Qwen3 32B vLLM大模型推理教程:Docker本地部署,实现高效AI推理!
文章摘要:Qwen3开源了8个不同规模的模型,包括MOE和Dense架构,支持混合思维模式、119种语言和增强的Agent能力。部署环境推荐使用单机4张4090显卡运行BF16格式的Qwen3-32B模型,支持10并发96k上下文。文章详细介绍了Docker部署命令及参数配置,并对比了推理模式和非推理模式的推荐参数。此外,还提供了MOE架构的其他部署方案,如vLLM、sglang等,以及Qwen3
一、Qwen3基础知识
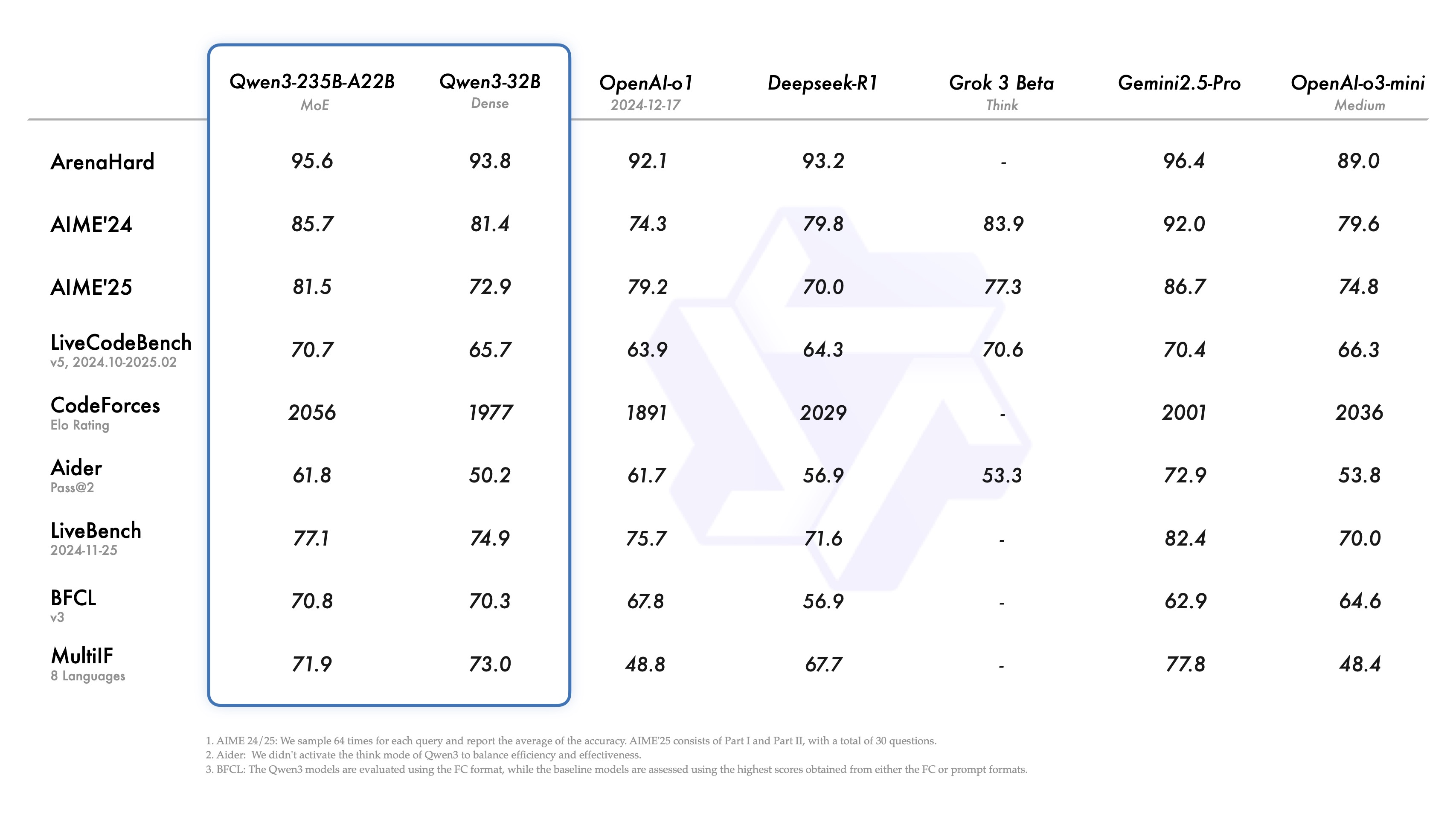
此次Qwen3开源8个模型(MOE架构:Qwen3-235B-A22B、Qwen3-30B-A3B,Dense架构:Qwen3 0.6B/1.7B/4B/8B/14B/32B),新版本的Qwen3特性包括:
- 支持混合思维模式,即推理/非推理一体模型:
- 多语言支持:支持119种语言和方言
- Agent能力提升:加强了编码和Agent表现,并加强了MCP的支持
- 快速体验方式:千问web chat官网
其中,除Qwen3-235B-A22B和Qwen3-32B之外,另外6个模型是蒸馏模型。
各模型版本的参数: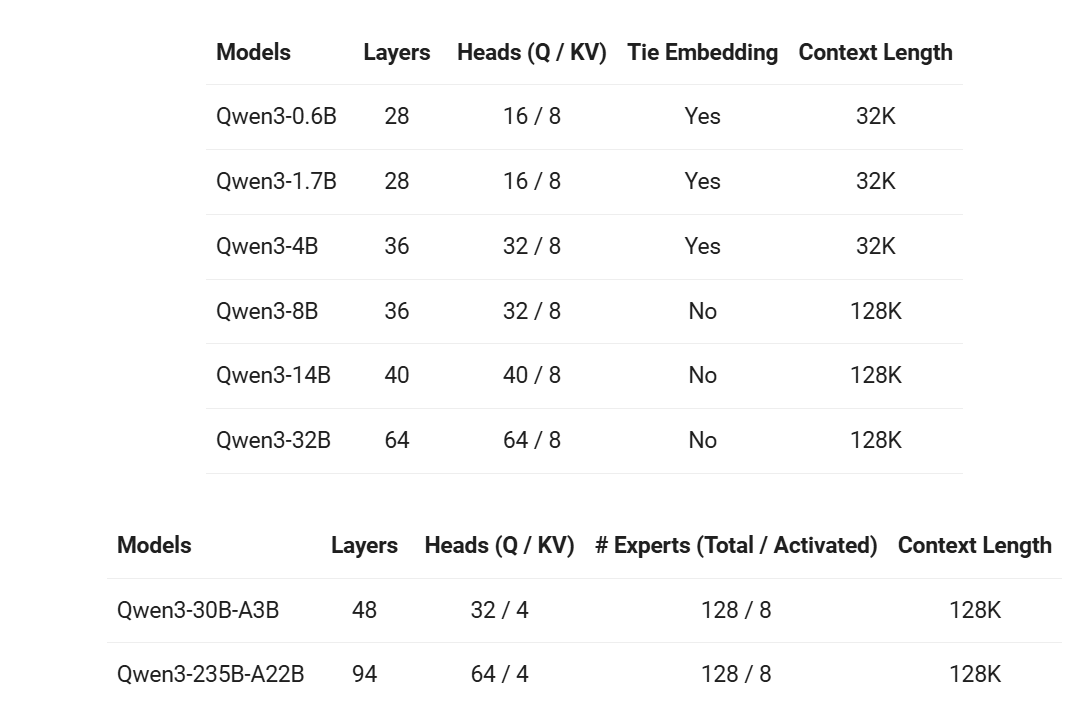
二、部署环境
- 单机4090 x 4部署BF16格式的Qwen3-32B模型
- 10并发下,最长上下文可支持96k(128k显存不够,就只测96k)
- vLLM docker版本:vllm/vllm-openai:v0.8.5(>=0.8.5)
