ai智能体开发(可对接医院挂号系统)——不是简单调大模型的对话网站!
有一个问题就是默认的两种聊天记忆的实现是基于内存的,但是官网建议存到redis或者Mongdb等存储介质中,我想问,redis也是基于内存的啊,为什么推荐把聊天基于存储到redis内存而不是我们默认的内存?首先要明确一点,默认的两种存储是存在JVM内存的,源码new ArrayList(),new ConcurrentHashMap(),大容量对话历史会挤占应用内存!而redis存储是存在redi
本项目的智能体通过调用相关大模型api,能像通用大模型对话网站一样准确解答你的各种需求比如写代码,解决常规办错报错等,但本项目的核心是如何让通用大模型变得更加专业,成为能访问业务系统,学习行业业务数据的行业大模型应用,比如医院里的伴诊助手实现患者意图识别与智能分诊(通过rag检索增强生成,得到我院相关科室、医生等详情),预约挂号与取消预约(大模型通过函数调用访问修改一业务数据库,大模型与 Java业务系统是双向集成的,可以在java业务系统中调用大模型,同时也允许大模型通过函数调用访问控制Java业务系统)
依赖与配置
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-boot.version>3.2.6</spring-boot.version>
<knife4j.version>4.3.0</knife4j.version>
<langchain4j.version>1.0.0-beta3</langchain4j.version>
<mybatis-plus.version>3.5.11</mybatis-plus.version>
</properties>
<dependencies>
<!-- web应用程序核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 编写和运行测试用例 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 前后端分离中的后端接口测试工具 -->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>${knife4j.version}</version>
</dependency>
<!-- 基于open-ai的langchain4j接口:ChatGPT、deepseek都是open-ai标准下的大模型 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
</dependency>
<!-- 接入ollama -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama-spring-boot-starter</artifactId>
</dependency>
<!-- 接入阿里云百炼平台 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>
<!--langchain4j高级功能-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>
<!-- Spring Boot Starter Data MongoDB -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<!-- Mysql Connector -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<!--mybatis-plus 持久层-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!--解析pdf文档-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
</dependency>
<!--简单的rag实现-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pinecone</artifactId>
</dependency>
<!--流式输出-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!--引入SpringBoot依赖管理清单-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--langchain4j的依赖清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>1.0.0-beta3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--引入百炼依赖管理清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement> dependencyManagement里维护资源依赖管理清单:通过引入BOM(如spring-boot-dependencies或langchain4j-bom),可以自动管理相关依赖的版本,无需在<dependencies>中手动写版本号。配置spring-boot-dependencies后,所有Spring官方依赖(如spring-boot-starter-web)无需写版本,版本由BOM自动锁定。配置langchain4j-bom后,所有dev.langchain4j下的依赖(如langchain4j-core)也无需写版本。
