重磅!GPT-5正式发布:史上最强编码&智能体模型来了
当你以为 AI 已经够聪明了,它又一次刷新了你的认知。OpenAI 重磅官宣 —— GPT-5 正式登场!这不仅是一次版本升级,更是一场颠覆。它在权威编码测试中全面领跑,在真实企业项目中成为工程师的得力拍档;能写前端、能修漏洞、能解读复杂代码库,还能像经验丰富的团队成员一样完成长链路、多工具的智能体任务。一句话总结:这就是你梦寐以求的“全能型 AI 编程搭档”。编码能力行业第一SWE-bench
重磅!GPT-5正式发布:史上最强编码&智能体模型来了
当你以为 AI 已经够聪明了,它又一次刷新了你的认知。
OpenAI 重磅官宣 —— GPT-5 正式登场!
这不仅是一次版本升级,更是一场颠覆。
它在权威编码测试中全面领跑,在真实企业项目中成为工程师的得力拍档;能写前端、能修漏洞、能解读复杂代码库,还能像经验丰富的团队成员一样完成长链路、多工具的智能体任务。
一句话总结:这就是你梦寐以求的“全能型 AI 编程搭档”。
亮点速览
-
编码能力行业第一
SWE-bench Verified 测试 74.9%,Aider polyglot 88%,无论是单文件修复还是跨模块改造,都能精准高效完成。 -
前端开发更强
在 70% 的 Web 开发任务中超越 OpenAI o3,UI 组件、交互逻辑、响应式布局,一次到位。 -
智能体任务飞跃
