深度剖析Figure 03:人形机器人从实验室到量产的技术破壁者
在继Figure 02机器人在特斯拉工厂工作500天后,Figure AI公司有推出了家用场景下的Figure 03机器人,下面我们一起来看看这次推出的Figure 03机器人如何。
在继Figure 02机器人在特斯拉工厂工作500天后,Figure AI公司有推出了家用场景下的Figure 03机器人,下面我们一起来看看这次推出的Figure 03机器人如何。
一、Figure 03机器人是什么
2025年10月9日,美国人形机器人公司Figure AI正式发布第三代产品Figure 03,这是一款定位家庭服务与大规模制造的全电动人形机器人。它以168厘米的身高、60公斤的自重,实现了20公斤负载能力,最高运行速度达1.2米/秒,单次续航约5小时,支持无线感应充电。
作为Figure品牌的“量产化里程碑”,03代机器人在硬件设计、AI系统和制造体系上进行了全面革新,目标是打破人形机器人“实验室原型”的桎梏,成为首款真正面向消费市场和工业场景的可规模化产品。
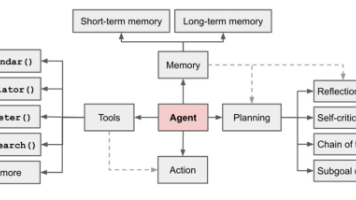
二、Figure 03机器人的亮点
1. 硬件:从“能做动作”到“会做事情”的感知革命
-
触觉交互突破:指尖集成3克压力感知的柔性触觉传感器(精度相当于感知一枚回形针的重量),可实现鸡蛋、扑克牌等易碎/轻薄物体的无损抓取,解决了人形机器人“有力无细”的行业痛点。
Figure 03机器人抓取实物演示视频
-
多模态视觉系统:手掌内置120°广角低延迟摄像头,在橱柜、缝隙等狭窄空间操作时提供冗余视觉数据,配合头部主摄像头实现“全局+局部”的立体感知。
Figure 03机器人全局感知
-
安全与易用性:采用多层软质材料与防夹结构,重量较上一代降低9%;电池通过UN38.3安全认证,支持无线充电与自动回充,完全适配家庭环境的无人化运维。
Figure 03机器人整体细节
2. AI:Helix系统的“人类级学习能力”
Figure 03搭载自研Helix视觉-语言-动作(VLA)模型,采用“双层次架构”:
- System 1:以200Hz的高频输出全身控制指令,实现实时力控与运动规划;
- System 2:通过人类示教视频进行语义推理,支持“看一遍就会”的跨任务泛化(如观察人类摺衣服后,可自主应用于不同衣物)。
这里详细解释一下Helix视觉-语言-动作(VLA)模型:
Helix视觉-语言-动作(VLA)模型:人形机器人的“双脑”智能引擎
Helix是美国Figure AI公司专为第三代人形机器人Figure 03研发的端到端视觉-语言-动作(VLA)通用大模型,于2025年2月正式发布。作为连接机器人感知、认知与执行的核心“大脑”,它通过突破性的双层架构设计,解决了传统机器人在“实时响应”与“复杂推理”之间的固有矛盾,实现了从自然语言指令到物理世界动作的直接映射,为家庭服务、工业物流等场景的商业化落地奠定了技术基础。
一、核心定位:
破解人形机器人的“智能悖论” 人形机器人长期面临一个关键困境:高精度的实时动作控制需要毫秒级响应速度,而复杂场景的语义理解与任务规划则依赖深度推理能力,两者在算力需求与处理节奏上存在天然冲突。Helix的核心使命便是通过架构创新打破这一悖论——它既能让机器人像人类一样“快速反应”,又能实现“深度思考”,最终达成“听得懂、看得清、做得对”的一体化能力。
作为FigureAI从“原型机研发”转向“量产化落地”的核心技术支撑,Helix的设计完全服务于实际场景需求:家庭环境中需应对数千种未知物体与动态干扰,工业场景中需实现高速精准的协作操作,这些都要求模型兼具泛化性、实时性与可靠性。
