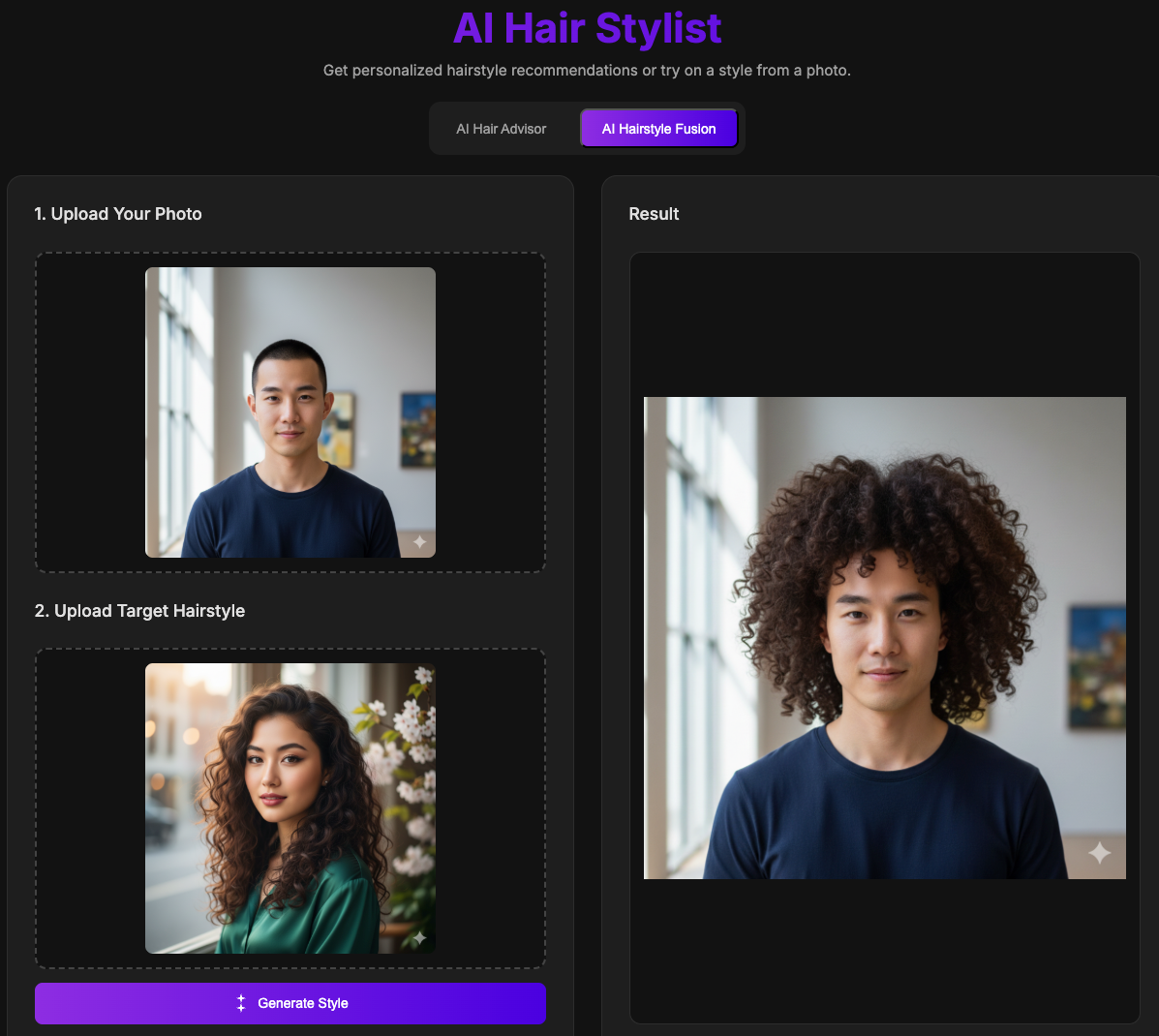
- AI发型融合模式 - 将参考图片中的任意发型无缝应用到用户照片上
技术栈
- 前端框架: React 19.2.0 + TypeScript
- 构建工具: Vite 6.2.0
- AI SDK: @google/genai 1.28.0
- AI模型:
gemini-2.5-pro: 用于文本分析和发型推荐gemini-2.5-flash-image: 用于图像生成
项目效果
声明:项目效果演示的图片,均为Google Nano Banana模型生成的AI人物,并非互联网人物图像
技术选型与架构设计
为什么选择Google Gemini和AI Studio?
