【收藏必备】一文掌握RAG技术:大模型检索增强生成的理论与实践
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将大规模语言模型(LLM)与外部知识源检索相结合的人工智能技术框架,旨在提高模型的问答和生成能力。它通过从外部知识库中检索相关信息来增强语言模型的输出,从而生成更准确、更丰富上下文的响应。实际上,RAG的本质是InContext Learning,即RAG(检索增强生成) = 检索技术 + LLM 提示。同样
RAG(检索增强生成)是一种结合大语言模型与外部知识检索的技术,旨在解决LLM的知识局限和幻觉问题。文章系统介绍了RAG的三种发展阶段(Naive、Modular、Agentic)、基本流程(知识库整理、嵌入、索引、检索、生成),并通过医疗问诊场景展示了实践应用。最后详述了RAG评估方法和优化方向,为读者提供了从理论到实践的完整指南。
RAG介绍
RAG概念
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将大规模语言模型(LLM)与外部知识源检索相结合的人工智能技术框架,旨在提高模型的问答和生成能力。它通过从外部知识库中检索相关信息来增强语言模型的输出,从而生成更准确、更丰富上下文的响应。实际上,RAG的本质是InContext Learning,即 RAG(检索增强生成) = 检索技术 + LLM 提示。
同样地,RAG最主要的目标是为了增强LLM能力来抵消LLM的知识局限、幻觉问题和数据安全三大局限性。并且,RAG 通常来说还是省略了模型微调的成本,能更快基于语义做专有领域的热装卸(即在系统运行过程中,在不切换模型的同时,通过动态地加载、更新或切换知识库达到不同垂域的知识参考效果)。
RAG分类
在介绍完RAG的概念后,想必大家已经清楚具体RAG的作用了。这些关键节点也随着大模型的发展在不断变化着,因此可以根据发展阶段将RAG分成如下三类(也代表RAG主要的发展阶段)包括经典的NaiveRAG、模块化的ModularRAG和智能体基座的RAG,具体框架如下图。
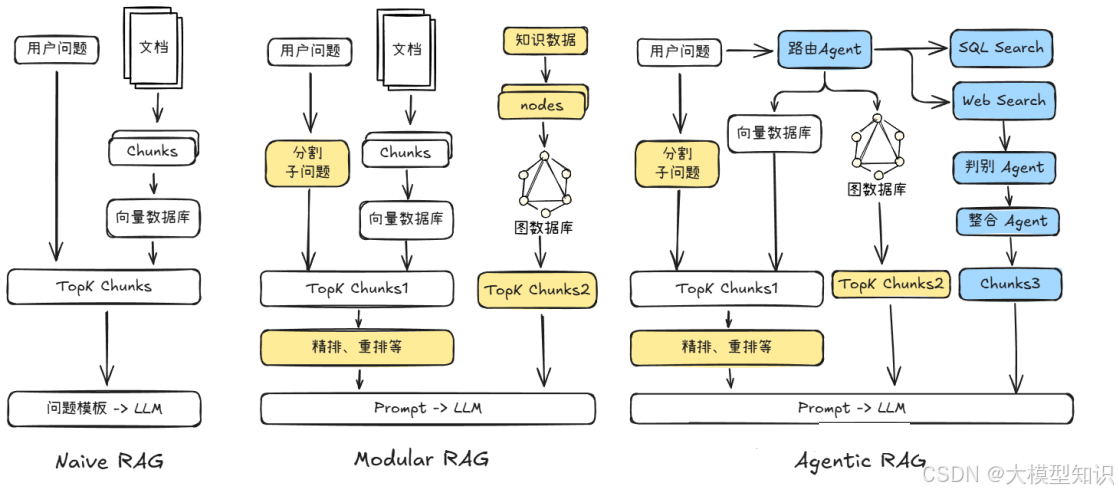
基于上面的图片,小编也对三个阶段做出了一些总结。
- 第一种经典的Naive RAG主要包括“索引-检索-生成”流程,通常基于文本处理;
- 第二种Modular RAG,相比Naive RAG具备较灵活的知识整合能力与检索策略。在知识库的整理阶段,涉及复杂的Chunk编排,在检索阶段,进阶的RAG能支持对检索的前后额外处理;
- 第三种Agentic RAG搭载在智能体基座上,因此拥有更强大的检索能力,除了维护私域数据的检索之外,额外维护一套工具链路增强知识检索能力。
大家很明显的看到,这三种RAG发展阶段是逐渐将RAG工程化与模块化的过程,并且尽可能地与智能体进行适配。