你说不要配版本信息,为什么<properties>里还是定义了springboot的版本信息 <spring-boot.version>3.2.6</spring-boot.version>和 angchain4j的版本信息呢<langchain4j.version>1.0.0-beta3</langchain4j.version>? 明确不要配版本信息是“无需在<dependencies>中手动写版本号“!你看看<dependencies>下是不是只有没配置依赖清单的knife4j配置了版本号!
-
明确指定BOM版本
<spring-boot.version>用于指定引入的spring-boot-dependencies清单本身的版本(BOM文件也需要版本控制)。 -
统一版本修改入口
若需升级Spring Boot,只需修改<spring-boot.version>一处,所有关联的BOM和依赖自动同步更新。 -
非Spring官方依赖的扩展性
即使Spring Boot自身依赖无需写版本,但项目中其他库(如knife4j)可能需要与Spring Boot版本兼容,通过属性变量可集中管理。
总结:<properties>中的版本定义是为了控制BOM本身的版本,而非冗余配置。
接着去阿里云百炼平台申请apikey(deepseek也可以去这申请,比官网划算)。apikey明文些到配置文件其实也不安全,打包后的代码可能会被泄露!这样就泄露了apikey。配置在环境变量中,配置文件用${}获取配置的环境变量。
#web服务的端口号
server.port=8080
langchain4j.open-ai.chat-model.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1
langchain4j.open-ai.chat-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.open-ai.chat-model.model-name=deepseek-v3
#应用程序发送给大模型的请求日志和响应日志
langchain4j.open-ai.chat-model.log-requests=true
langchain4j.open-ai.chat-model.log-responses=true
langchain4j.ollama.chat-model.base-url=http://localhost:11434
langchain4j.ollama.chat-model.model-name=deepseek-r1:1.5b
langchain4j.ollama.chat-model.temperature=0.8
langchain4j.ollama.chat-model.timeout=PT60S
#应用程序发送给大模型的请求日志和响应日志
langchain4j.ollama.chat-model.log-requests=true
langchain4j.ollama.chat-model.log-responses=true
#阿里百炼平台
langchain4j.community.dashscope.chat-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.community.dashscope.chat-model.model-name=qwen-max
#集成阿里通义千问-流式输出
langchain4j.community.dashscope.streaming-chat-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.community.dashscope.streaming-chat-model.model-name=qwen-plus
#集成阿里通义千问-通用文本向量-v3
langchain4j.community.dashscope.embedding-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.community.dashscope.embedding-model.model-name=text-embedding-v3
#MongoDB连接配置
spring.data.mongodb.uri=mongodb://localhost:27017/chat_memory_db
