大模型微调、RAG 和代理学习笔记
微调类别核心思想典型方法优点全参数微调更新全部参数,通过监督数据和 RLHF 调整行为SFT + 奖励模型 + RLHF/PPO性能最高,适合复杂任务选择性微调只更新部分权重(偏置、最后几层或自动选出的参数)Freeze Layers、BitFit、PASTA 等参数少、实现简单加性微调在模型层之间插入小型适配器,只更新适配器Bottleneck Adapter、Adapter Fusion、MA
引言
大语言模型(LLM)在自然语言理解和生成方面表现卓越,但它们在训练时使用的是静态数据集,缺乏对最新信息的掌握。为了让模型适应特定领域或完成复杂任务,研究人员提出了微调、**检索增强生成(Retrieval‑Augmented Generation,RAG)以及代理(agent)**等技术。本笔记对这些技术进行梳理,并结合近两年(截至 2025 年)的最新研究成果阐述其背景、核心方法和前沿趋势。
大模型微调
1. 全参数微调与对齐方法
为了在特定领域产生更准确、符合人类偏好的结果,需要对预训练的大模型进行微调。常见的全参数微调流程包括:
-
监督微调(SFT):在高质量人工标注示例上继续训练模型,使其输出符合特定任务需求。这通常是对齐训练的起点。
-
奖励模型训练:收集人类对模型输出的偏好排名,训练出能够评估输出质量的奖励模型,用来指导后续的强化学习过程。
-
强化学习微调(RLHF/DPO):使用强化学习算法(例如 PPO 或 DPO)优化模型,使其在奖励模型评分下得到更高的回报,并通过 KL 正则化限制模型偏离预训练分布近年来还出现了 RLAIF 等减少人工反馈的新算法。由于 RLHF 消耗显存巨大,通常结合参数高效微调技术,例如在 RLHF 中只微调 LoRA 模块。
2. 参数高效微调(PEFT)
当模型规模不断增长时,完全微调所有参数成本高昂。**参数高效微调(PEFT)**策略只更新一小部分额外参数,既降低计算与存储成本,又能达到接近全量微调的性能。HuggingFace 文档指出,PEFT 方法通过仅微调少量新增参数显著减少计算和存储成本,同时仍能获得与完整微调相当的效果
2.1 选择性微调
这种方法在原模型中只更新部分权重:
-
冻结层(Freeze Layers):仅微调模型的最后几层,其余层保持冻结;在 RoBERTa 等模型上效果良好。
-
BitFit:仅调整模型中的偏置项或部分偏置项,极大减少需要更新的参数。
-
PASTA:只微调特殊标记(如
[CLS]、[SEP])对应的嵌入,训练参数约占总数的 0.029%,却能接近完整微调性能。 -
自动选择方法:包括 Masking、Diff‑Pruning、FISH、AutoFreeze、Child‑Tuning 等,通过学习二进制掩码或利用 Fisher 信息自动选择需要更新的参数。
优点是无需添加额外模块,参数更新少;缺点是难以捕捉复杂任务模式。
2.2 加性微调(适配器)
加性微调在模型各层间插入小型适配器模块,只更新适配器参数,而保持原模型参数不动:
-
瓶颈适配器(Bottleneck Adapter):将输入降维后通过非线性激活再上投影,并加入残差连接,以减小对原模型的破坏。
-
多适配器(Multi‑Adapter):为不同任务训练多个适配器并在推理时融合,如 Adapter Fusion、AdaMix、MAD‑X、BAD‑X 等;MAD‑X 利用语言适配器、任务适配器和可逆适配器应对跨语言迁移。