RAG基本流程
介绍完RAG内容后,大家听的可能还是一头雾水,接下来介绍一下RAG的基本流程。RAG 的基本流程包含了整理知识库、使用嵌入模型、载入向量数据作索引、查询与检索和LLM生成回答的过程。
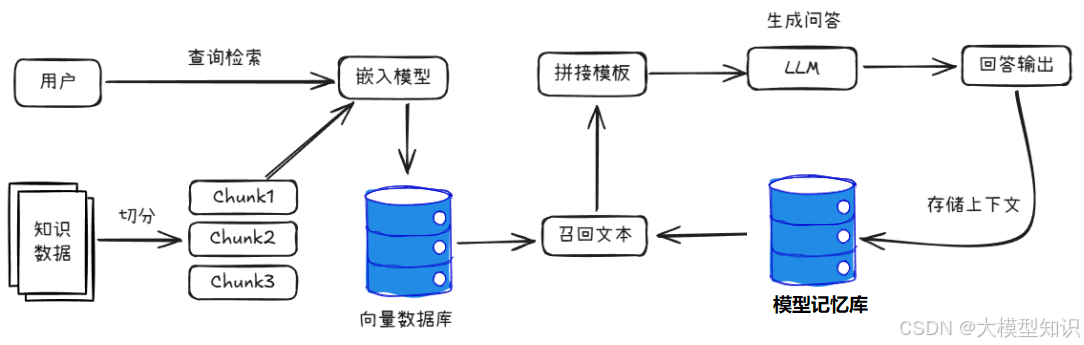
图中的术语可能相对大家来说比较陌生,因此小编整理了关键概念,大家来看一下吧。
- 整理知识库:将已有的多源数据格式整理/切分成文本块,具体文本块(Chunks)内裁剪窗口和块间排布结构可以根据实际任务设计。而对于多源数据的整合模式则需要考虑数据的关系以及元数据的定义;
- 使用嵌入模型(Embeddings):对于Chunk转化成向量模式,删去无意义助词,捕捉Chunk核心含义(在欧拉空间的位置);
- 载入向量数据库做索引:针对Embedding后的Chunks存储使用向量数据库维护,便于批量查询;
- 查询与检索:用户的输入同样被嵌入后在向量数据库匹配过滤topK记录;
- LLM生成回答:给定ChatTemplate,将用户输入与检索的信息填入作为Prompt输入,模型会产生对专有知识的输出。
简单来说,RAG的主要流程就是大模型在对询问回答的时候借助在线的检索能力,对回答的参考能力进一步作出描述。
RAG医疗场景实践
有了上面的RAG理论基础,现在和小编一起对已有的RAG知识做一次工程上的尝试吧。本次实践以医疗场景中的智能问诊为示例,通过场景介绍、模块构建、大模型微调和Agent集成与业务工具拓展等方面,带大家进一步感受RAG的超强能力。
RAG场景介绍
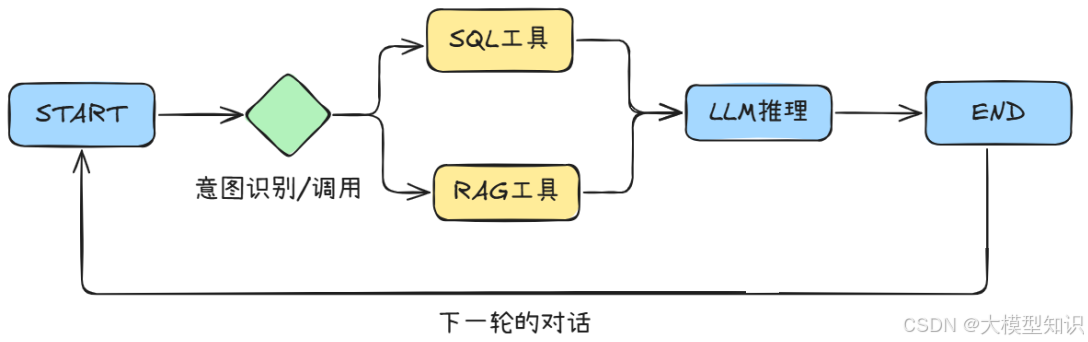
现在,针对医院智能问诊场景做出实践。智能问诊场景中RAG框架需要借助代表静态资产的医学知识(例如临床医疗指南NCCN、UpToDate和医学论文PubMed等)和代表动态资产的患者日志病历(例如患者电子病历EMR等)进行简单/推理性质的询问,其中主要技术链路如下图。
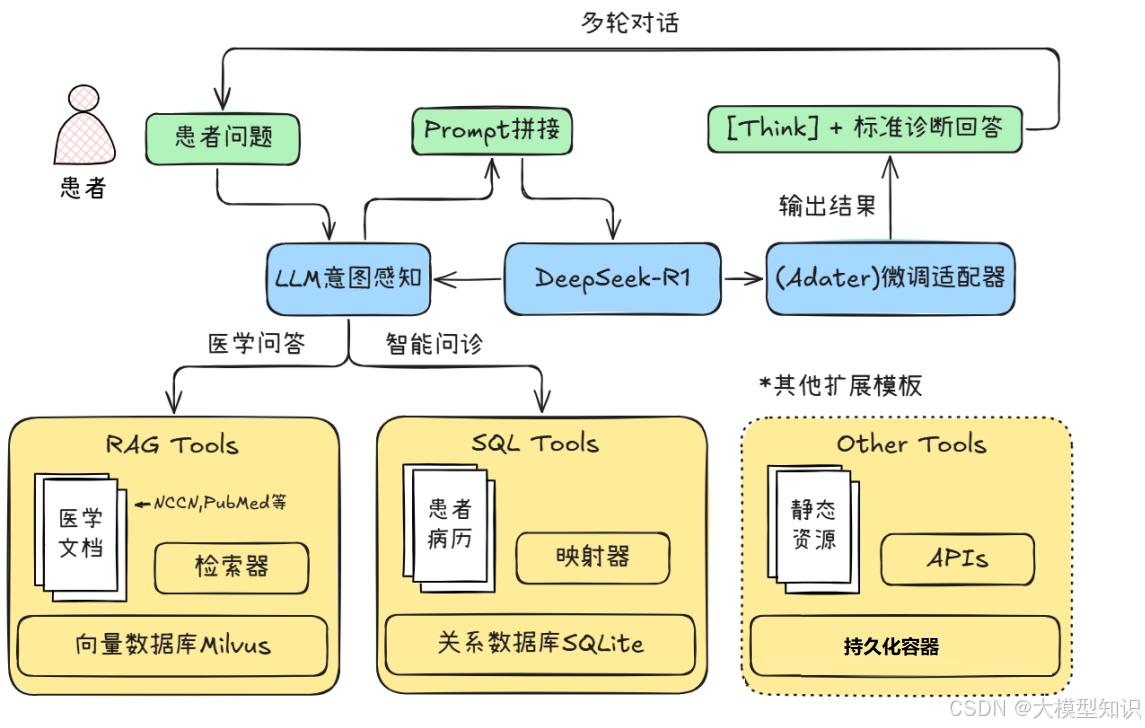
上述的主要流程为:首先用户输入问题,LLM基座(这里使用DeepSeek-R1)根据用户的提问进行意图感知,考虑需要调用的基础工具(基于医学知识文档的RAG或者是需要联表查询的SQL Tools);接着相关的业务工具会获取相关医学概念知识/文献数据/具体患者病历;然后已有的Prompt模板拼接用户的Query和相关文档输入带有LLM基座;此时LLM基座收到带有参考资料的询问,就激活已微调好的Adapter输出相关的推理过程与标准回答。这套流程涵盖上下文保存的过程,因此能够支持患者的多轮问答。
RAG模块构建
RAG模块首先需要针对已有的资料进行切分与嵌入,由于数据都是Markdown格式,因此考虑使用MarkdownHeadSplitter对一级标题和二级标题做一个切分,具体的内容再根据长度进行滑窗切分,相关核心代码如下

