RAG已死?
RAG从开始到今天,已经发展了好几年了,它作为一个大模型应用已经广泛落地到很多行业,解决检索和问答的问题。但是随着大模型的发展,大模型的能力越来越强,支持的上下文长度也越来越大,从简单的文本也发展到现在的多模态,人们慢慢觉得是不是RAG已死,今天就探讨下这个问题。不是说RAG已死,而是简单的RAG已死,目前RAG想着更加完善智能的方式进行发展,它慢慢进化为一个完美的agent,帮助客户全方位解决知
rag系列文章目录
前言
RAG从开始到今天,已经发展了好几年了,它作为一个大模型应用已经广泛落地到很多行业,解决检索和问答的问题。
但是随着大模型的发展,大模型的能力越来越强,支持的上下文长度也越来越大,从简单的文本也发展到现在的多模态,人们慢慢觉得是不是RAG已死,今天就探讨下这个问题。
一、RAG回顾
RAG最开始是为了解决大模型上下文不足导致模型幻觉的问题,作为一个外挂知识库,它能够更好地回答客户问题。
它的思路也很简单,主要分为两个。
一是,生成索引,对文档进行切片处理,向量化,然后存储索引。
二是,检索召回,将问题向量化,通过向量召回相关内容,然后进行喂给大模型回答。
二、RAG问题
1.召回问题
对一般的问题而言,召回切片,进行问答即可。但是对有些问题而言,不能只是简单的切片,回答文档所需要的参考资料是整个文档,或者是几篇文档,目前大模型上下文长度很大,所以将这个文档召回,送给大模型是可以的。
2.单知识源
在进行召回的时候,只能使用一个知识源,也可以使用多个知识源进行召回,但是呢,也仅限于索引类型的,召回后进行合并。如果碰到数据库类型的知识源,就显得无能为力。
3.自动化
RAG没有自动化的能力,仅仅但是单次的问答,没有主动性。
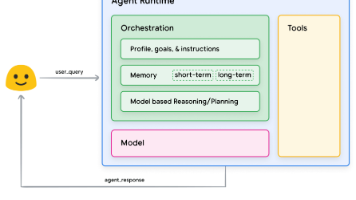
三、Agentic RAG
针对上面的召回问题,Agentic RAG模式,支持对文档进行召回,文档召回有两种方式,files_via_metadata和files_via_content。
files_via_metadata这种,倾向于根据问题找到匹配的文件名,然后找到整篇文档。files_via_content这种,倾向于根据topic找到一类文档,将相关的文档都给大模型回答使用。
Agentic RAG构建了复合检索,每个知识源,对它来说只是一个检索器,它可以根据问题,筛选知识源,对特定的知识源进行检索,然后再对结果归并排序处理。
一个简单的Agentic RAG如下图所示:
该系统的运作机制如下:
在顶层,复合检索器通过基于大型语言模型的分类,确定哪个子索引(或索引组合)与给定查询相关。
在子索引层级,自动路由检索模式将为查询确定最适配的检索方法(如分块检索、基于元数据的文件检索或基于内容的文件检索)。
最后进行大模型问答。
总结
不是说RAG已死,而是简单的RAG已死,目前RAG想着更加完善智能的方式进行发展,它慢慢进化为一个完美的agent,帮助客户全方位解决知识问答的难题。
传统的RAG慢慢变成了一个召回范式而言,而agent使用的知识源,慢慢通过MCP接口接入,rag只是一个普通的MCP入口。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)