# 基本数据源配置
spring.datasource.url=jdbc:mysql://localhost:3306/guiguxiaozhi?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
spring.datasource.username=root
spring.datasource.password=qweasdzxc
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# 开启 SQL 日志打印
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
#将系统日志设置为debug级别
logging.level.root=info好的,接下来写测试用例跑起来:
package com.HUTB.java.ai.langchain4j;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class XiaozhiApp {
public static void main(String[] args) {
SpringApplication.run(XiaozhiApp.class, args);
}
}package com.HUTB.java.ai.langchain4j;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.community.model.dashscope.WanxImageModel;
import dev.langchain4j.data.image.Image;
import dev.langchain4j.model.ollama.OllamaChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.output.Response;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.net.URI;
@SpringBootTest
public class LLMTest {
@Test
public void testGPTDemo() {
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("http://langchain4j.dev/demo/openai/v1")
.apiKey("demo")
.modelName("gpt-4o-mini")
.build();
String answer = model.chat("你是谁呀");
System.out.println(answer);
}
@Autowired
private OpenAiChatModel openAiChatModel;
//private ChatLanguageModel chatLanguageModel;
@Test
public void testSpringBoot() {
String answer = openAiChatModel.chat("你是谁?");
System.out.println(answer);
}
@Autowired
private OllamaChatModel ollamaChatModel;
@Test
public void testOllama() {
String answer = ollamaChatModel.chat("你是谁?");
System.out.println(answer);
}
/**
* 通义千问大模型
*/
@Autowired
private QwenChatModel qwenChatModel;
@Test
public void testDashScopeQwen() {
//向模型提问
String answer = qwenChatModel.chat("你好");
//输出结果
System.out.println(answer);
}
@Test
public void testDashScopeWanx(){
WanxImageModel wanxImageModel = WanxImageModel
.builder()
.modelName("wanx2.1-t2i-turbo")
.apiKey(System.getenv("DASH_SCOPE_API_KEY"))
.build();
Response<Image> response = wanxImageModel.generate("奇幻森林精灵:在一片弥漫着轻柔薄雾的古老森林深处,阳光透过茂密枝叶洒下金色光斑。一位身材娇小、长着透明薄翼的精灵少女站在一朵硕大的蘑菇上。她有着海藻般的绿色长发,发间点缀着蓝色的小花,皮肤泛着珍珠般的微光。身上穿着由翠绿树叶和白色藤蔓编织而成的连衣裙,手中捧着一颗散发着柔和光芒的水晶球,周围环绕着五彩斑斓的蝴蝶,脚下是铺满苔藓的地面,蘑菇和蕨类植物丛生,营造出神秘而梦幻的氛围。");
URI url = response.content().url();