没有为什么,模型能力强大就是唯一理由;
并且,AI Studio开发的项目还能免费使用谷歌模型功能,个人使用暂时无需付费。
架构设计
项目采用前后端分离的架构,但由于Gemini API的调用直接从浏览器端发起,所以没有独立的后端服务:
用户界面 (React + TypeScript)
↓
Google Gemini API (gemini-2.5-pro 分析 + gemini-2.5-flash-image 生成)
↓
返回结果 (JSON文本 + Base64图像)
↓
UI展示 (图片 + 推荐理由)
这种架构的优势:
- 简单直接:无需后端服务器,成本低
- 响应快速:减少中间环节,用户体验好
- 易于部署:可以直接部署到GitHub Pages、Vercel等静态托管平台
核心功能实现
1. 环境配置
假如这个项目你要独立部署去上线的话:
首先,我们需要获取Google Gemini API密钥:
- 访问 Google AI Studio
- 创建新的API密钥
- 将密钥配置到项目中
重要提示:API密钥是敏感信息,务必使用环境变量存储。
# .env.local
GEMINI_API_KEY=your_api_key_here
// vite.config.ts
import { defineConfig, loadEnv } from 'vite';
export default defineConfig(({ mode }) => {
const env = loadEnv(mode, '.', '');
return {
define: {
'process.env.API_KEY': JSON.stringify(env.GEMINI_API_KEY),
},
};
});
2. AI发型顾问模式实现
这是项目的核心功能,采用两阶段处理的方式:
阶段1:AI分析 + 文本推荐
首先,我们调用gemini-2.5-pro模型分析用户照片,并生成发型推荐:
const textModelResponse = await ai.models.generateContent({
model: 'gemini-2.5-pro',
contents: {
parts: [{
inlineData: { data: userImageBase64, mimeType: userImage.file.type }
}, {
text: `你是一位专业的AI发型顾问。请仔细分析照片中人物的脸型和五官特点,然后推荐3款适合的发型。
严格按照下面描述的JSON格式进行响应。
对于每款发型,请提供:
- styleName: 发型名称 (中文)
- description: 一句话描述 (中文)
- reason: 推荐理由 (中文)
- imagePrompt: 一个给图片生成模型使用的**英文**提示词
...`
}]
},
config: {
responseMimeType: "application/json",
responseSchema: {
type: Type.OBJECT,
properties: {
recommendations: {
type: Type.ARRAY,
items: {
type: Type.OBJECT,
properties: {
styleName: { type: Type.STRING },
description: { type: Type.STRING },
reason: { type: Type.STRING },
imagePrompt: { type: Type.STRING }
}
}
}
}
}
}
});
const recommendations = JSON.parse(textModelResponse.text).recommendations;
关键技术点:
- 使用
responseMimeType: "application/json"确保返回结构化数据 - 使用
responseSchema定义JSON结构,强制模型按格式输出 imagePrompt特别重要,它是第二阶段图像生成的提示词
阶段2:批量图像生成
接下来,我们为每个推荐发型生成视觉效果图:
const imageGenerationPromises = recommendations.map(async (rec, index) => {
setLoadingMessage(`正在生成发型 ${index + 1}/${recommendations.length}: ${rec.styleName}...`);
const imageResponse = await ai.models.generateContent({
model: 'gemini-2.5-flash-image',
contents: {
parts: [
{ inlineData: { data: userImageBase64, mimeType: userImage.file.type } },
{ text: rec.imagePrompt },
]
},
config: { responseModalities: [Modality.IMAGE] }
});
const candidate = imageResponse.candidates?.[0];
const part = candidate?.content?.parts?.find(p => p.inlineData);
if (part?.inlineData) {
return `data:${part.inlineData.mimeType};base64,${part.inlineData.data}`;
}
return undefined;
});
const generatedImages = await Promise.all(imageGenerationPromises);
setAdvisorResults(recommendations.map((rec, i) => ({
...rec,
generatedImage: generatedImages[i]
})));
关键技术点:
- 使用
gemini-2.5-flash-image专门用于图像生成 responseModalities: [Modality.IMAGE]指定只返回图像Promise.all并发处理多个图像生成任务,提高效率- 返回的图像是Base64格式,可以直接用于