- 需安装好Docker和Nvidia container toolkit,可参考Ubuntu Nvidia Docker单机多卡环境配置
Docker部署
模型下载:
- 国内推荐魔塔社区Modelscope、hf-mirror,以及魔乐社区modelers
Docker启动命令:
docker run -d --runtime nvidia --gpus 4 --ipc=host -p 8000:8000 -v /root/models:/root/models -e "PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128" --name=Qwen3-32b vllm/vllm-openai:v0.8.5 --model /root/models/Qwen3-32B --trust-remote-code --served-model-name Qwen3-32b --max_num_seqs 10 --tensor-parallel-size 4 --gpu_memory_utilization 0.98 --enforce-eager --disable-custom-all-reduce --enable-auto-tool-choice --tool-call-parser hermes --compilation-config 0 --enable-reasoning --reasoning-parser deepseek_r1 --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":40960}' --max-model-len 98304
参数解释:
- model : 映射到容器的本地模型所在的目录
- served-model-name:模型别名,API等调用时使用
- max_num_seqs:最大并发数
- gpu_memory_utilization:显存利用率
- enable-auto-tool-choice、tool-call-parser:启用tool calling,Qwen系列模型是hermes
- enable-reasoning、reasoning-parser:启用推理模式,并设置参考推理为deepseek_r1(截止当前均为deepseek_r1)
- rope-scaling:模型默认是40k,外推长度参数
- max-model-len:模型支持的上下文长度(Qwen32 B最大支持128k)
三、使用方式
-
启用推理模式(默认,也就是不指定/think):
官方推荐参数:Temperature=0.6,TopP=0.95,TopK=20,MinP=0, presence_penalty=0~2,不使用greedy decodeing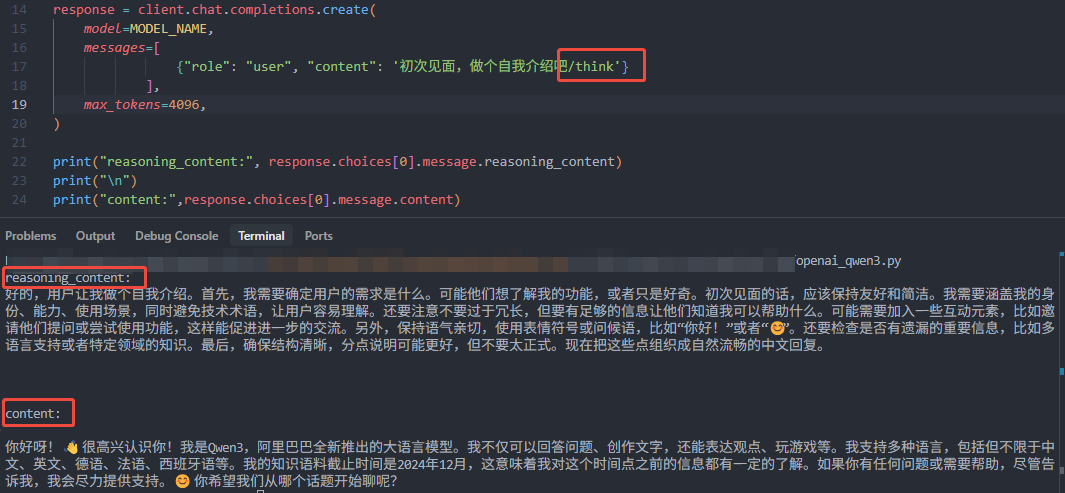
-
启用非推理模式
官方推荐参数:Temperature=0.7,TopP=0.8,TopK=20,MinP=0, presence_penalty=0~2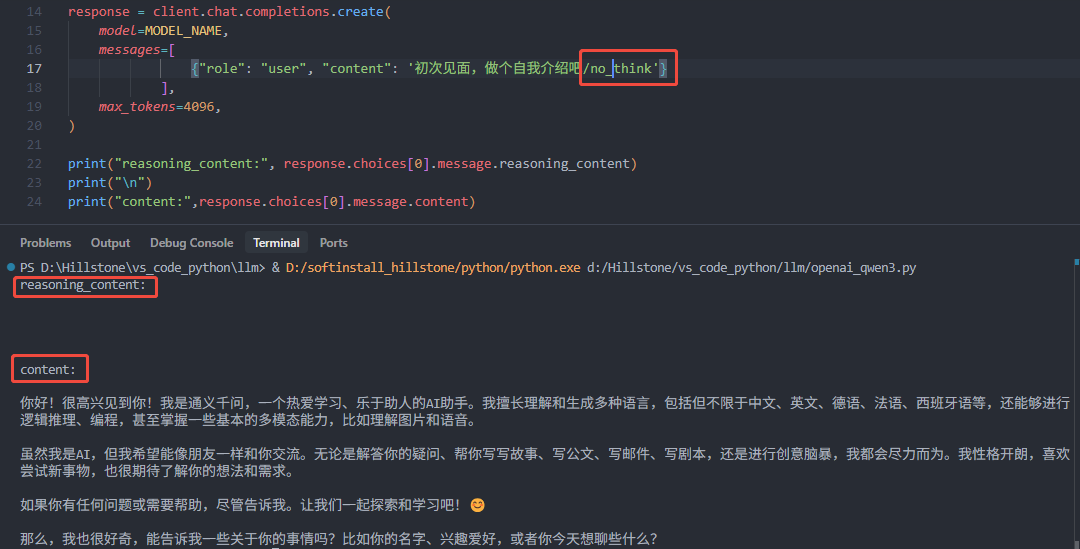
四、其它部署方式