System.out.println(url);
}
}
model的chat方法封装httpcilnt底层的远程请求代码,这种远程的请求代码还是比较复杂的尤其是涉及封装复杂json时。
ollama本地部署大模型,像安装一个mysql一样简单!为什么要本地部署?帮助涉及大量敏感数据的行业使用大模型!无需联网!可微调!
上述代码涉及Builder 建造者模式,该模式已成为Java生态中复杂对象构造的事实标准,尤其在需要高可读性和灵活性的场景中。
-
分离构造逻辑:将对象的构造过程(
builder())与表示(OpenAiChatModel)分离。 -
链式调用:通过方法级联(Method Chaining)提高代码可读性。
-
不可变对象:通常
build()返回的对象是线程安全的。
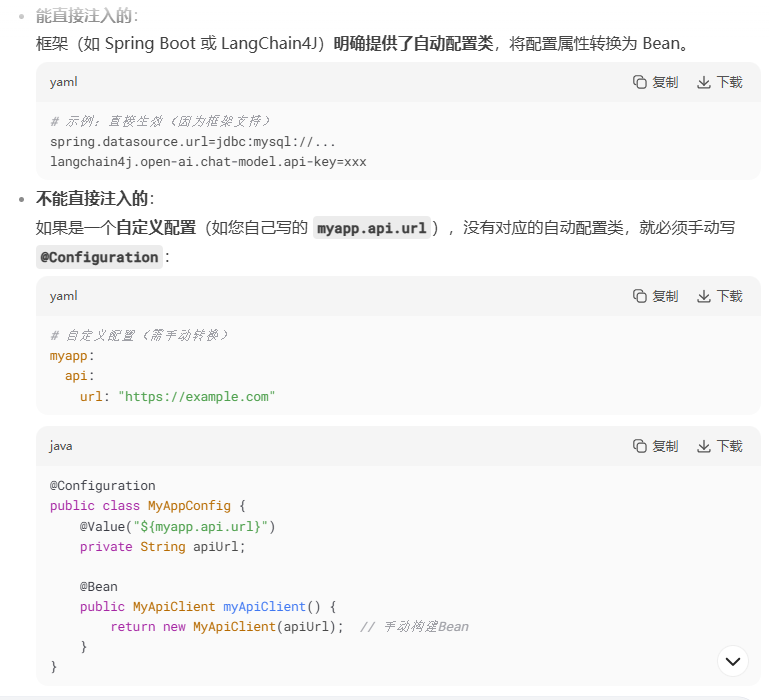
这里的依赖注入没有使用到,我们没有使用@Component、@Service、@Repository、@Controller 等注解注册bean,没有使用@Configuration + @Bean配置第三方bean,怎么就可以依赖注入了?因为 LangChain4J 或 Spring Boot 的自动配置(Auto-Configuration) 提前实现了 @Configuration 类,自动将配置属性绑定到 Bean,完成了从配置到 Bean 的转换,而不是 @Autowired 能直接注入配置文件。底层还是使用了建造者模式和@Configuration注解。
// LangChain4J 内部的自动配置类(简化示例)
@Configuration
@EnableConfigurationProperties(LangChain4JProperties.class) // 自动绑定配置
public class LangChain4JAutoConfiguration {
@Bean
@ConditionalOnProperty(prefix = "langchain4j.open-ai.chat-model")
public OpenAiChatModel openAiChatModel(LangChain4JProperties properties) {
return OpenAiChatModel.builder()
.apiKey(properties.getOpenAi().getChatModel().getApiKey())
.baseUrl(properties.getOpenAi().getChatModel().getBaseUrl())
.build();
}
}
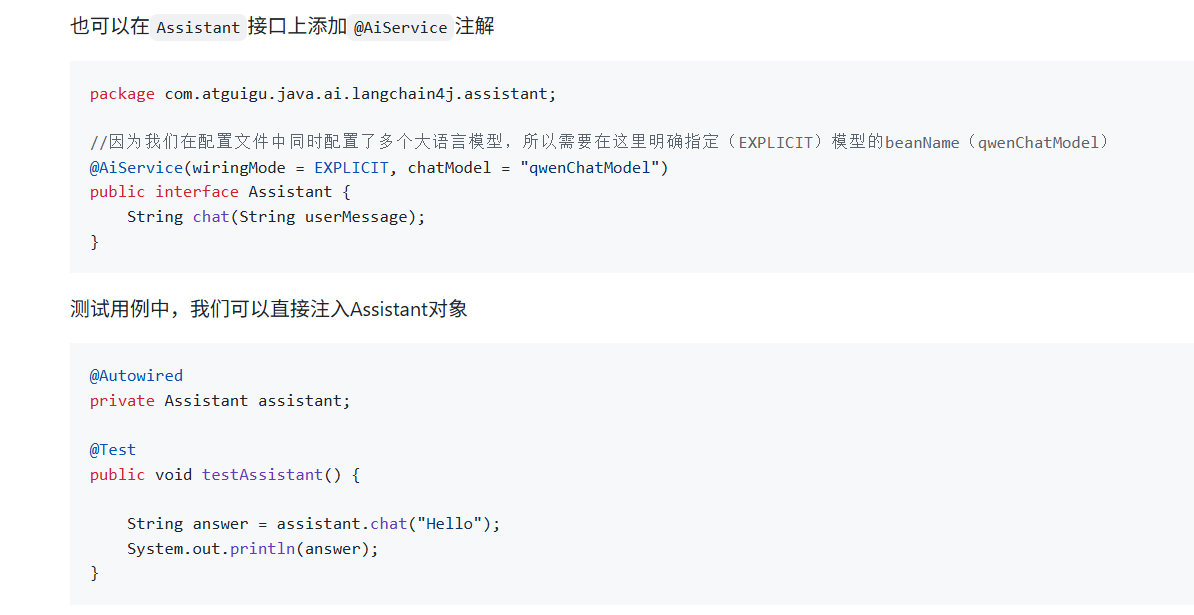
人工智能服务 AIService
AiServices(带s的工具类)会组装Assistant接口以及其他组件(其他组件具体是指chatMemory、tool、rag等,这些组件都是AiService注解的属性,AiService注解源码中可以看到 ),并使用反射机制创建一个实现Assistant接口的代理对象。这个代理对象会处理输入和输出的所有转换工作。在下面的例子中,Assistant接口中只定义一个chat方法,该方法入参是一个字符串,但是大模型需要一个UserMessage对象。所以,代理对象将这个字符串转换为UserMessage,并调用聊天语言模型。chat方法的返回值也是字符串,但是大模型返回的是 AiMessage 对象,代理对象会将其转换为字符串。
| 场景 | 手动调用 AiServices.create() |
使用 @AiService 注解 |
|---|---|---|
| 适用环境 | 纯Java应用(无Spring) | Spring Boot应用 |
| 创建方式 | 显式代码创建 | Spring容器自动代理 |
| 依赖管理 | 需手动管理ChatModel实例 | 自动注入(通过chatModel指定Bean名称) |
| 典型用例 | 单元测试中用 | 生产环境应用 |
本项目我们的Assistant接口是XiaozhiAgent
package com.HUTB.java.ai.langchain4j.assistant;
import dev.langchain4j.service.MemoryId;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.spring.AiService;
import reactor.core.publisher.Flux;
import static dev.langchain4j.service.spring.AiServiceWiringMode.EXPLICIT;
@AiService(
wiringMode = EXPLICIT,
/*chatModel = "qwenChatModel",*/
/*chatMemory = "chatMemory"*/
streamingChatModel= "qwenStreamingChatModel",
