CV相关论文
此外,ViT的计算成本较高,特别是在处理所有图像Token时(Wang et al., 2025)。随着对其工作机制的深入理解和技术瓶颈的不断突破,例如减少计算成本(Yue & Li, 2024)、提高数据效率、增强模型可解释性以及与其他网络结构的融合(Yang et al., 2025)(Hussain et al., 2025),ViT及其变体有望在更广泛的应用场景中发挥关键作用,尤其是在需要
很浅薄,建议别看
Vision Transformer (ViT) 在图像分类领域取得了显著进展,其核心在于将Transformer架构(最初为自然语言处理设计)应用于图像任务,通过自注意力机制有效捕获图像中的长距离依赖关系。以下是一些关于使用ViT进行图像分类的经典与权威文章的综合分析(Han et al., 2022)(Attiapo & Omer, 2024)。
1. Vision Transformer的开创性工作
Alexey Dosovitskiy等人在2020年发表的《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》一文,首次证明了纯粹的Transformer模型可以直接应用于图像序列,并在图像识别任务中表现出色(Dosovitskiy et al., 2020)。这篇论文是ViT领域的里程碑,它打破了计算机视觉领域对卷积神经网络(CNN)的长期依赖(Dosovitskiy et al., 2020)。文章提出将图像分割成固定大小的图像块(例如16x16像素),然后将这些图像块展平为序列,并添加位置编码以保留空间信息,最后输入到标准的Transformer编码器中进行处理(Dosovitskiy et al., 2020)(Zhou et al., 2024)。这种方法使ViT能够捕获全局依赖性,这在传统CNN中往往需要复杂的结构才能实现(Attiapo & Omer, 2024)。
图1展示了Vision Transformer (ViT) 的整体架构,清晰地描绘了输入图像如何被分割成固定大小的图像块,并经过线性投影和位置嵌入,然后送入多阶段的Transformer编码器,最终输出用于分类的特征表示(Ruiping et al., 2024)。
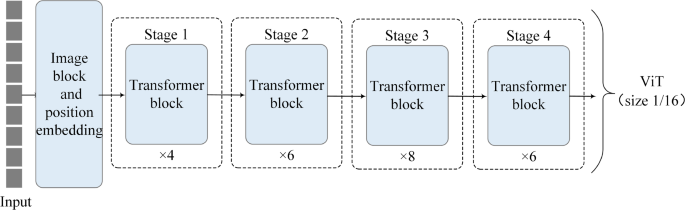
Source: (Ruiping et al., 2024)
2. ViT的核心机制与改进
ViT模型成功的“四大秘密”主要包括:图像块划分、Token选择、位置编码添加和注意力计算(Zhou et al., 2024)。
- 图像块划分(Patch Division): 图像被分割成不重叠或重叠的等大或不等大图像块。不同的划分方式会影响模型处理图像信息的方式(Zhou et al., 2024)。
- Token选择(Token Selection): 基于分数或动态机制选择重要的Token,例如动态ViT、局部Vision Transformer (LVT) 和Token-to-Token Vision Transformer (T2T-ViT) 等方法(Zhou et al., 2024)。
- 位置编码(Position Encoding): 由于Transformer架构的置换不变性,位置编码对于保留图像的空间信息至关重要。研究表明,相对位置编码(RPE)在NLP领域被证明有效,但在计算机视觉中的效用仍有争议,需要进一步研究其在ViT中的应用(Wu et al., 2021)(Zhou et al., 2024)。常见的有绝对位置编码和相对位置编码(Zhou et al., 2024)。
- 注意力机制(Attention Mechanism): ViT的核心是自注意力机制,它允许模型同时关注输入序列(图像块)的不同部分,捕获图像中复杂的内部关系(Abdullah & Aydin, 2024)(Aghamohammadesmaeilketabforoosh et al., 2024)。多头自注意力机制(Multi-Head Self-Attention)是其中的关键组成部分,它通过多个注意力头并行处理信息,增强了模型的表达能力(Aghamohammadesmaeilketabforoosh et al., 2024)。
图2进一步详细阐述了ViT的组成部分和机制,包括不同图像块划分、Token选择、位置编码和注意力机制的方法(Zhou et al., 2024)。
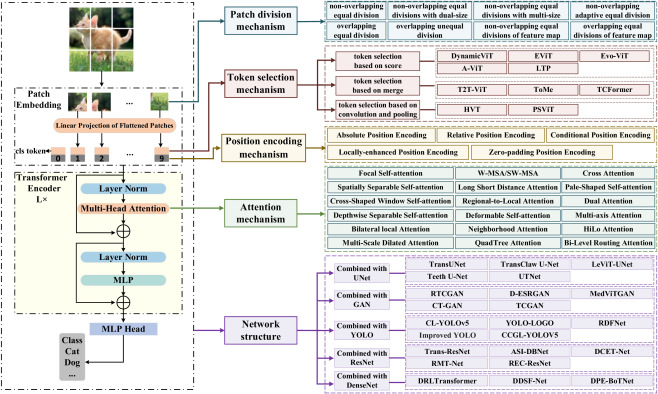
Source: (Zhou et al., 2024)
3. ViT的性能与局限性
ViT在各种视觉基准测试中表现出与CNN相当甚至更优的性能(Han et al., 2022)。例如,在图像分类任务中,ViT模型能够捕获全局依赖性并增强特征表示(Attiapo & Omer, 2024)。然而,ViT模型通常需要大量的训练数据才能达到最佳性能,这限制了其在数据稀缺场景中的应用(Yang et al., 2025)(Jamali et al., 2023)。此外,ViT的计算成本较高,特别是在处理所有图像Token时(Wang et al., 2025)。当ViT模型层数加深时,可能会出现“注意力崩溃”问题,即注意力图变得相似,导致性能饱和(Zhou et al., 2021)。