因此后续拼接后得到的字段就包括两级标题以及内容,例如这篇文章的一级标题是“RAG医疗场景实践”,二级标题是“RAG模块构建”,则格式化后的Chunk是 "RAG医疗场景实践-RAG模块构建-(具体内容)"
切分好的Chunk需要持久化部署在向量数据库内为在线的模型提供多次查询,这边采用轻量级,易于启动的单机部署数据库Milvus进行实践。同样地,考虑所有的中文嵌入模型,使用 BAAI/bge-large-zh 对所有切分的Chunks嵌入至784维的稠密向量中,即 "text of document" -> Vector(784)
在初始化好持久化查询的向量数据库后,具体的检索流程如下:
- 用户输入的Query同样使用
BAAI/bge-large-zh嵌入成查询向量 - 针对查询向量从Milvus向量数据库中查询到TopK个相似结果,其中相似度度量采用余弦相似度,具体公式如下( A,B代表两个向量)
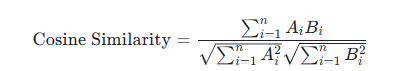
- 考虑注意力对头尾的聚焦能力比中间文本更强,因此使用重排器FlagReranker(也是基于Bge系列的重排器)进行重排,得到更加符合问题的参考文档块
- 将文档块和Query使用Prompt模板规则化,输入微调后的LLM基座,即可得到回答
DeepSeek-R1微调适配
DeepSeek-R1是作为Reasoning模型对于RAG包括智能问诊适配的一个尝试,这边针对已有的资产进行简单询问或带有推理的询问,其中构造相关的问答对 (query, documents, response) 格式,具体如下
("问下这个布洛芬怎么吃?", ["布洛芬是一種非类固醇消炎止痛药...", "患者id-问诊日期-病症-药方..."], "口服成人一次1片,一日2次(早晚各一次)")
考虑模型的参数量、训练性能与具体指令功能的匹配,进行Lora微调即可,具体微调的过程和原理不做展开,这边给出Lora的部分关键参数。
LoraConfig(
lora_alpha=32,
lora_dropout=0.1,
r=16,
bias="none",
task_type="CAUSAL_LM",
target_modules=["k_proj", "q_proj", "v_proj", "up_proj", "down_proj", "gate_proj"]
)
后续将训练好的权重作为Adapter和DeepSeek-R1一块在vllm上进行部署。
Agent集成与业务工具的拓展
使用LangGraph+LangSmith做一个智能体服务的集成,其中主要包含Start节点、意图识别节点与绑定BaseTool节点,具体智能体相关在此不做展开。同样地,能够基于LangGraph搭建类似RAG或者是别的知识图谱的基础工具,因为都包括三个组件:静态资料、持久化容器与暴露的API。关于LangGraph调用的节点流程如下图。