- Qwen3 Moe架构可选:vllm>=0.8.4,sglang >=0.4.6.post1,Ktransformers>=0.3、ollama >=0.6.6、llamacpp、lm studio(尤其适合Mac M芯片)等
- Qwen3 Dense架构:除上述Ktransformers外,其他均可。
- 国产NPU部署:华为自研的MindIE等
除了上述外,还有像lm deploy、xinference、fastchat等,陆陆续续都会支持。
扩展:Qwen3系列模型训练方式
- Pre-Training,共使用36T Tokens,是Qwen2.5的两倍:
- 阶段1:30T 4k上下文长度的tokens训练,让模型学习语言能力和通用知识
- 阶段2:额外5T tokens训练,包括数学、代码、推理、STEM等类型数据
- 长文本训练:32k上下文的高质量长文本数据训练,提高模型长文本场景能力
- Post-Training,针对Qwen3-235B-A22B和Qwen3-32B模型(其他模型是在base模型蒸馏得到):
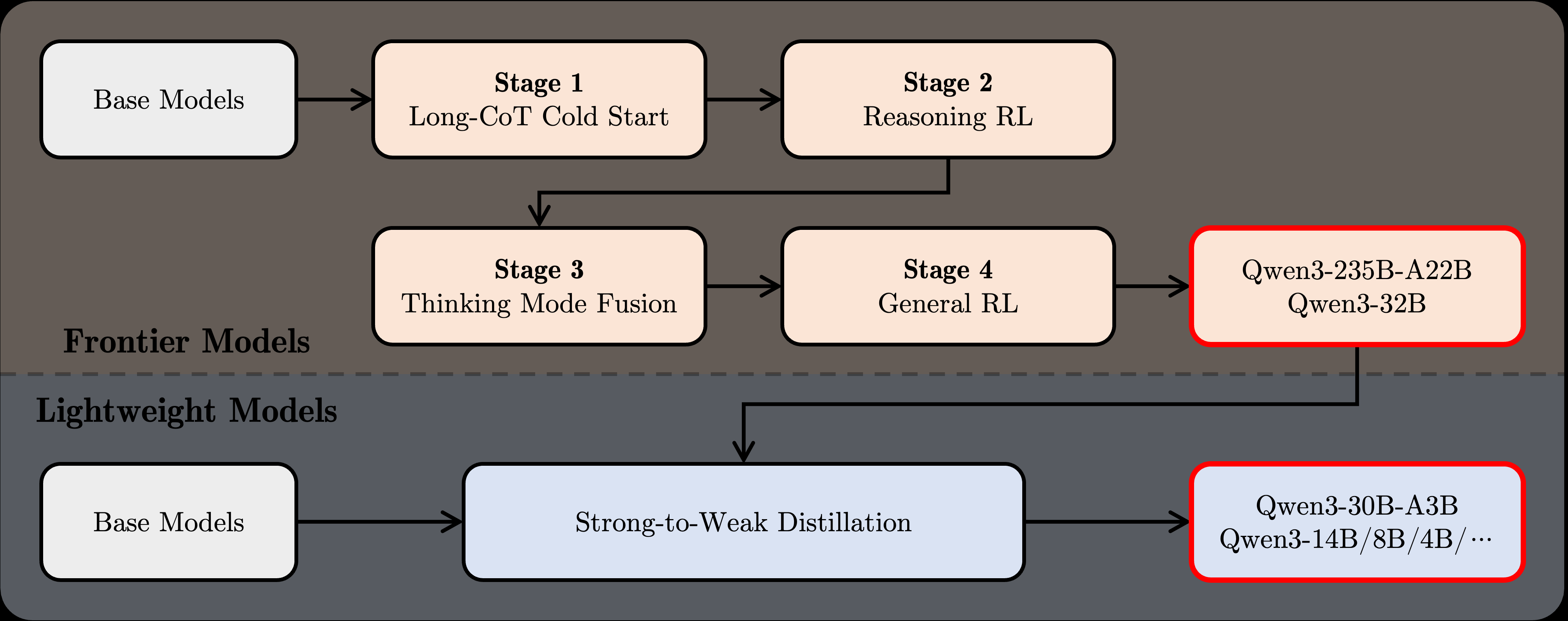
- 长思维链冷启动:使用数学、代码、推理、SEM等数据微调,模型可具有推理能力
- 长思维链强化学习:RL进一步提升模型的推理能力
- 思维模式混合:长推理数据与指令数据微调,模型可具有两种思维模式
- 通用强化学习:使用RL对模型的各项通用能力进行强化提升
五、如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献251条内容
已为社区贡献251条内容

所有评论(0)