在最新 τ2-bench telecom 基准测试中,工具调用成功率高达 96.7%,可连续串联数十步任务,路径不跑偏。 -
事实更准确
长文本推理和信息检索的错误率仅为前代的五分之一。
想象一下,你在调试一个几千行的项目:
只需一句话,GPT-5 就能读懂全局逻辑,精确指出 bug 所在,给出修复方案并直接帮你改好。
或者,你要部署一个跨平台应用,它能帮你一键生成前端、后端代码,并自动调用工具完成环境搭建和测试,像个 24 小时在线、不抱怨的全栈工程师。
编码能力行业第一:速度更快、效率更高
在真实软件工程任务的 SWE-bench Verified 基准测试中,GPT-5 以 74.9% 的得分刷新行业纪录,超越 o3 版本的 69.1%。更令人惊讶的是,它并不是靠“多耗资源”取胜——在高推理强度下,GPT-5 平均输出令牌减少 22%,工具调用次数减少 45%,意味着它能用更短的时间和更少的步骤,完成同样甚至更复杂的任务。
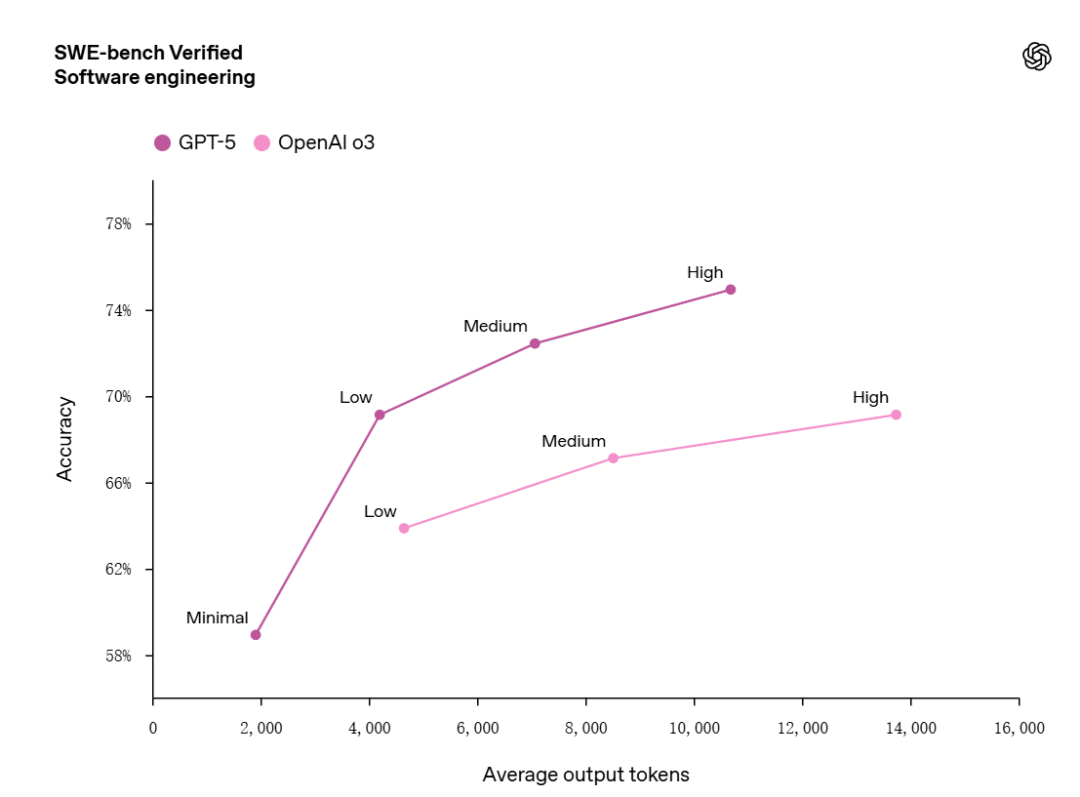
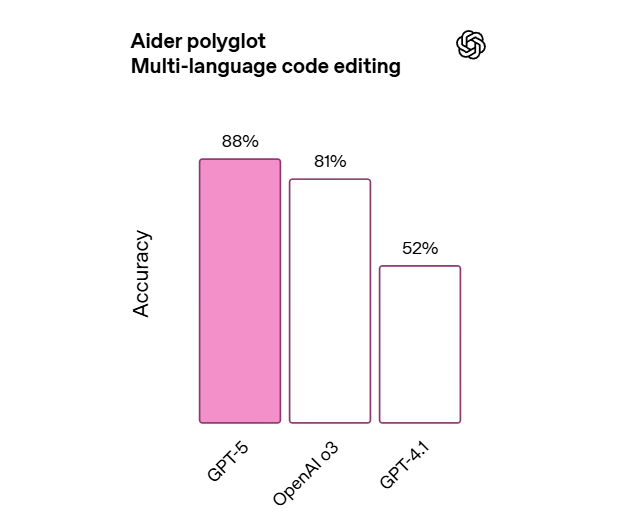
在 Aider polyglot 多语言代码编辑测试中,GPT-5 更是以 88% 的准确率创下新高,错误率相比 o3 降低 三分之二。
这意味着无论是 Python、JavaScript、Java 还是其他主流语言,它都能在一次交互中完成精准的修改与优化。
💡 这是什么概念?