以上就是RAG的具体在医疗场景的实践,但是这个实践还是有很多可以优化的地方,因此,小编在文章最后也总结了相关RAG优化内容,大家一起来看一下吧~
RAG评估
现在大家已经对RAG的使用场景已经熟悉了,那么如何评价下RAG的对于内容检索和整体生成精度的优劣呢?这边小编带大家来看一下关于RAG评估的知识。通常对RAG评估需要考量RAG检索、生成、意图等方面(其实这是一个比较困难的评估过程,因为并没有绝对客观的量化标准)
- 检索环节的评估
- MRR(Mean Reciprocal Rank)平均倒数排名:用于评估信息检索的指标。记确定正确的检索条目Chunk,考虑Chunk在实际检索中的排名倒数(如果检索排名是n,则MRR(1) = 1 / n)
- HR(Hit Rate)命中率:评估召回文档的比率,即TopK中正确的Chunk占比
- 生成环节的评估(借助Ragas)
- BleuScore:基于精度做评分(n-gram匹配对数量 / 系统生成的翻译总n-gram数, 可能使用短文本惩罚)
- ROUGE-N:基于召回做评分(n-gram匹配对数量 / 参考的翻译总n-gram数)

同样地,答案性质评估还包括:Perplexity、时效性、拒答程度
RAG优化方向
RAG的优化方向可以根据检索优化、生成优化与RAG增强三个方面,其中检索优化主要针对文档准备、分块存储处理、索引检索策略的阶段,主要有如下优化方向
- 数据链路优化:需要对表格数据,列表数据和流程图数据做额外Chunk切分(因此在考虑数据的时候也考虑分块,同样可以考虑元素嵌入);滑动窗口技术检索、摘要嵌入(TopK检索,并对文档给出完整的上下文)、图索引(匹配实体-关系对作查询,但是GraphRAG耗时耗成本);以及针对稠密的向量可以直接进行相似度的匹配,但是对于稀疏向量的检索,最佳匹配方式是BM25(基于TF-IDF)
- Altas模式:检索器基于Contriever设计,将模型与检索器基于同种损失函数共同训练

而生成优化主要强调模型对已有信息的感知能力和提升Response的事实准确度,主要有如下优化方向
- Context 顺序优化:由于通用注意力对越靠后的文本注意力越强,因此可以重新根据之前几轮的对话重新给出文献的排序,并且根据最新的Query相关性过滤已有的记忆;
- 模型微调:如果数据并不是特别隐私,或者面向的用户都是私域内部,模型微调也能加强对指令感知(训练数据:专业问答、通用任务等),在处理数据时可以考虑针对原有的Response做人工标注来做RL增强。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献255条内容
已为社区贡献255条内容

所有评论(0)