4. 结合CNN与ViT的混合模型
为了克服ViT的局限性,许多研究开始探索结合CNN归纳偏置的混合架构。例如:
- 卷积Vision Transformer (CvT):CvT通过引入卷积Token嵌入和卷积Transformer块,在ViT中融合了卷积的优势,提高了性能和效率(Wu et al., 2021)。
- EFFResNet-ViT: 该模型结合了CNN和ViT的优点,旨在提高医学图像分类的解释性和准确性,同时弥补CNN在捕获全局上下文方面的不足和ViT缺乏领域特定归纳偏置的问题(Hussain et al., 2025)。
- ViT-UperNet: 针对医学图像分割任务,该模型将自注意力机制嵌入ViT中以提取多级特征,并结合统一感知解析网络(UperNet)进行语义分割(Ruiping et al., 2024)。
5. ViT在特定领域的应用
ViT的强大能力使其在多个特定图像分类领域得到广泛应用:
- 医学图像分类: ViT在疾病分类、分割和检测等任务中表现出优于传统深度学习模型的准确性(Shams et al., 2025)。例如,ViT被用于肾结石图像分类(Reyes-Amezcua et al., 2025)、皮肤癌检测和分类(Himel et al., 2024)(Flosdorf et al., 2024)、以及生物医学图像分类(Tjahyaningtijas et al., 2025)。
- 遥感图像场景分类: ViT模型在遥感图像场景分类中,能够有效解决CNN在多级特征提取中难以考虑场景内不同对象交互的问题(Lv et al., 2022)。
- 工业缺陷检测: 在皮革表面缺陷分类中,ViT用于异常检测和定位(Smith et al., 2023)。
- 食品图像分类: ViT与数据增强和特征增强相结合,可实现高精度的食品图像分类,尤其在处理形状相似但营养价值不同的食品时表现突出(Gao et al., 2024)。
- 电子元件图像识别: ViT用于解决传统CNN在电子元件识别中训练时间长、需要手动提取特征等问题(Chen & Chen, 2023)。
- 高光谱图像分类: ViT通过建模长距离依赖性和提取全局空间特征,在高光谱图像分类中取得了显著进展,但也面临参数量大的挑战(Zhao et al., 2024)。
- 组织病理学图像分类: Fourier ViT模型结合傅里叶变换,能够提取病理图像中不显著的特征,提高癌症诊断的准确性(Duan et al., 2022)。
- 天文源分类: ViT和注意力机制被用于增强天文源分类器,以区分恒星、类星体和紧密星系(Bhavanam et al., 2024)。
- 地形图像分类: 基于ViT的深度学习算法被用于地形图像的自动识别和分类(Ren & Zhang, 2024)。
6. ViT的进一步优化与发展
为了解决ViT的挑战,研究人员提出了多种优化策略:
- 稀疏专家混合网络(MoE): Vision MoE (V-MoE) 是ViT的稀疏版本,通过选择性地激活网络中的部分专家模型来处理输入,实现了更好的可扩展性,并在图像识别中与最先进的密集网络相当(Riquelme et al., 2021)。
- 深度优化: DeepViT通过引入可重配置的注意力机制来解决深度ViT中注意力崩溃的问题,提高了模型深度扩展时的性能(Zhou et al., 2021)。
- 数据增强与预处理: 数据增强技术,如Jigsaw-ViT,通过解决拼图任务进行自监督学习,可以提高ViT在各种任务中的表现(Chen et al., 2022)。CNN-based物体提取预处理方法,如DeepLabv3,可以帮助ViT在少量样本数据集上提高图像分类性能(Kim et al., 2025)。
- Token剪枝: TinyDrop提出了一种无需训练的Token剪枝框架,通过轻量级模型估计Token的重要性,从而选择性地丢弃不重要的Token,以降低大型ViT的推理成本(Wang et al., 2025)。
- 相对位置编码改进: 虽然相对位置编码的效用仍在研究中,但其对于捕获序列顺序至关重要,未来的研究将继续探索其在ViT中的有效应用(Wu et al., 2021)(Zhao et al., 2025)。
7. 展望
ViT在图像分类领域展现了巨大的潜力,并已成为计算机视觉研究的热点。随着对其工作机制的深入理解和技术瓶颈的不断突破,例如减少计算成本(Yue & Li, 2024)、提高数据效率、增强模型可解释性以及与其他网络结构的融合(Yang et al., 2025)(Hussain et al., 2025),ViT及其变体有望在更广泛的应用场景中发挥关键作用,尤其是在需要捕获长距离依赖关系的复杂视觉任务中(Jahin et al., 2025)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)