Day 25 异常处理
今日任务:异常处理机制debug过程中的各类报错try-except机制try-except-else-finally机制检查自己过去借助ai写的代码是否带有try-except机制,可以在以后尝试加入这种写法NameError"2" + 2ValueErrorint("abc")IndexError这个时候,遇到错误,一般选择的是复制给AI,让AI帮助分析、解决。这个方法虽然快速,但是对于个人能
- 异常处理机制
- debug过程中的各类报错
- try-except机制
- try-except-else-finally机制
-
检查自己过去借助ai写的代码是否带有try-except机制,可以在以后尝试加入这种写法
在之前的学习中,自己敲代码时总是会或多或少的出现报错的情况,常见的错误类型如下:
| 错误类型 | 描述 | 示例 |
|---|---|---|
SyntaxError |
语法错误 | print("Hello" (缺少右括号) |
IndentationError |
缩进错误 | 代码块缩进不一致 |
NameError |
未定义变量 | print(undefined_var) |
TypeError |
类型错误 | "2" + 2 (字符串与数字相加) |
ValueError |
值错误 | int("abc") (无法转换为整数) |
IndexError |
索引错误 | list = [1,2,3]; print(list[5]) |
KeyError |
键错误 | dict = {"a":1}; print(dict["b"]) |
ZeroDivisionError |
除零错误 | 10 / 0 |
FileNotFoundError |
文件未找到 | open("nonexistent.txt") |
AttributeError |
属性错误 | "string".non_existent_method() |
ImportError |
导入错误 | import non_existent_module |
KeyboardInterrupt |
键盘中断 | 用户按下 Ctrl+C |
MemoryError |
内存错误 | 内存不足时引发 |
这个时候,遇到错误,一般选择的是复制给AI,让AI帮助分析、解决。这个方法虽然快速,但是对于个人能力的提升实在太小。因此,学会自己看懂错误类型,并且处理异常是十分必要的。
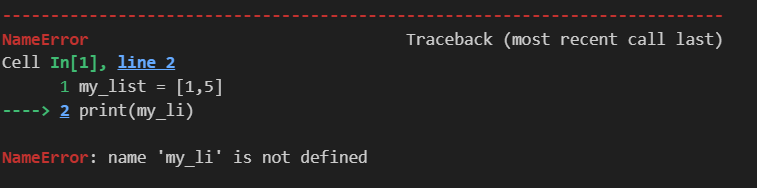
比如,在上面的例子中可以看到,它指出了错误的类型为‘NameError’,具体的含义:‘这个变量没有被定义’,以及出错的位置‘第二行’。
异常处理
对于一段代码来说,如果不进行异常处理,那么可能仅仅因为一个小错误,就会让整个程序崩溃而无法运行,这样的情况是很糟糕的,因此,需要异常处理,具体来讲,可以包括以下几个原因:
- 提高程序健壮性:防止程序因意外错误而崩溃
- 改善用户体验:提供友好的错误信息而非技术性报错
- 便于调试:准确定位和记录错误信息
- 资源管理:确保文件、网络连接等资源正确释放
- 流程控制:根据不同错误类型执行不同处理逻辑
关于异常处理的语法,主要有以下四个关键字:
- try:包含可能引发异常的代码
- except:捕获并处理特定类型(自定义或Exception中的)的异常
- else:如果try中的代码没有异常就执行(可选)
- finally:无论是否发生异常都会执行,常用于资源清理(可选)
将上述关键词进行组合,可以得到try-except(基本结构),try-except-else,try-except-else-finally等结构。
try-except
try:
# 可能引发异常的代码
number = int(input("请输入一个数字: "))
result = 100 / number
except Exception: #通用错误
print('存在错误!') #只知道错误,但无法判断具体的
except ValueError: #具体的错误类型
# 处理值错误
print("请输入有效的数字!")
except ZeroDivisionError: #具体的错误类型
# 处理除零错误
print("数字不能为零!")在上面的例子可以知道,这个代码包含了两个异常类型检查——输入数字和除数不为零。执行的顺序就是,先进行try中的代码,如果有异常,那么执行后面的except,如果错误类型已定义,那么就可以被捕捉到。从这里,也可以发现,except是可以有多个的,即定义多个错误类型。
try-except-else
try:
file = open(filename, 'r')
except FileNotFoundError:
print(f"文件 {filename} 不存在")
except PermissionError:
print(f"没有权限读取文件 {filename}")
else:
# 只有在文件成功打开时才执行
content = file.read()
print(f"文件内容: {content}")
file.close()在这个例子中,首先检查try中的代码,打开文件的操作。如果异常,看是文件不存在还是权限问题,或者其它。如果能被正常打开,那么就读取内容。
那么,既然如果没有异常的话,为什么不直接放在try里面呢?反而增加一个else代码块:
- 清晰性:可以将‘可能异常’与‘未异常’完全区别开
- 避免意外捕获:如果成功后的代码中,也存在可能依法try中想要捕获的同类型异常,会使逻辑混淆
try-except-finally
try:
file = open("data.txt", "r")
content = file.read()
number = int(content)
except (FileNotFoundError, ValueError) as e:
print(f"错误: {e}")
finally:
# 无论是否发生异常,都会关闭文件
if 'file' in locals() and not file.closed:
file.close()
print("资源清理完成")finally具有的无论如何都会执行的特点,使得它在流程长、资源消耗大、外部依赖多的DL或ML中,主要用于资源的保存、文件的关闭等。
下面是具体的阐述:
- 数据不丢失:无论训练成功、失败还是中途被打断,都确保日志文件被正确关闭,避免数据丢失或文件损坏。
- 计算资源释放:确保计算资源在使用完毕后被释放,供其他进程或任务使用。更常见的是使用 with 语句来自动管理这类资源,with 语句本身就隐式地使用了类似 finally 的机制。(with open语句)
- 数据库连接管理
- 状态可恢复:恢复全局状态或配置, 如果程序在运行过程中修改了全局变量或配置文件,在异常处理结束后,需要恢复到之前的状态或配置。
- 训练状态保存:模型训练可能非常耗时,如果中途因为各种原因(OOM、手动中断、硬件故障)停止,我们希望记录下中断的状态,方便后续恢复。
此外,还有try-except-else-finally,例子如下:
#爬虫
import requests
def api_call_with_retry(url, retries=3):
for attempt in range(retries):
try:
response = requests.get(url, timeout=5)
response.raise_for_status()
except requests.exceptions.Timeout:
print(f"请求超时,尝试 {attempt + 1}/{retries}")
if attempt == retries - 1:
return None
except requests.exceptions.RequestException as e:
print(f"网络请求失败: {e}")
return None
else:
# 请求成功,返回数据
return response.json()
finally:
# 每次尝试后都执行
print(f"第 {attempt + 1} 次尝试完成")
return None
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)