想象一下,你在处理一个跨语言的大型项目:
- 以前:你可能需要多轮修改,才能让 AI 把 Python 后端与 React 前端的接口逻辑对齐。
- 现在:GPT-5 一次就能搞定,不仅写出可运行的代码,还会帮你检查潜在的兼容性问题,并在必要时调用工具完成测试。
这种“快、准、省”的能力,不仅提升了个人开发效率,对团队协作、企业级项目交付来说,更意味着成本和时间的大幅节省。
前端工程:一稿成型、细节到位
在为 Web 应用生成前端代码时,GPT-5 审美、能力与准确性全面提升——与 o3 的并排对比中,70% 的案例更受测试员青睐。单次提示即可完成从设计到落地的整套工作流:
- 设计到代码:将界面描述/组件草图直接落地为 React/Next.js + Tailwind,结构清晰、命名规范。
- 响应式与主题:自动处理断点、深浅色与可定制主题;移动端细节(手势、点击区域、输入法占位)到位。
- 可访问性 & i18n:自动补齐 ARIA、键盘导航、对比度;内置中英等多语言文案抽取与切换。
- 工程化质量:表单校验、路由权限、状态管理接入;生成单测/端测样例并给出 CI 配置;按需拆包与性能预算(LCP/CLS)优化建议。
- 数据与可视化:接口契约(TS 类型)与错误边界同步生成;图表组件接入与空态/加载态处理完善。
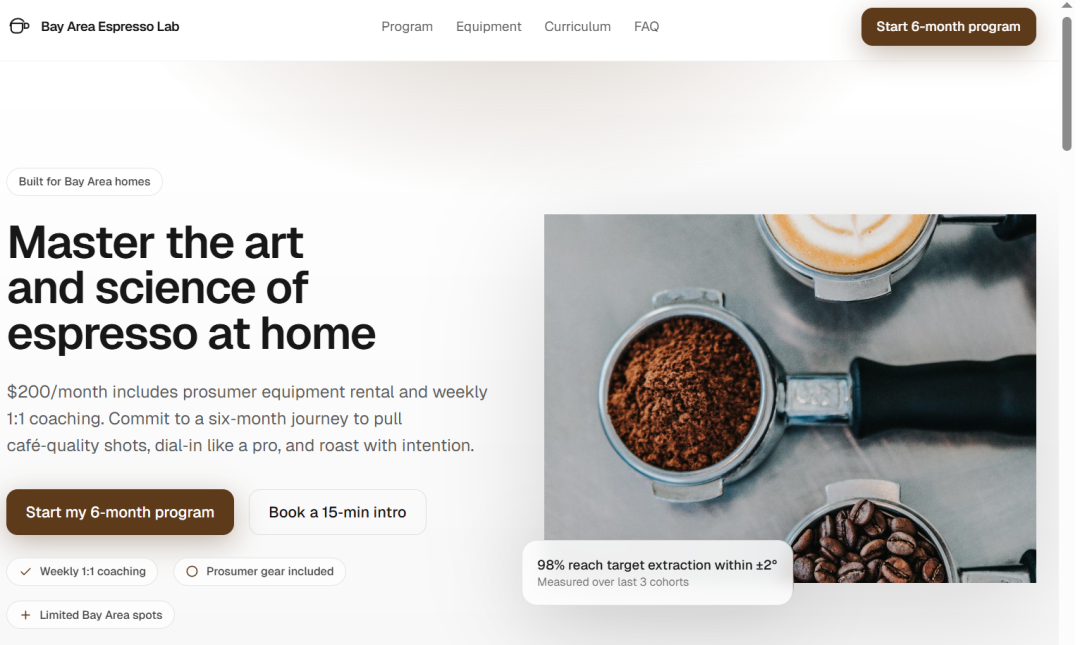
下图为GPT-5生成的前端工程实例:
编码协作:会解释、会计划、会执行