chatMemoryProvider = "chatMemoryProviderXiaozhi",
tools = "appointmentTools",
contentRetriever = "contentRetrieverXiaozhiPincone"
)
public interface XiaozhiAgent {
@SystemMessage(fromResource = "zhaozhi-prompt-template.txt")
Flux<String> chat(@MemoryId Long memoryId, @UserMessage String userMessage);
}
上面没讲到的部分,下面细细道来。
聊天记忆chatMemory
通过api调用和大语言模型做对接的话,是没有聊天记忆功能的。这是因为API设计为无状态(stateless),即每次请求都是独立的,模型不会自动记住之前的对话内容。聊天记忆就是每次和大模型会话时带上之前的会话内容(含大模型的回答),使用@AIService注解的chatMemory 属性可以封装如下操作:每次请求时把之前发起的多轮会话内容以及模型返回的多轮会话内容都传给大模型。
要注册一个chatMemory bean对象并让其自动注入到chatMemory属性,所以写一个配置类如下,注意bean的类型是方法名,要和 /*chatMemory = "chatMemory"*/中的等号后面的属性值一样。
package com.HUTB.java.ai.langchain4j.config;
@Configuration
public class XiaozhiAgentConfig {
@Bean
ChatMemory chatMemory() {
//设置聊天记忆记录的message数量
return MessageWindowChatMemory.withMaxMessages(10);
}
}
但是这样做没有做到聊天记忆的隔离,不同用户的不同聊天以及同一用户的不同聊天都需要隔离聊天记忆,一个对话一个聊天记忆!我们就可以用memoryId来隔离聊天记录,使用属性chatMemoryProvider = "chatMemoryProviderXiaozhi",XiaozhiAgent接口的chat方法除了要传我们的对话数据,还要传memoryId。此外要创建chatMemoryProviderXiaozhi这个bean对象并注解到chatMemoryProvide属性中,配置如下:
package com.HUTB.java.ai.langchain4j.config;
@Configuration
public class XiaozhiAgentConfig {
@Bean
ChatMemoryProvider chatMemoryProviderXiaozhi() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.build();
}
}
ChatMemoryProvider是函数式接口,是一个典型的 工厂接口,每次对不同的 memoryId 调用 get() 会返回对应的独立 ChatMemory 实例,相同 memoryId 应返回同一实例确保同一会话的记忆连续性。
package dev.langchain4j.memory.chat;
import dev.langchain4j.memory.ChatMemory;
@FunctionalInterface
public interface ChatMemoryProvider {
ChatMemory get(Object var1);
}
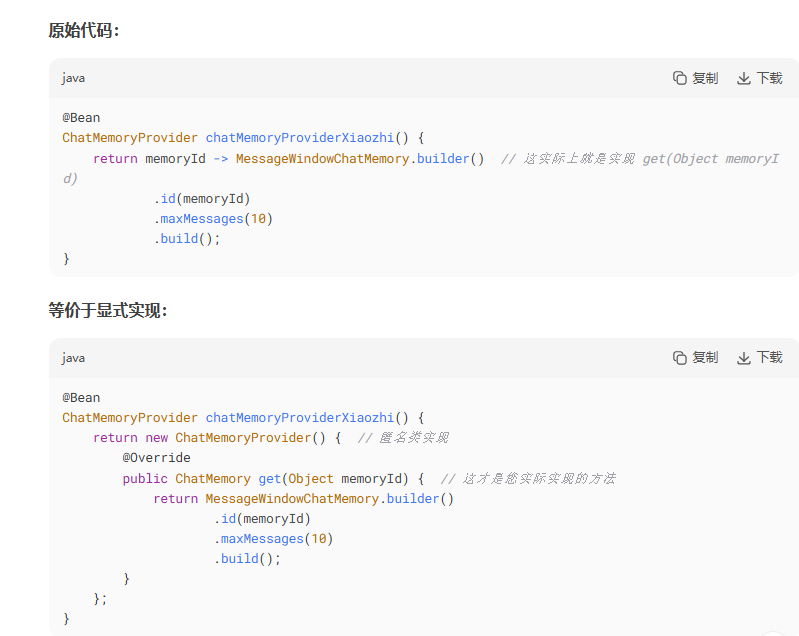
聊天记忆存储在哪里了呢?我们跟踪MessageWindowChatMemory源码:
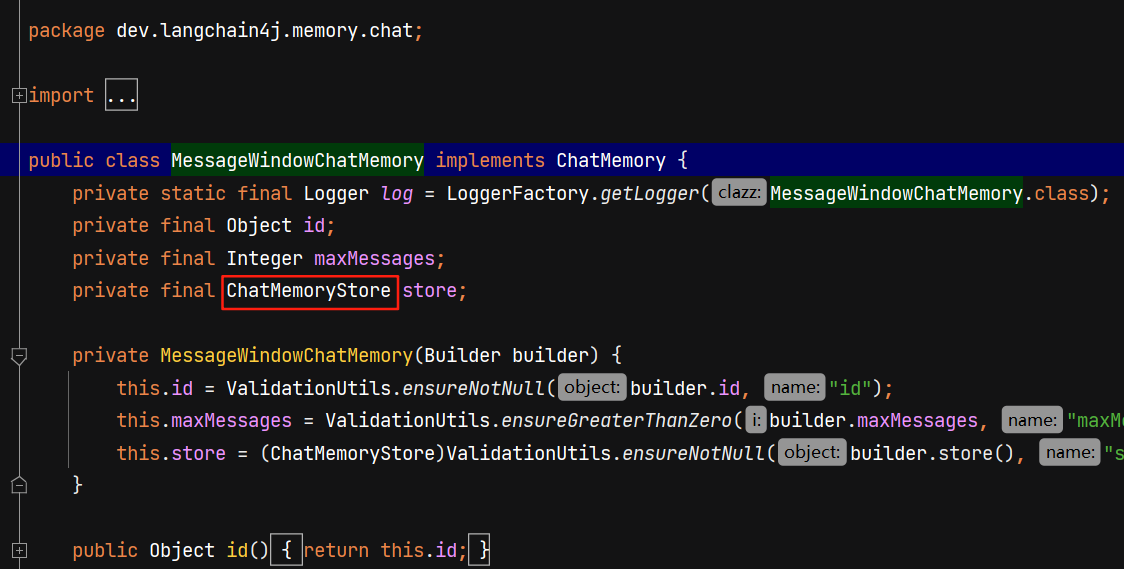
ChatMemoryStore接口有两个默认的实现类(进入源代码接口按ctrl+h)MongoChatMemoryStore显然是我自己自定义的一套实现类。默认的实现类分别是用hashmap和arraylist存储的聊天记忆,也就是说都是在内存层面存的聊天记忆。arraylist实现是聊天会话存list集合,memoryId单独用成员变量表示
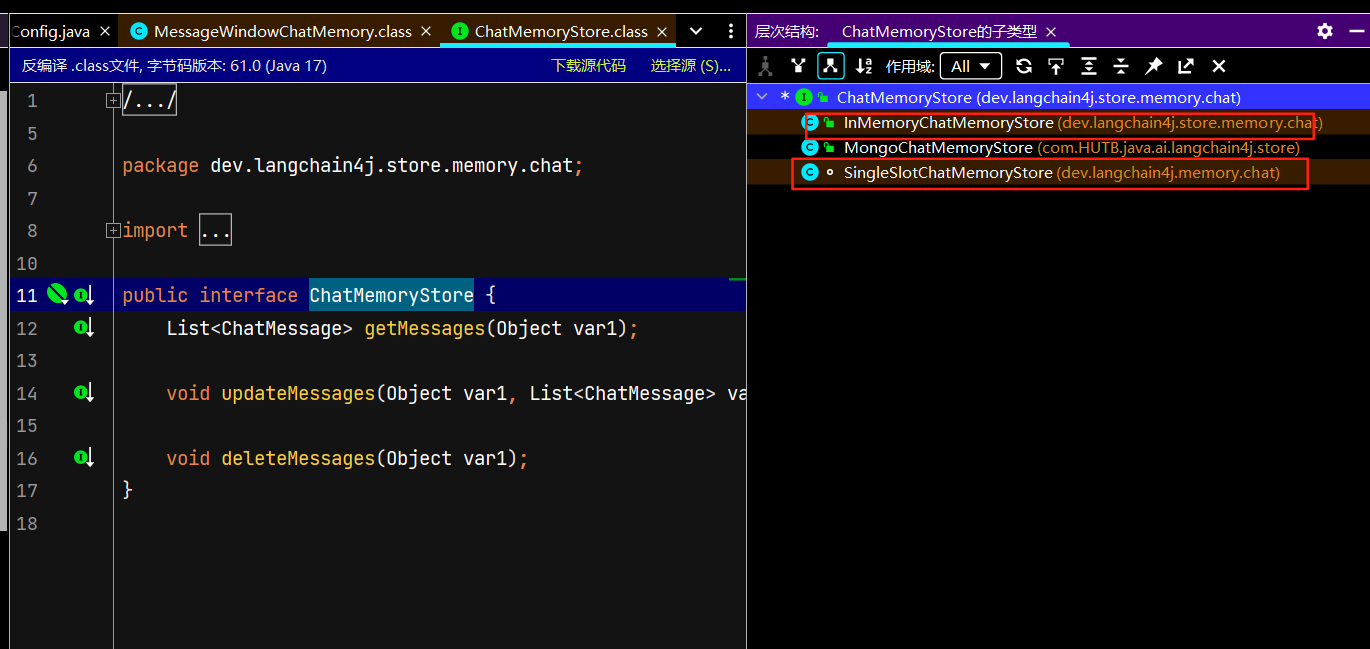
断点调试得到默认使用的哪个默认的实现类
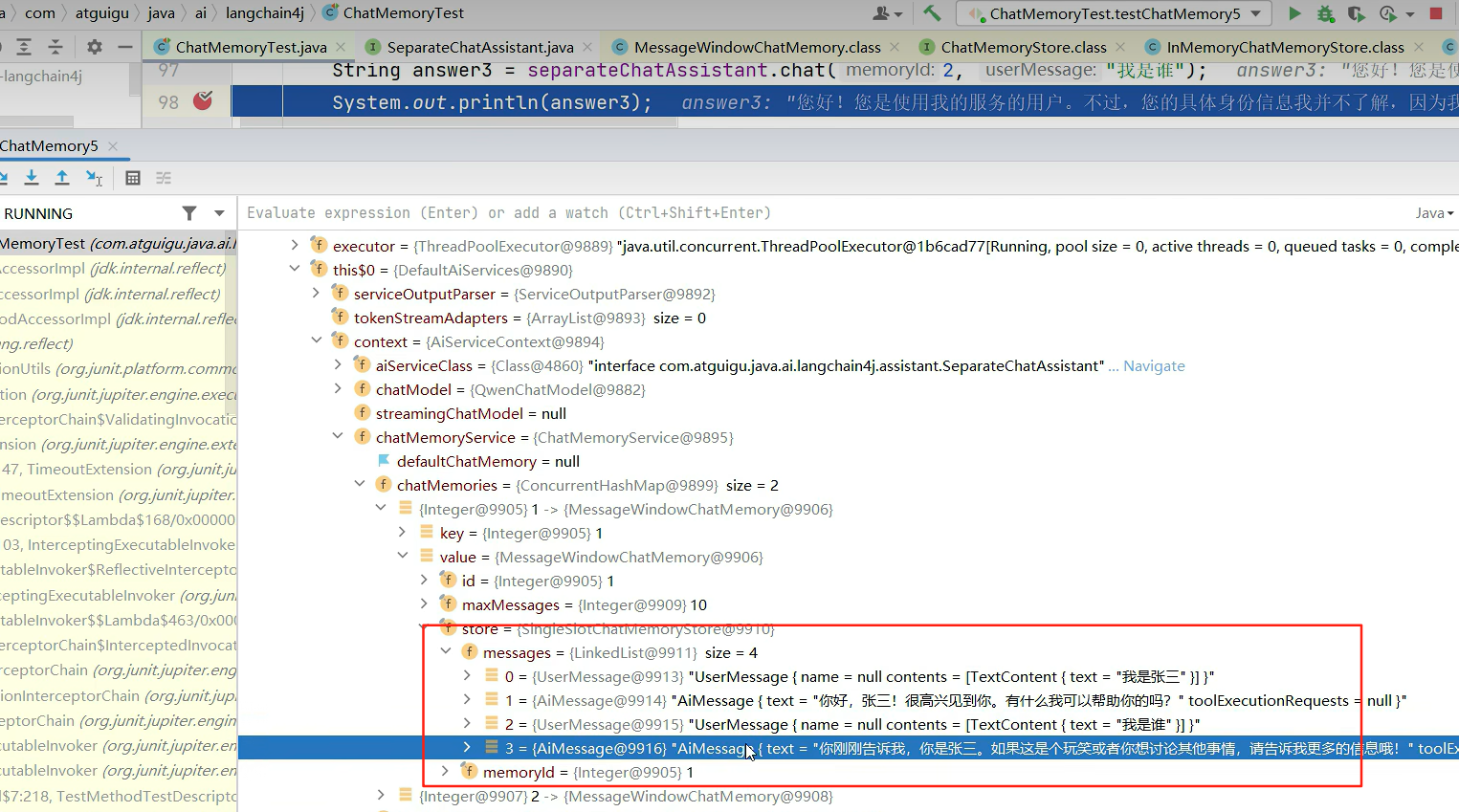
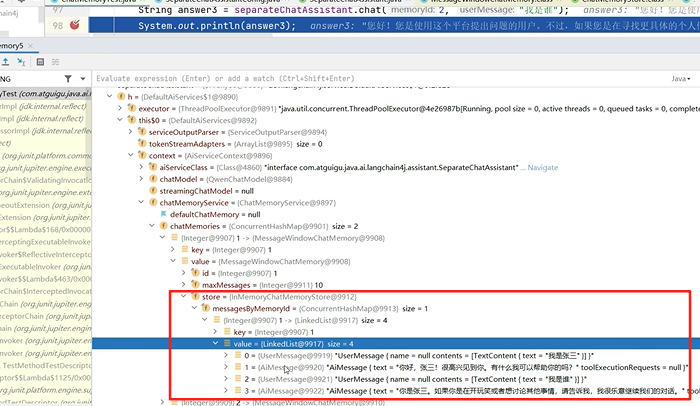
切换聊天记忆存储实现类,自定义聊天记忆管理
@Bean
public ChatMemoryProvider chatMemoryProvider(){
return memoryId -> MessageWindowChatMemory
.builder()
.id(memoryId)
.maxMessages(10)