-
适配器稀疏化:如 AdapterDrop 随机丢弃适配器层以提高训练速度。
加性微调具有模块化优点,适配器可视作插件在不同任务间组合;缺点是推理时增加额外前向计算。
2.3 重参数化微调(LoRA 及其变种)
**LoRA(Low‑Rank Adaptation)**通过为需要更新的权重矩阵添加低秩分解旁路,只训练低秩矩阵 A、B,从而减少参数量并保持输出形状。LoRA 方法易于集成并适用于大多数模型。
改进的变体包括:
-
KronA:用 Kronecker 乘积代替低秩矩阵,提高表达能力。
-
QLoRA:使用 4‑bit 权重量化和双重量化,使 65B 模型可在 48 GB GPU 上微调并接近 16‑bit 全量微调效果。
-
LoRA‑FA、IncreLoRA、Delta‑LoRA 等根据模块重要性或动态调整策略进一步减少显存并提升性能。
-
MPO(Matrix Product Operator):用张量网络分解权重矩阵,并只训练低参数的辅助张量。
这些方法简化了微调过程,但对秩大小等超参数敏感。
2.4 提示微调
提示微调通过在输入或模型内部引入可学习的“提示”而不改变原模型权重:
-
硬提示(Hard Prompt):人工编写模板,如 Pattern‑Exploiting Training(PET),但需要大量手工设计,泛化能力有限。
-
AutoPrompt:通过自动搜索提示词减轻人工负担,却不一定找到最优模板。
-
软提示(Soft Prompt):包括 Prefix Tuning、Prompt Tuning 和 P‑Tuning v2 等,仅在输入或前缀添加可训练向量,调整参数比例 0.1%–3%,在 GPT‑2/BART 上取得接近全量微调性能。
提示微调几乎不改变模型权重,训练速度快,但效果依赖提示与任务匹配程度。
3. 微调方法总结表
| 微调类别 | 核心思想 | 典型方法 | 优点 |
|---|---|---|---|
| 全参数微调 | 更新全部参数,通过监督数据和 RLHF 调整行为 | SFT + 奖励模型 + RLHF/PPO | 性能最高,适合复杂任务 |
| 选择性微调 | 只更新部分权重(偏置、最后几层或自动选出的参数) | Freeze Layers、BitFit、PASTA 等 | 参数少、实现简单 |
| 加性微调 | 在模型层之间插入小型适配器,只更新适配器 | Bottleneck Adapter、Adapter Fusion、MAD‑X 等 | 模块化,可组合 |
| 重参数化微调 | 增加低秩或张量旁路,只更新旁路参数 | LoRA、QLoRA、KronA、MPO 等 | 显存友好、性能优 |
| 提示微调 | 学习软/硬提示,无需改变原模型权重 | PET、Prefix Tuning、Prompt Tuning、P‑Tuning v2 | 参数最少、实现简便 |
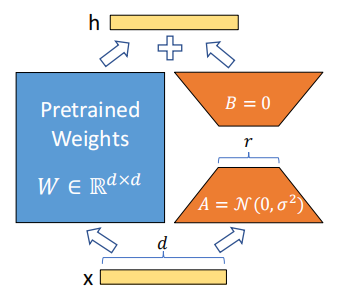
图 1:LoRA 微调示意图(来源:Medium,展示低秩矩阵 A、B 在预训练权重旁路中注入以适配任务)。
检索增强生成(RAG)
1. 为什么需要 RAG