<img>标签
3. AI发型融合模式实现
融合模式相对简单,直接将两张图片输入给模型:
const response = await ai.models.generateContent({
model: 'gemini-2.5-flash-image',
contents: {
parts: [
{ inlineData: { data: userImageBase64, mimeType: userImage.file.type } },
{ inlineData: { data: targetImageBase64, mimeType: targetImage.file.type } },
{ text: "Apply the hairstyle from the second image onto the person in the first image. Blend it seamlessly and realistically, matching the hair to the person's head shape, face, and skin tone." }
]
},
config: { responseModalities: [Modality.IMAGE] }
});
关键技术点:
- 多图像输入:同时传入用户照片和参考发型照片
- 清晰的英文指令:告诉模型如何执行融合任务
4. 用户体验优化
文件上传处理
使用拖拽上传功能,提升用户体验:
const handleDrop = useCallback((e: React.DragEvent<HTMLDivElement>) => {
e.preventDefault();
e.stopPropagation();
setIsDragging(false);
if (e.dataTransfer.files?.[0]) {
onUpload(e.dataTransfer.files[0]);
}
}, [onUpload]);
const onFileChange = (e: React.ChangeEvent<HTMLInputElement>) => {
if (e.target.files?.[0]) {
onUpload(e.target.files[0]);
}
};
图片Base64转换
将上传的文件转换为Base64,以便传递给API:
const toBase64 = (file: File): Promise<string> =>
new Promise((resolve, reject) => {
const reader = new FileReader();
reader.readAsDataURL(file);
reader.onload = () => resolve(reader.result as string);
reader.onerror = error => reject(error);
});
加载状态管理
提供清晰的加载反馈:
const [loading, setLoading] = useState<boolean>(false);
const [loadingMessage, setLoadingMessage] = useState<string>('');
// 在生成过程中更新提示信息
setLoadingMessage('Analyzing your features...');
setLoadingMessage(`Generating style ${index + 1}/${recommendations.length}: ${rec.styleName}...`);
项目开源
本项目已完全开源,欢迎Star和Fork!
GitHub仓库: https://github.com/XZL-CODE/AI-Hair-Stylist-and-Advisor
快速开始:
# 克隆项目
git clone https://github.com/XZL-CODE/AI-Hair-Stylist-and-Advisor.git
cd AI-Hair-Stylist-and-Advisor
# 安装依赖
npm install
# 配置API密钥(创建.env.local文件)
echo "GEMINI_API_KEY=your_api_key_here" > .env.local
# 启动开发服务器
npm run dev
写在最后
感谢你能看到这里,那么,这个项目开发耗费了多少时间和精力呢?
答案是:半小时
这个AI发型顾问项目从想法到实现,前后历时一小时左右。
最重要的是,整个过程零成本,全部在Google AI Studio自动完成。
那么开发这个东西,有什么门槛吗?
大家不要觉得开发这个东西很简单,其实背后有非常高的技术门槛!
你看,表面上看起来只要半个小时、零成本,但真正能把AI、自动化、平台能力结合起来,背后需要对AI算法、产品架构、平台集成有非常深刻的理解。不是说随便谁都能做,技术壁垒还是非常高的! 我们团队能做出来,也是因为长期在AI和产品创新上持续投入。所以说,这里面的技术含量,其实非常高!
毫无技术壁垒,仅需一个非常简单的prompt(这个prompt甚至还是AI写的),这就分享给你:
我要开发一个项目,一个项目里面综合了下面两个大的功能,两个功能和起来作为这个我要的项目。
你是一个发型AI顾问。请根据用户上传的正面照片,自动分析用户的脸型、头型、五官特征,并结合流行趋势和适配原则,推荐3~5种最适合该用户的发型风格(如短发、长发、卷发、直发、刘海、无刘海等)。并用nano
banana等AI发型生成模型,将推荐的每一种发型自然地“戴”在用户照片上,生成对应的合成照片。要求发型与用户脸部、头发边缘无缝自然融合,整体效果真实美观。输出包括:每种推荐发型的风格描述、适合理由,以及合成后的发型效果图。你是一个专业AI发型设计师。用户会上传自己的正面照片和一张目标发型(如明星照片、杂志发型图等)。请用nano
banana等AI发型融合模型,把目标发型自然地融合到用户的照片上,生成一张用户“换上”该发型的真实效果图。要求合成效果发型与用户脸型、肤色、头型、边缘过渡自然,整体照片真实美观。输出为:合成后的发型照片,以及必要时的发型适配建议。
如果本文对你有帮助,欢迎点赞收藏转发三连,有问题也欢迎在评论区讨论!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)