//.chatMemoryStore(new InMemoryChatMemoryStore())
.chatMemoryStore(mongoChatMemoryStore)
.build();
}1 聊天记忆存储默认的内存存储和自定义redis内存存储的区别
有一个问题就是默认的两种聊天记忆的实现是基于内存的,但是官网建议存到redis或者Mongdb等存储介质中,我想问,redis也是基于内存的啊,为什么推荐把聊天基于存储到redis内存而不是我们默认的内存?首先要明确一点,默认的两种存储是存在JVM内存的,源码new ArrayList(),new ConcurrentHashMap(),大容量对话历史会挤占应用内存!而redis存储是存在redis进程中的,不会挤压应用的内存!作为非常成熟的分布式缓存中间件,redis天然支持水平拓展,大大提升服务稳定性。同时redis还有完善的持久化机制!
但是综合考虑还是选择mongodb作为本项目的存储介质,因为当聊天记忆中通常包含多样化的信息,如文本消息、图片、语音等多媒体数据,消息格式可能会频繁变化时,MongoDB 能更好地适应这种灵活性!它是一种文档型数据库,数据以二进制json格式文档进行存储,具有高度的灵活性和可扩展性。(mysql要预定义表结构且性能差!redis要预定义数据结构类型)
权威依据
-
MongoDB 官方推荐:
MongoDB 用例文档 明确将「聊天应用」列为核心场景,强调其对动态消息格式的支持。 -
Redis 官方限制:
Redis 数据模型文档 指出,复杂嵌套数据需要客户端序列化(如 JSON 字符串),破坏原生查询能力。
2 mongodb整合springboot做增删改查
https://blog.csdn.net/qq_47959003/article/details/130078975SpringBoot MongoTemplate的基本使用方法-CSDN博客https://blog.csdn.net/qq_47959003/article/details/130078975优质博客
定义实体类,封装聊天数据,映射mongodb中的集合(mysql里的表),应用程序在运行起来后会在配置的数据库里面自动创建chat_messages集合。deepseek的描述:ChatMessages(实体类)是一个 MongoDB 持久化实体类,用于将 List<ChatMessage> 序列化成 JSON 并存储到数据库。通常包含 memoryId(会话ID)和 content(消息列表的JSON字符串)字段。
package com.HUTB.java.ai.langchain4j.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.bson.types.ObjectId;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document("chat_messages")
public class ChatMessages {
//唯一标识,映射到 MongoDB 文档的 _id 字段
@Id
private ObjectId messageId;//mongdb自动给你生成数据id类型
private String memoryId;
private String content; //存储当前聊天记录列表的json字符串,包含对话双方的消息
}package com.HUTB.java.ai.langchain4j;
import com.HUTB.java.ai.langchain4j.bean.ChatMessages;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.data.mongodb.core.query.Update;
@SpringBootTest
public class MongoCrudTest {
@Autowired
private MongoTemplate mongoTemplate;
/**
* 插入文档
*/
/* @Test
public void testInsert() {
mongoTemplate.insert(new ChatMessages(1L, "聊天记录"));
}*/
/**
* 插入文档
*/
@Test
public void testInsert2() {
ChatMessages chatMessages = new ChatMessages();
chatMessages.setContent("聊天记录列表");
mongoTemplate.insert(chatMessages);
}
/**
* 根据id查询文档
*/
@Test
public void testFindById() {
ChatMessages chatMessages = mongoTemplate.findById("6801ead733ba9c4a0d9b6c7b", ChatMessages.class);
System.out.println(chatMessages);