虽然大型语言模型包含大量通用知识,但它们无法及时获取最新信息,且在回答专业问题时容易臆造答案。RAG 通过检索外部文档并将相关片段与用户问题组合成新的提示,帮助模型生成更准确、实时的答案。然而随着模型能力提升,传统 RAG 的优势正逐渐减弱,需分析其机制和挑战。
2. RAG 的四大模块
研究者将 RAG 系统划分为四个模块:
-
索引(Indexing):将外部文档分块并转为稀疏或密集向量表示。传统分块关注局部匹配,无法捕捉跨文档连贯性;因此出现了利用知识图表示文档并按实体层次聚类的 GraphRAG 等方法。
-
检索(Retrieval):包括查询分析、候选检索以及重排序与过滤。其中查询分析通过问题改写、分解和关键词提取提高召回率;候选检索结合稀疏(如 BM25)与密集(如 SBERT 向量)检索;重排序与过滤通过打分和摘要去噪,防止无关信息进入生成模型。
-
生成(Generation):将检索到的内容与用户问题结合,形成提示供 LLM 生成答案。需要处理多源信息冲突并抑制噪声。
-
编排(Orchestration):负责协调索引、检索和生成过程的顺序和并行化,动态决定是否需要检索以及如何利用检索结果。
3. 目标与挑战
RAG 既要实现高召回(找到所有相关文档),又要实现高精度(避免噪音)。过多噪声会导致模型融入无关信息而“迷失在中间”。研究者指出 RAG 主要挑战包括:
-
知识边界不清:系统难以判断 LLM 是否已具备足够知识,导致不必要的检索。
-
查询意图分析不足:复杂问题包含多重子任务,需要问题分解和查询改写。
-
外部知识冲突与噪声过滤:来自不同来源的信息可能矛盾,需过滤不可信内容。
-
在上下文学习机制不明:缺乏对检索与 LLM 交互机制的理论理解,尤其是长文本场景下的 RAG 设计。
4. RAG 的演进与前沿
为突破传统 RAG 的瓶颈,研究者提出了多种改进方向:
-
查询改写与嵌入微调:通过问题重写和嵌入模型微调提升召回与精度。
-
知识图增强 RAG:如 GraphRAG 和 HippoRAG,将文档转为知识图并进行层次聚类,实现跨文档检索。
-
Agentic RAG:将自治代理引入 RAG,动态制定检索计划、反思并使用工具,适应多步推理。
-
长上下文模型:一些超长上下文模型能够直接加载整篇文档,减少对检索的依赖,但仍需要结合 RAG 处理规模更大的知识库。
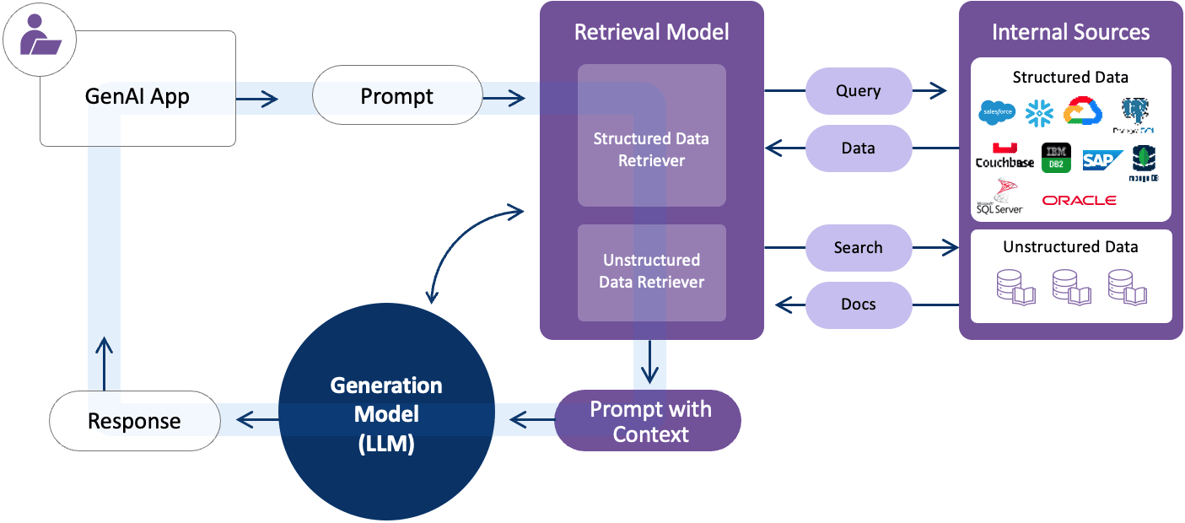
图 2:RAG 架构示意图(来源:K2View,展示用户输入查询、向量检索器、上下文组装和 LLM 生成答案的流程)。
代理(Agent)技术
代理技术让大模型具备规划、行动和自我反思能力,可以与环境或外部工具交互解决多步骤任务。近年来的研究探索了多种代理框架。
1. 基于提示的代理
-
ReAct:交替输出“思考(Thought)”和“动作(Action)”,使模型在生成过程中同时推理并调用工具,在 ALFWorld 和 WebShop 等环境中取得了无训练的优秀表现。
-
StateAct:在 ReAct 的基础上加入显式状态表示(目标、库存、位置),使模型能够跟踪长程任务,成功率提升 10%–30%。
-
Reflexion、Rewind 等自我反思方法:通过多次尝试并回顾失败,模型能够自评问题和调整策略,从而提高代码生成和任务完成率。
2. 经验学习与微调代理