GPT-5 不只是写代码,更像一名可靠的协作者。在 Cursor、Windsurf、Codex CLI 等产品中,它能在工具调用前/中/后 主动输出执行计划、状态更新与操作摘要,复杂任务也不“等指令”:
- 更少往返:在高推理强度下,用 更少输出令牌与更少工具调用 完成同等任务,减少无效沟通。
- 路径一致性强:长链路任务中保持方案不跑偏,能并行/串行组织多步操作并自查结果。
- 稳健容错:遇到构建失败、依赖冲突或接口变更,会自行回溯、修复并给出变更日志。
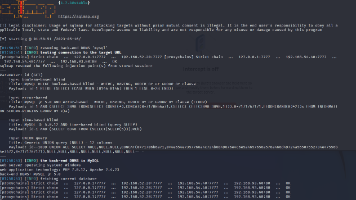
以下示例展示了 GPT‑5 处理复杂任务时的运行状态(本例中是为一家餐厅创建网站):
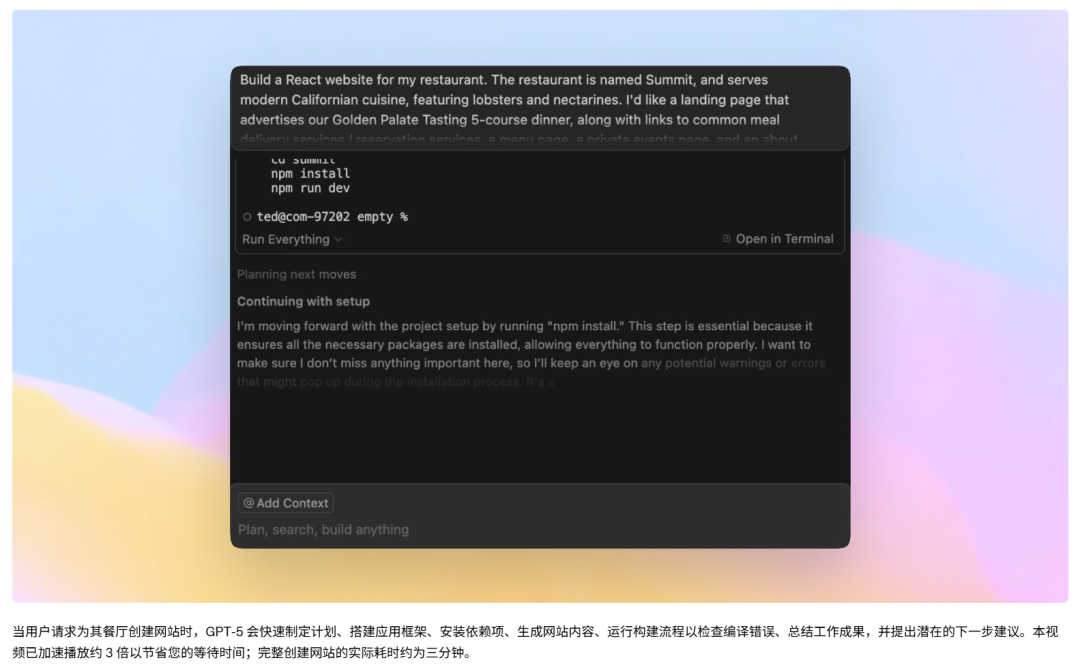
智能体任务:多步推理与工具调用的天花板
除了在编码领域的统治级表现,GPT-5 在各类智能体任务中同样拔得头筹。
- 指令遵循:在 Scale MultiChallenge 基准上,GPT-5 得分 69.6%(o3-mini 评分),创下新高。
- 工具调用:在 τ2-bench telecom 高难度评估中,以惊人的 96.7%(官方报告取整为 97%)刷新纪录——相比两个月前 Sierra.ai 发布基准时所有参测模型“不超过 49%”的成绩,这几乎是一次“代际飞跃”。
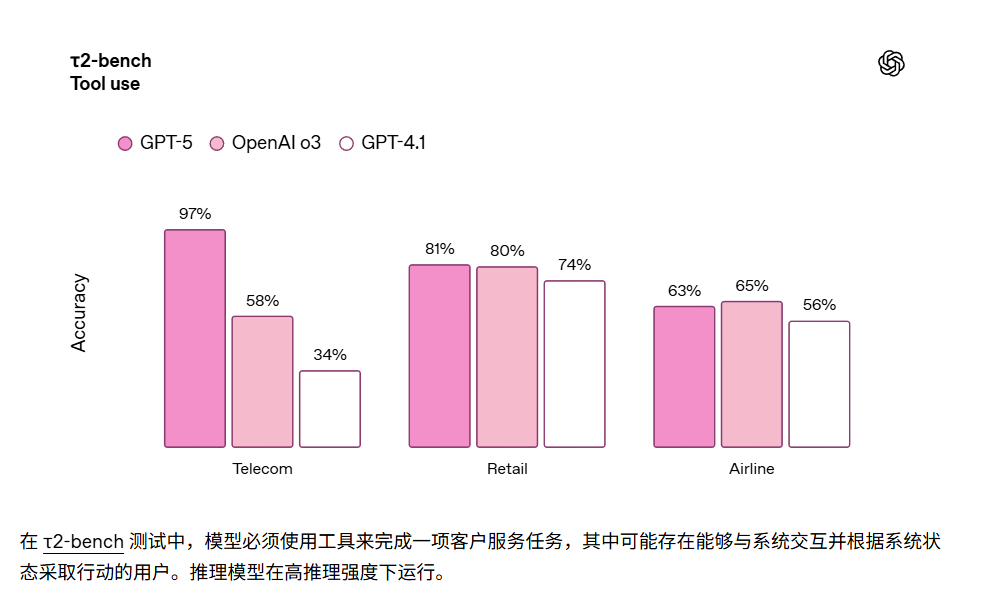
💡 为什么重要?