}
/**
* 修改文档
*/
@Test
public void testUpdate() {
Criteria criteria = Criteria.where("_id").is("6801ead733ba9c4a0d9b6c7b");
Query query = new Query(criteria);
Update update = new Update();
update.set("content", "新的聊天记录列表");
//修改或新增
mongoTemplate.upsert(query, update, ChatMessages.class);
}
/**
* 新增或修改文档
*/
@Test
public void testUpdate2() {
Criteria criteria = Criteria.where("_id").is("100");
Query query = new Query(criteria);
Update update = new Update();
update.set("content", "新的聊天记录列表");
//修改或新增
mongoTemplate.upsert(query, update, ChatMessages.class);
}
/**
* 删除文档
*/
@Test
public void testDelete() {
Criteria criteria = Criteria.where("_id").is("100");
Query query = new Query(criteria);
mongoTemplate.remove(query, ChatMessages.class);
}
}
| 对象 | 官方类名 | 推荐变量名 | 作用 | 类比 SQL |
|---|---|---|---|---|
| 查询条件 | Criteria |
criteria |
定义字段匹配规则 | WHERE |
| 查询请求 | Query |
query |
封装查询条件和参数 | SELECT ... WHERE ... |
| 更新操作 | Update |
update |
定义如何修改字段 | SET |
为什么这样设计?
Spring Data MongoDB 通过分离这三个概念,实现了:
-
职责单一:
Criteria只关心条件,Update只关心修改。 -
链式调用:支持流畅的 API 风格(如
Criteria.where(...).and(...))。 -
复用性:同一个
Criteria可以用于find、update、delete等操作。
Criteria.where("age").gt(18) // 1. where age > 18
.and("name").regex("张.*") // 2. and name 以"张"开头
.orOperator( // 3. or status = "active"
Criteria.where("status").is("active")
);类似 SQL 的 WHERE age > 18 AND name LIKE '张%' OR status = 'active'
Update update = new Update()
.set("name", "Bob") // SET name = "Bob"
.inc("age", 1) // age = age + 1
.unset("oldField"); // 删除 oldField 字段 老问题:怎么就依赖注入了mongoTemplate?我没有使用@Configuration+@Bean啊,也没有使用@mapper之类的注解声明beana啊,老问题再次复习:直击 Spring Boot 自动配置的核心机制!MongoTemplate 能直接注入而无需手动声明 @Bean,完全归功于 Spring Boot Starter 的自动配置(Auto-Configuration)。
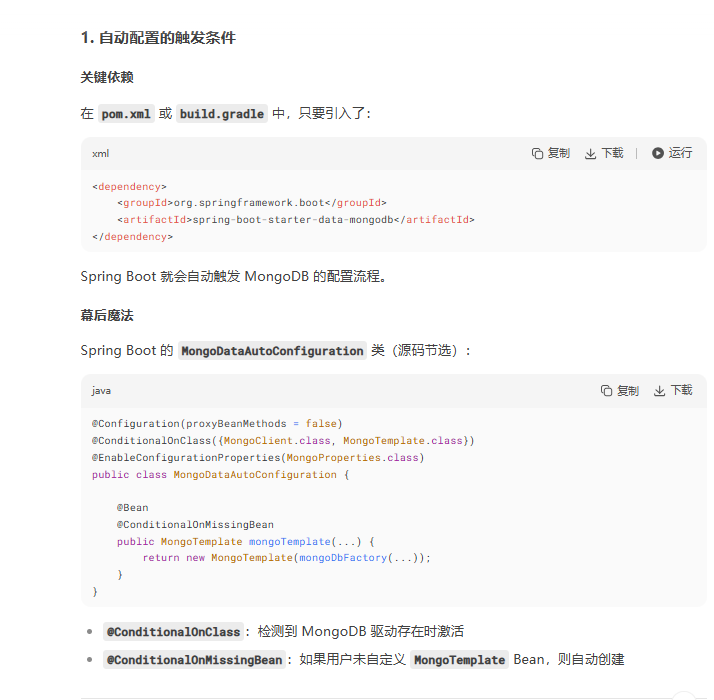
注意要在 application.yml配置文件中进行配置,spingboot用来 读取配置。
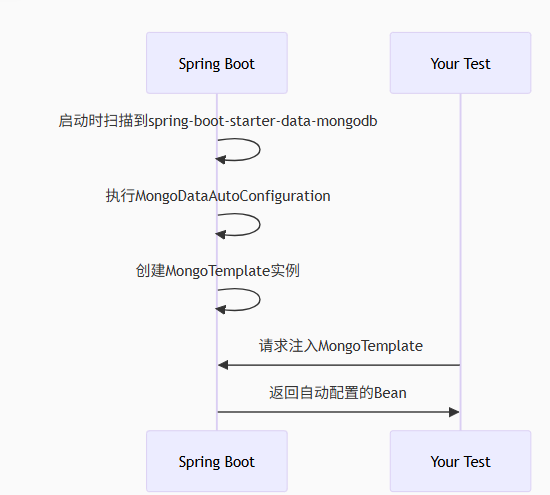
还有个问题没解决:如何在idea MongoTemplate源代码里快速找到相关方法?ctrl+n搜索不到啊。(29-9:10)
3.用Mongodb实现聊天记忆持久化
mongoTemplate帮助我们把聊天记忆存储起来,要想在MongoChatMemoryStore中依赖注入该对象,要把MongoChatMemoryStore实现类的对象也要初始化在spring的上下文当中(在该实现类的上面加上@Component注解)
先用单元测试使用新知识比如springboot整合mongdb做增删改查,然后在项目代码里可以直接拿单元测试的代码进行改造。比如自定义聊天记忆存储的实现类,实现类中的几个方法改造如下(为什么要实现这几个方法?这三个方法覆盖了聊天记忆的 完整生命周期,符合 CRUD 核心操作!!)