ICLR 2026 论文《Fine‑Tuning with RAG for Improving LLM Learning of New Skills》提出用 RAG 为代理生成“提示”并内化到模型中:先运行基础代理收集失败轨迹,利用 GPT‑4o 诊断错误,提炼可复用提示并通过一次检索提供给教师模型,然后微调学生模型学习去除提示后的策略。这种方法显著提升了任务成功率,并减少了推理时的 token 使用量。
3. Agentic RAG 与智能检索代理
Agentic RAG 将自治代理模式融入 RAG,其核心思想包括:
-
反思与规划:代理能基于反思调整检索策略并规划多步查询。
-
多代理协作与工作流模式:通过提示链、路由、并行化和评估者‑优化器结构等工作流,让多个代理协同完成复杂任务。
-
智能检索:微软 Azure AI Search 的 Agentic Retrieval 是 Agentic RAG 的工程化实例:模型将复杂查询拆分成多个子查询并并行检索,然后合并结果与查询计划,结合聊天历史理解意图,生成高质量答案或引用数据。
4. 代理的发展趋势
-
自我反思与改进:代理逐渐具备自我评估失败并更新策略的能力(如 Reflexion、Rewind)。
-
多代理协作:通过评估‑优化器或专家‑工作者结构让多个代理分工合作,这与 Agentic RAG 的多代理协作模式一致。
-
融合外部工具:结合 RAG、图搜索、知识库或 Web 工具,使代理能检索实时信息、调用服务或生成图表。
-
安全与伦理:代理系统需要考虑错误传播、隐私泄露和偏差问题,未来研究正在探索安全过滤和可控生成策略。
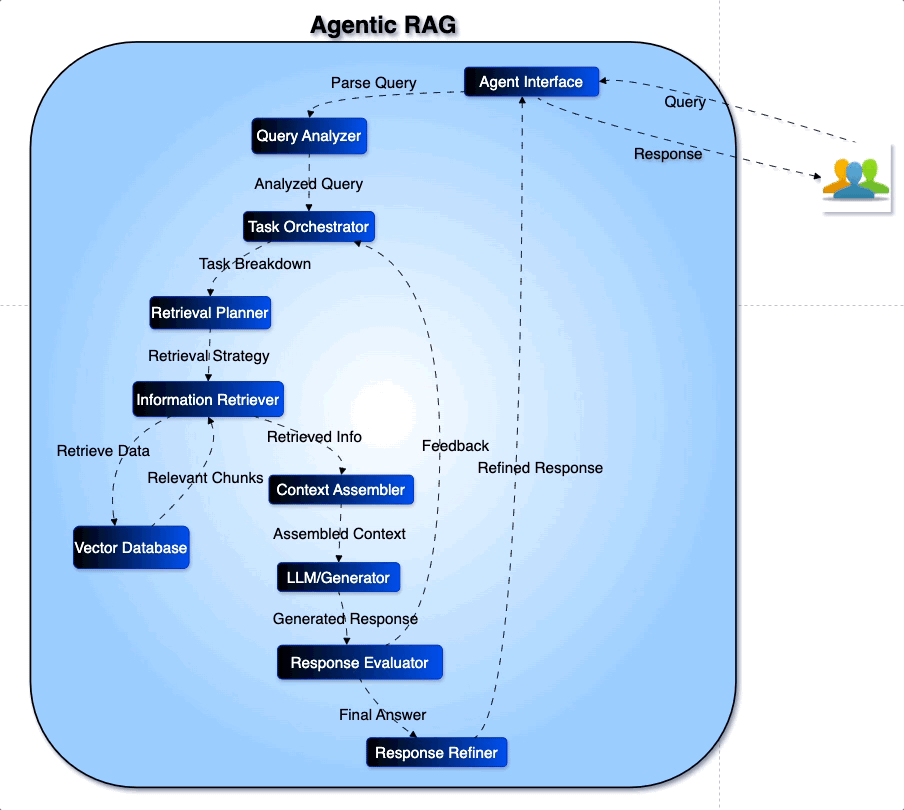
图 3:Agentic RAG 架构示意图(来源:Medium,展示 Query Analyzer、Task Orchestrator、Retrieval Planner、Context Assembler、LLM 生成器等模块协同完成回答的流程)。
总结与展望
-
微调:全参数微调结合 SFT 和 RLHF 可在复杂任务上获得最高性能,但计算资源消耗大。PEFT 通过选择性微调、适配器、低秩旁路或提示等手段显著降低计算成本并获得可比性能。不同方法适合不同场景:需要极高性能时可采用全量微调;资源有限或任务多样时 LoRA、适配器或提示微调更合适。
-
RAG:RAG 通过外部检索引入实时知识,提升模型在知识密集型任务上的能力。优化索引、检索、生成和编排模块,平衡召回率与精度,以及解决噪声过滤、查询分解和知识冲突是设计高效 RAG 的关键。Agentic RAG 等新范式利用代理动态规划检索策略,未来潜力巨大。
-
代理:代理为 LLM 赋予规划、行动和自我反思能力。ReAct、StateAct 等基于提示的代理为大模型交互奠定基础;结合微调和经验学习能进一步提升代理的稳健性。Agentic RAG 等研究将代理与 RAG 融合,通过多代理协作和工作流优化实现复杂任务的自动化。
面向未来,研究者将继续探索如何让大模型在节约资源的情况下具备更强适应性与知识整合能力,同时确保系统的安全、可靠和公平。深入理解 RAG 与 LLM 内部机制、开发更稳定的代理算法、持续优化参数高效微调方法,将是推动通用人工智能应用落地的关键。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)