二、核心架构:
“快慢双脑”的认知分层设计 Helix最具革命性的创新在于采用**“系统1(S1)+ 系统2(S2)”的解耦式双层架构**,模拟人类大脑的“直觉反应”与“理性思考”分工,实现不同认知层级的高效协同。
1. 系统2(S2):
慢思考的“战略决策者” 作为模型的“高层大脑”,系统2是基于Transformer架构的视觉-语言-动作(VLA)模型,采用70亿参数的开源视觉语言模型(VLM)作为基础,专注于语义理解、场景推理与目标规划。
- 运行特性:以每秒7-9次的低频输出指令,无需追求毫秒级响应,转而聚焦“做什么”和“为什么做”的战略判断。
- 核心能力:
- 接收头部主摄像头的图像数据、机器人关节状态信息与自然语言指令(如“抓起桌上的玻璃杯”);
- 结合互联网预训练的常识知识,解析指令语义、识别场景中的关键物体(如区分“玻璃杯”与“陶瓷碗”)、规划整体动作路径(如“先移动躯干→再调整手腕角度→最后闭合手指”);
- 输出包含目标意图的语义向量,传递给系统1作为动作执行的“总纲领”。
2. 系统1(S1):
快反应的“战术执行者” 作为模型的“底层大脑”,系统1是轻量化的混合注意力卷积模型,仅含8000万参数(约为系统2的1/1000),专注于实时动作生成与精准控制。
- 运行特性:以每秒200次的高频输出动作指令,相当于每5毫秒更新一次关节控制信号,完美匹配机器人驱动器的响应需求。
- 核心能力:
- 同步接收掌部摄像头的近距离视觉数据、指尖触觉传感器信号、机器人当前姿态信息,以及系统2输出的语义向量;
- 通过卷积网络快速提取局部视觉特征(如物体边缘、表面纹理),结合交叉注意力机制融合多模态数据,将高层目标拆解为具体的关节动作(如“食指弯曲30度”“手腕旋转15度”);
- 具备动态纠错能力:若触觉传感器检测到物体有滑落趋势(如感知压力降至3克以下),可在10毫秒内调整抓握力度,无需等待系统2的指令反馈。
3. 双系统协同逻辑
两者通过“目标-执行-反馈”的闭环实现高效协作:系统2如同“指挥官”,基于全局信息制定作战计划;系统1如同“特种兵”,根据现场情况实时执行战术动作,同时将执行过程中的异常数据(如抓取失败、物体滑落)回传至系统2,触发目标调整。这种分工既保证了动作的实时性,又确保了决策的合理性,解决了传统单一模型“快则不精、精则不快”的难题。
三、关键技术突破:
重新定义VLA模型的能力边界 Helix在模型通用性、数据效率与部署灵活性上实现了多重突破,显著降低了人形机器人的商业化门槛。
1. 单网络通用控制:
“一脑通百艺” 传统机器人模型需针对不同任务(如抓取、开关抽屉、协作搬运)进行单独微调,而Helix采用单一神经网络权重集覆盖所有上身动作控制——从拾取鸡蛋等精细操作,到开关冰箱、跨机器人协作等复杂任务,均无需修改模型参数。这种通用性源于其对“视觉-语言-动作”三元关系的端到端建模,直接学习从“场景感知”到“动作序列”的映射规律,而非依赖人工定义的动作规则。
2. 数据效率革命:
小数据实现大能力 传统VLA模型训练需数千小时的标注数据,而Helix仅需500小时的监督数据即可达到商用级性能,核心秘诀在于“自动化标注+高质量筛选”策略:
- 自动化标注:模型可根据机器人摄像头捕捉的操作视频,反向生成自然语言描述(如“从抽屉中取出勺子”),大幅减少人工标注成本;
- 高质量筛选:优先保留包含纠错行为的演示数据(如抓取失败后调整姿势的过程),剔除冗余无效样本,使少量数据即可覆盖多样化的边界场景。在物流包裹分拣场景中,仅8小时的精选数据便实现了超过人类演示者的操作效率。
3. 嵌入式实时运行:
摆脱云端依赖 Helix可完全部署在机器人搭载的低功耗嵌入式GPU上,无需依赖云端算力支持。这一特性源于其架构的轻量化设计:系统1的卷积网络计算开销仅为传统Transformer模型的1/20,系统2则通过模型量化技术降低显存占用,两者协同运行时的功耗不足20瓦,完全满足家庭与工业场景的续航需求。
4. 多机器人协作能力
作为首个支持跨机器人协同的VLA模型,Helix可同时在两台Figure 03上运行,通过无线数据同步实现任务分配与动作协调。例如在物流分拣场景中,一台机器人负责抓取包裹,另一台负责调整标签方向,两者通过共享系统2的场景推理结果,实现无延迟协作,吞吐量较单机器人提升60%。
四、典型应用场景:
从实验室走向真实世界 Helix的技术特性使其在家庭服务与工业物流两大核心场景中展现出极强的实用性。
1. 家庭服务场景:理解复杂需求,应对未知环境
- 自然语言交互:用户仅需说出“把餐桌上的扑克牌整理好”,系统2即可解析指令语义,识别“扑克牌”的物体属性与“整理”的动作目标;系统1则结合掌部摄像头的视觉数据与指尖触觉反馈,精准抓取单张扑克牌(成功率超99%),并按顺序排列。
- 未知物体泛化:面对训练中未见过的新型厨具,系统2可通过视觉语言模型的常识推理(如“形状类似铲子,推测用于翻炒”),指导系统1采用合适的抓握姿势,无需额外编程。
- 安全容错:若在移动过程中检测到障碍物(如突然出现的宠物),系统1可立即触发急停动作(响应时间<20毫秒),同时系统2重新规划路径,兼顾效率与安全。
2. 工业物流场景:
高速精准,适应动态环境 在包裹分拣任务中,Helix通过隐立体视觉与运动模式加速技术实现高效操作:
- 系统1的立体视觉网络可精准识别包裹的3D轮廓与运动轨迹,即使面对可变形的软质包裹,也能确定最佳抓取点;
- 采用“动作块重采样”技术,将训练中的动作序列线性加速50%,使包裹处理速度超过人类演示者,同时保持95%以上的抓取成功率;
- 支持跨机器人策略迁移:在一台机器人上训练的模型,可直接应用于其他机器人,通过“视觉本体感受”模块自动校准硬件差异,无需重新标定。
五、行业影响:
推动人形机器人进入“量产智能时代” Helix的发布不仅是Figure 03的核心竞争力,更为人形机器人产业树立了技术标杆:
- 对技术路线:证明“解耦式双层架构”是平衡实时性与通用性的最优解,可能成为行业主流设计范式;
- 对成本控制:通过数据效率提升与嵌入式部署,将机器人的AI系统研发成本降低70%,为量产化奠定基础;
- 对商业化节奏:使机器人从“特定任务演示”走向“多场景实用化”,加速家庭服务、物流仓储等领域的落地进程。
正如行业评价所言,Helix的突破标志着具身智能从“实验室理论”走向“商业实践”,它让Figure
03不仅是一台硬件设备,更是一个能够持续学习、适应环境的智能体——而这正是人形机器人真正走进人类生活的关键一步。3. 量产:从“手工样机”到“工业流水线”的跨越
- 制造工艺革新:摒弃传统CNC精密加工,采用压铸、注塑、冲压等规模化工艺,建立专属制造基地“BotQ”,初期年产能达1.2万台,未来四年目标量产10万台。
- 成本控制:通过工艺简化与规模效应,将硬件成本压缩至“可商业化区间”(具体售价未公布,但团队强调“家庭用户可负担”)。
三、Figure机器人的发展历程
Figure AI自2022年成立以来,以“三年三代”的迭代速度,完成了从“技术验证”到“量产落地”的跃迁:
-
原型机阶段(2022-2023):推出实验性机型,验证人形机器人的基本运动能力,但依赖手工装配,成本高昂且稳定性不足。
-
