字节跳动创新开源:终身记忆多模态智能体,长时记忆与RL结合,性能超越Gemini-GPT4o!
字节跳动最新开源的M3-Agent突破了传统AI智能体的局限,构建了首个具备终身记忆更新的全多模态智能体系统。该技术通过多模态实体对齐和记忆图谱构建,解决了传统方法在身份识别、细节记忆和知识沉淀方面的三大痛点。系统采用双流程架构:Memorization流程持续处理视听信息并更新实体记忆图谱,Control流程通过强化学习实现多轮智能检索。核心技术包括人脸/声纹识别、并查集数据结构维护实体关系、以
字节又偷摸开源了,一个带记忆的Agent。 看起来不稀奇,但是这可能全球首个带终身记忆更新的全多模态智能体。
这玩意儿的核心,是给Agent装上了一个真正意义上的“长期记忆”大脑,能边看边听边记,还能像人一样推理总结。
背后也不是靠堆参数,而是一套全新的关于记忆智能体的架构思想。所以,今天,给家人们分享一下这个工作。
论文: https://arxiv.org/pdf/2508.09736
github: https://github.com/ByteDance-Seed/m3-agent
一、背景
讲 M3-Agent 之前,得先知道它解决了什么问题。
现在的Agent处理长视频或者长对话,主要靠两种方法:一是超长上下文窗口,简单粗暴;二是传统的RAG,把视频切片描述存起来再检索。但这两种方法都有致命缺陷:
-
身份识别混乱: 一个视频里,“穿红衣服的男人”可能在不同时间点被描述成不同的人,Agent没法把他们关联起来。
-
关键细节遗忘: RAG召回的只是文本片段,很多视觉、听觉的细节和它们之间的关系都丢失了。
-
知识无法沉淀: Agent只是被动检索,无法从具体事件中提炼出“小明喜欢喝咖啡”这样的通用知识。
二、M3-Agent:给AI装上实体记忆图谱
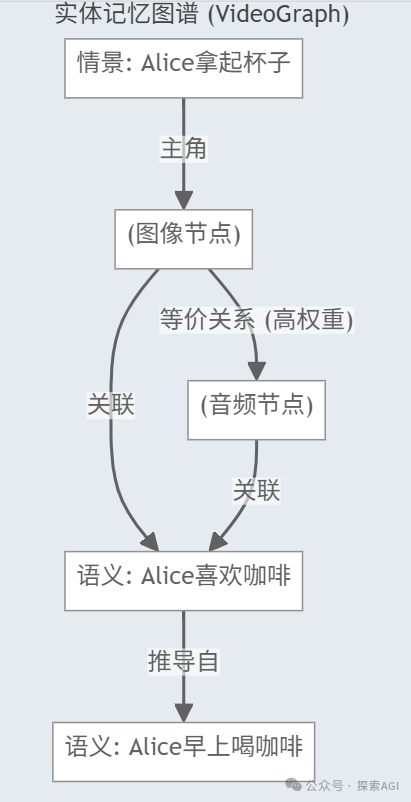
M3-Agent 的解法非常干脆:别再把记忆当成一堆无序的文本了,而是构建一个以实体为中心的多模态记忆图谱(VideoGraph)。
M3-Agent 的架构包含两个并行工作的流程:
-
**Memorization:**持续不断地处理视频流和音频流,提取信息,并构建和更新那个实体记忆图谱。它会同时生成两种记忆:
-
情景记忆 (Episodic Memory): 记录具体发生了什么。例如,“
<face_1>拿起杯子说,‘早上没这个我可不行’”。 -
语义记忆 (Semantic Memory): 提炼出通用知识。例如,“
<face_1>的名字是Alice”,“Alice早上喜欢喝咖啡”。
-
-
Control: 当收到用户指令时,它会利RL训练出的策略,自主地进行多轮思考和检索,从记忆图谱里捞取最相关的信息,最终完成任务。
三、看看代码:记忆系统是如何实现的?
我深入看了看他们开源的代码,
多模态实体对齐
M3-Agent 最硬核的一步,通过一套工具组合,把视频里的人脸和声音真正对应了起来。
-
mmagent/face_processing.py: 使用RetinaFace检测人脸,然后聚类,给视频里出现的每个独立角色一个唯一的<face_id>。 -
mmagent/voice_processing.py:** 使用pyannote.audio做说话人分离,用ERes2Net提取声纹,给每个说话人一个唯一的<voice_id>。
它会自动挖掘那些只有一个脸和一个声音的“元片段”(meta-clips),高精度地建立 <face_id> 和 <voice_id> 的对应关系。
等价性推理与记忆图谱更新
拿到这些实体后,M3-Agent 会在语义记忆中生成等价记录,比如 Equivalence: <face_1>, <voice_1>。
在 mmagent/videograph.py 中,它用了一个非常经典的数据结构——并查集 (Union-Find) 来高效地维护这些等价关系。当新的证据进来,比如发现 <face_1> 和 <voice_2> 也可能是同一个人,图谱会通过加权投票的机制来动态更新连接,确保长期的一致性。大概是下图这个感觉:
RL驱动的迭代式检索
传统RAG是一锤子买卖,搜到啥算啥。而 M3-Agent 包含一个控制模块 ,在mmagent/retrieve.py ,是一个会思考的分析模块。
面对一个复杂问题,它会进行最多5轮的迭代检索。比如第一轮搜“Tomasz是谁”,找到ID是<character_4>;第二轮搜“<character_4>的性格”,如果没结果,它会推理出新策略,第三轮去搜“<character_4>作为CTO有哪些创新行为”,通过这种方式层层递进,最终找到答案。
四、跑分数据很牛
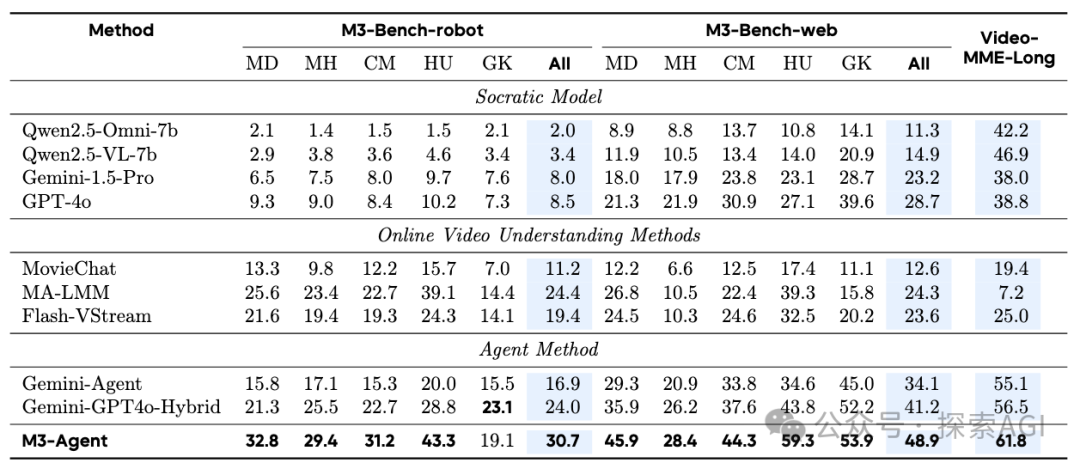
代码开源的,https://github.com/ByteDance-Seed/m3-agent。
整个系统的核心就是构建一个更像人脑、更结构化的、可持续学习的长期记忆系统。
五、AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献160条内容
已为社区贡献160条内容

所有评论(0)