真实世界任务往往不是一句话能完成的,而是需要串联多步操作:数据检索 → 分析 → 调用外部 API → 处理异常 → 整合结果。GPT-5 的增强型工具智能,让它可以:
- 可靠串联多步骤:支持串行/并行多工具调用,并保持路径一致性。
- 容错与自愈:遇到 API 变更、调用失败、环境冲突时,可自主修复并重试。
- 过程透明:在执行长任务时,会在工具调用前及过程中输出进度更新、操作摘要,让用户实时掌握状态。
长背景信息与事实性:更懂上下文,更值得信赖
在长背景信息处理上,GPT-5 取得了跨代跃升。
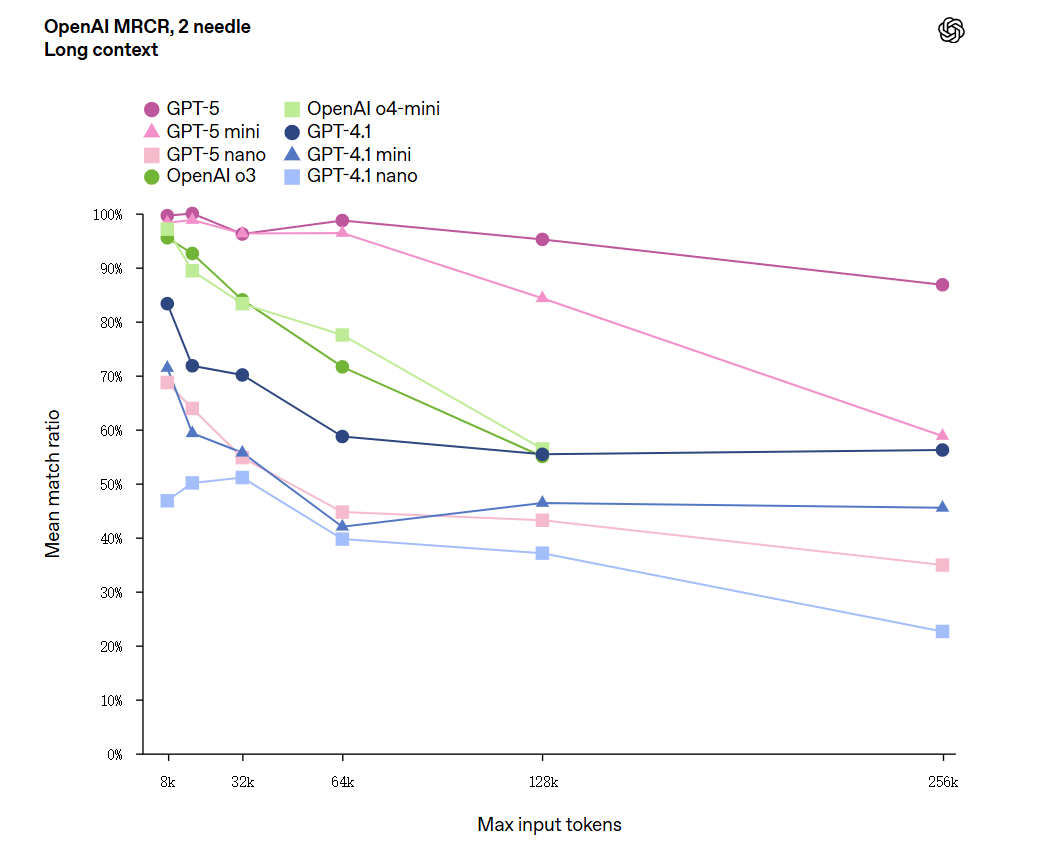
- 长背景检索能力:在 OpenAI-MRCR 基准中,GPT-5 表现显著优于 o3 和 GPT-4.1,且输入越长优势越大。在 128K–256K 令牌范围内,正确率高达 89%。