01/02代(2023-2024):逐步优化硬件可靠性,重点突破双足行走与基础操作,但仍属于“实验室产品”,未解决量产与成本问题。

-
03代(2025):核心目标转向“规模化交付”,通过制造工艺革新、AI系统升级和安全设计,真正具备家庭与工业场景的落地能力,标志着Figure从“技术公司”向“产品公司”的转型。

四、Figure 03在技术上的突破
1. 触觉传感:从“感知存在”到“感知细节”
Figure 03的指尖触觉技术,是其最具革命性的突破之一。其柔性触觉传感器采用“分层感知+动态响应”设计:
-
结构灵感:在这方面可以借鉴专利《柔性可拉伸触觉传感器》(CN115112270A)的“凸起压力结构+长条拉力结构”分层架构,通过聚酰亚胺基底与碳纳米管电极的纳米级材料组合,实现3克压力的高灵敏度。

-
算法支撑:由于并没有公开其源码,所以可参考约翰霍普金斯大学《Science Advances》中“仿生假手纹理识别”与伦敦玛丽女王大学“L³F-TOUCH传感器”的研究,其中通过“力-形变-滑动”的多维度数据融合,可以实现对物体滑落的预判与抓握力度的动态调整。
2. 多模态感知:“眼睛+手掌”的立体认知
掌部摄像头与头部视觉的协同,突破了传统机器人“视觉盲区”的限制:
- 硬件设计:与上海交大《Nature Communications》中“TacPalm-SoRoHand”的设计思路类似,通过掌部摄像头的弹性体形变重建技术,实现亚毫米级物体形貌感知。
- 算法融合:这部分与戴盟机器人“DM-Tac W”传感器的多模态数据处理逻辑十分相似,将掌部视觉、指尖触觉、关节位置数据实时融合,在橱柜取物、卡片抽取等场景中实现“盲操作”级精度。
3. AI系统:从“指令执行”到“自主学习”
Helix系统的双层次架构,重新定义了人形机器人的智能边界:
- System 1(实时控制):采用类似特斯拉FSD的“纯视觉+神经运动规划”的流程,以200Hz的频率输出关节扭矩指令,确保运动的流畅性与安全性。
- System 2(语义推理):通过“人类示教视频+语言指令”的训练范式,实现任务的跨场景泛化(如学会摺T恤后,可自主迁移到摺衬衫)。这一思路与CoRL 2024最佳论文《D(R,O) Grasp》的“手-物交互表征”异曲同工,通过对比学习实现跨物体的泛化抓取。
4. 量产技术:从“实验室珍品”到“工业产品”
Figure 03的制造革新,为行业提供了“规模化降本”的可行路径:
- 工艺替代:以压铸、注塑替代CNC加工,使单个结构件的制造成本降低70%以上,生产效率提升10倍。
- 供应链整合:建立“传感器-执行器-结构件”的垂直供应链,如与触觉传感器供应商联合开发量产级柔性传感模组,解决了“实验室技术无法量产”的行业痛点。
总结:技术破壁者的行业影响
Figure 03的发布,标志着人形机器人正式从“技术演示”进入“商业落地”阶段。其技术突破不仅体现在硬件与算法的单点创新,更在于**“技术-产品-商业”的闭环验证**:
- 对供应链:推动触觉传感器、广角摄像头、高扭矩执行器等零部件的量产化,加速行业基础设施成熟;
- 对应用场景:首次将“家庭服务”从概念变为可交付的产品,为清洁、烹饪等场景提供“人力替代”的可行方案;
- 对行业竞争:以“量产能力”重新定义赛道规则,迫使同行从“技术比拼”转向“成本与交付能力的较量”。
Figure 03的真正价值,不在于它是“最先进的机器人”,而在于它证明了人形机器人可以像智能手机一样规模化生产、走进千家万户——这一步,或将成为行业从“实验室狂欢”到“产业革命”的转折点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)