实战揭秘|魔搭社区 + 阿里云边缘云 ENS,快速部署大模型的落地实践
大模型部署流程、配置及效果验证全归纳。

一种高效、便捷的部署方式。
随着大模型技术的快速发展,业界的关注点正逐步从模型训练往模型推理转变。这一转变不仅反映了大模型在实际业务中的广泛应用需求,也体现了技术优化和工程化落地的趋势。
魔搭社区(ModelScope)作为开源大模型的聚集地,结合阿里云边缘云 ENS ,提供了一种高效、便捷的部署方式。通过按需付费和弹性伸缩,开发者可以快速部署和使用大模型,享受云计算的便利。本文介绍了魔搭社区与阿里云边缘云 ENS 的结合使用体验,包括部署流程、环境配置、效果验证等内容。
魔搭社区(ModelScope)是中国规模和影响力最大的开源模型社区 。致力于构建模型即服务(MaaS)生态,提供从模型探索、体验、训练、推理到部署的一站式服务。该平台汇聚了超过 5 万个 AI 模型,涵盖自然语言处理、计算机视觉、语音、多模态、科学计算等领域,服务超过 1400 万开发者。
阿里云边缘云 ENS 是由大规模地域分散的边缘节点相互协同组成的一朵可远程管控,安全可信,标准易用的分布式云。以广覆盖为核心定位,为客户提供低时延、本地化、小型化三大核心价值。全球拥有超过 3200 个边缘节点,中国内地省份与运营商 100% 覆盖,海外覆盖 70+ 重点国家和地区。
01 |
如何新建部署入口
——
进入魔搭社区 - 模型服务 - 部署服务(SwingDeploy) - 免费部署到魔搭推理API - 新建部署。

魔搭社区新建部署界面
02|
模型选择和服务部署配置
——
1、模型选择
社区提供了热门模型的优先推荐列表,也支持通过搜索功能为您查找特定模型。下面我们以 Qwen3-8B-GGUF 为例进行介绍,其可以运行在免费 GPU 资源上。

2、服务部署配置
| 基础配置
针对该模型,我们选择 Ollama 作为推理框架,并在免费部署资源中选用边缘节点服务(ENS)进行部署。对于其他模型,您可以根据需求灵活选择推理框架、以及 CPU 部署或 GPU 部署。

SwingDeploy 基础配置设置
单账号配额:
- 支持10个免费 CPU 服务实例、1个 GPU 服务实例。
- 当资源不够时,服务创建会报错,并且服务状态为资源不足。
- 当前免费算力供应紧张,正在安排扩容,请保持关注。
|高级配置
- 支持在列表中更换模型文件,以选择特定的量化版本。
- SwingDeploy 提供默认的 Modelfile配置文件,同时也支持用户自定义编辑。
- 如有需要,可自定义配置环境变量。

SwingDeploy 高级配置设置
完成上述操作后,点击右下角“一键部署”按钮,即可开始部署服务。
模型部署需要一定耗时,包括模型下载、制作、资源生产和部署,请您耐心等待。可以在 SwingDeploy 控制台确认服务状态。

SwingDeploy 控制台
03|
效果验证
——
在部署任务列表中,点击具体任务操作列下的“详情”按钮,即可查看任务详情。详情页展示服务实例的创建时间、更新时间、实例类型、模型文件、推理框架、部署资源及参数等信息,并提供一份示例代码,支持通过 OpenAPI SDK 进行调用。
以下代码基于示例代码改造,实现了一个简易的终端问答Bot,用于测试模型效果。我们优化了终端的输入输出交互体验。如需运行此代码,请根据您在魔搭部署任务详情页中的配置信息,替换服务地址、API Key 以及模型路径。
from openai import OpenAI
import sys
from prompt_toolkit import PromptSession
from prompt_toolkit.styles import Style
import time
import tiktoken
import shutil
# 初始化 OpenAI 客户端,base_url,api_key,model请按实际情况填写。
client = OpenAI(
base_url=<填写魔搭侧的服务地址>,
api_key=<填写魔搭侧的服务api_key>
)
model = <填写模型路径,如unsloth/Qwen3-8B-GGUF>
def num_tokens_from_string(string: str) -> int:
"""计算文本中的 tokens 数量"""
encoding = tiktoken.get_encoding("cl100k_base")
num_tokens = len(encoding.encode(string))
return num_tokens
def get_terminal_size():
"""获取终端大小"""
return shutil.get_terminal_size()
def clear_current_line():
"""清除当前行"""
terminal_width = get_terminal_size().columns
print('\r' + ' ' * terminal_width + '\r', end='', flush=True)
def chat_with_model():
# 创建 prompt session 和自定义样式
session = PromptSession()
style = Style.from_dict({
'prompt': '#00aa00 bold',
})
messages = [
{
'role': 'system',
'content': '你是一个有帮助的助手。'
}
]
print("欢迎使用AI助手!输入'退出'或'quit'可以结束对话。")
while True:
try:
# 使用 prompt_toolkit 处理输入
user_input = session.prompt('\n你: ', style=style)
if user_input.lower() in ['退出', 'quit']:
print("再见!")
break
messages.append({
'role': 'user',
'content': user_input
})
print("\nAI助手: ", end='', flush=True)
try:
start_time = time.time()
response = client.chat.completions.create(
model=model,
messages=messages,
stream=True
)
full_response = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end='', flush=True)
full_response += content
end_time = time.time()
elapsed_time = end_time - start_time
# 计算 tokens
response_tokens = num_tokens_from_string(full_response)
tokens_per_second = response_tokens / elapsed_time
# 确保统计信息显示在新行,并在显示后额外添加换行
print("\n") # 先确保有一个空行
stats = f"[统计] 响应tokens: {response_tokens}, 用时: {elapsed_time:.2f}秒, 速率: {tokens_per_second:.2f} tokens/s"
print(stats)
print() # 添加额外的换行确保滚动
sys.stdout.flush() # 强制刷新输出缓冲区
messages.append({
'role': 'assistant',
'content': full_response
})
except Exception as api_error:
print(f"\n请求API时发生错误: {str(api_error)}")
print() # 额外的换行
continue
except KeyboardInterrupt:
print("\n\n检测到中断,正在退出...")
print() # 额外的换行
break
except Exception as e:
print(f"\n发生错误: {str(e)}")
print() # 额外的换行
continue
if __name__ == "__main__":
try:
chat_with_model()
except Exception as e:
print(f"程序发生错误: {str(e)}")
print() # 额外的换行
sys.exit(1)
服务运行后,效果展示如下:

服务运行后,效果展示
效果展示:魔搭社区+阿里云边缘云ENS,快速部署大模型
通过本文的介绍,我们展示了如何利用魔搭社区(ModelScope)与阿里云边缘云ENS相结合,快速部署和验证大模型的实际效果。
未来,随着大模型技术的不断演进和应用场景的持续拓展,我们相信这种“模型即服务”(MaaS)的模式将为更多企业和开发者带来创新机遇。
希望本文能为您提供有价值的参考,也期待您在实际项目中探索出更多可能性。
让我们一起拥抱大模型时代,共同推动技术落地与业务升级!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
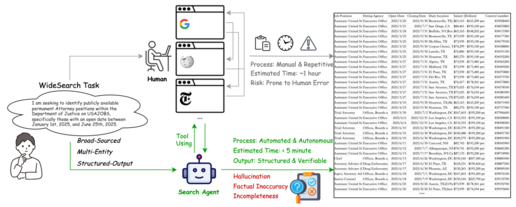

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)