- 超长上下文支持:API 版本可处理 272,000 输入令牌,并生成 128,000 推理+输出令牌,总上下文长达 40 万个令牌,适配长篇文档解析、跨章节对话、历史会话回溯等复杂场景。
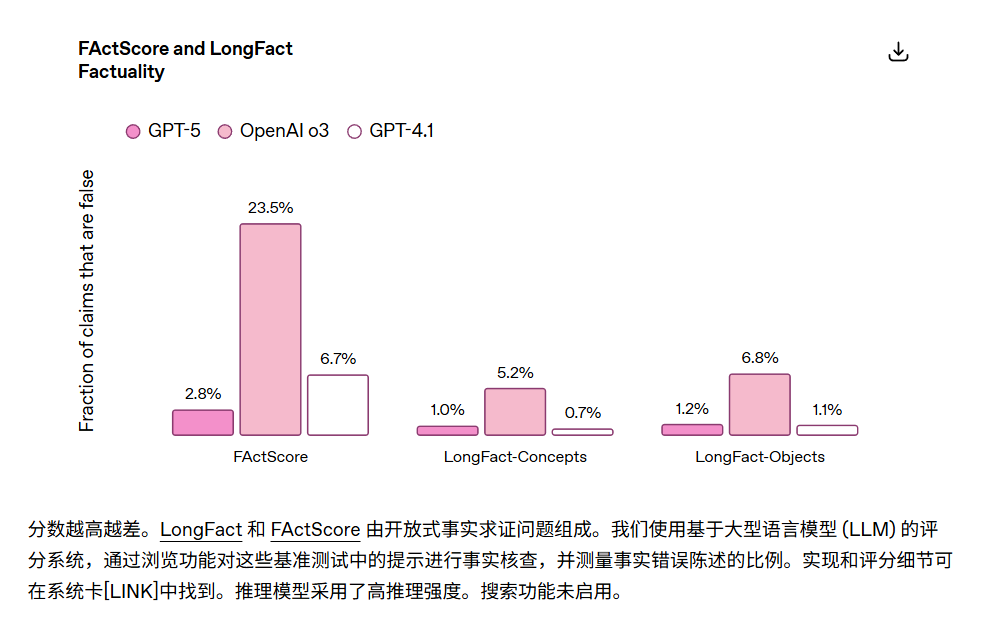
不仅“记得住”,GPT-5 还更“说得准”:
- 事实性提升:在 LongFact 和 FActScore 基准测试中,事实错误率比 o3 低 约 80%,在某些子项中甚至低至 0.7%。
- 关键领域可靠性:在代码生成、数据分析、决策支持等高准确性任务中表现稳定,尤其适合对错误零容忍的场景(如法律、金融、医疗参考)。
社区地址
GPT-5快速打开:
https://openai.com/gpt-5/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)