| 方法 | 对应操作 | 场景示例 |
|---|---|---|
getMessages |
Read | 加载对话 |
updateMessages |
Create/Update | 新增或更新对话记录 |
deleteMessages |
Delete | 用户手动清除或系统自动清理过期会话 |
package com.HUTB.java.ai.langchain4j.store;
import com.HUTB.java.ai.langchain4j.bean.ChatMessages;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.ChatMessageDeserializer;
import dev.langchain4j.data.message.ChatMessageSerializer;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.data.mongodb.core.query.Update;
import org.springframework.stereotype.Component;
import java.util.LinkedList;
import java.util.List;
@Component// 要成功注入mongoTemplate,MongoChatMemoryStore 也要交个容器管理
public class MongoChatMemoryStore implements ChatMemoryStore {
@Autowired
private MongoTemplate mongoTemplate;
//ChatMessages是我们自定义的类,是存储聊天消息列表的持久化实体,ChatMessage是定义单条聊天消息的通用接口(如用户消息、AI 回复、系统消息等),是 LangChain4J 的核心消息模型,用于构建对话上下文
@Override
public List<ChatMessage> getMessages(Object memoryId) {
Criteria criteria = Criteria.where("memoryId").is(memoryId);//查询条件对象
Query query = new Query(criteria);//查询对象
ChatMessages chatMessages = mongoTemplate.findOne(query, ChatMessages.class);
if (chatMessages == null) {
return new LinkedList<>();
}
String contentJson = chatMessages.getContent();
return ChatMessageDeserializer.messagesFromJson(contentJson);
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> list) {
Criteria criteria = Criteria.where("memoryId").is(memoryId);
Query query = new Query(criteria);
Update update = new Update();
update.set("content", ChatMessageSerializer.messagesToJson(list));
//修改或新增
mongoTemplate.upsert(query, update, ChatMessages.class);
}
@Override
public void deleteMessages(Object memoryId) {
Criteria criteria = Criteria.where("memoryId").is(memoryId);
Query query = new Query(criteria);
mongoTemplate.remove(query, ChatMessages.class);
}
}
修改XiaozhiAgentConfig,让其在实现聊天记忆隔离的基础上支持我们自定义的持久化聊天记忆
package com.HUTB.java.ai.langchain4j.config;
import com.HUTB.java.ai.langchain4j.store.MongoChatMemoryStore;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class XiaozhiAgentConfig {
@Autowired
private MongoChatMemoryStore mongoChatMemoryStore;
//ChatMemoryProvider作为函数式接口,与工厂模式天然契合,通过 Lambda 实现按需创建 ChatMemory。
@Bean
public ChatMemoryProvider chatMemoryProviderXiaozhi(){
//工厂方法:接收 memoryId,返回 ChatMemory 实例
return memoryId ->
MessageWindowChatMemory.builder()//构建者模式
.id(memoryId)
.maxMessages(20)
.chatMemoryStore(mongoChatMemoryStore)
.build();
}
}每当 LangChain4J 框架请求某个 memoryId 对应的聊天记忆时,该工厂会 新建(或返回已有)一个 MessageWindowChatMemory 实例。该实例通过构建者模式创建,被配置为:绑定到当前 memoryId,最多保留20条最新消息(通过滑动窗口机制),使用 mongoChatMemoryStore 持久化消息。工厂模式 决定 “创建什么”(由 memoryId 驱动),建造者模式 决定 “如何创建”(通过 builder() 逐步配置)
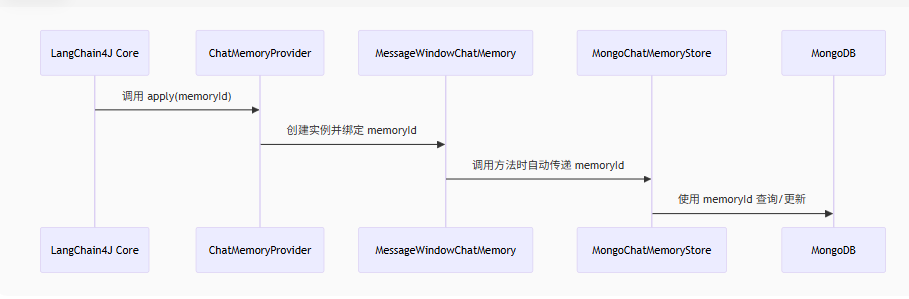
构建MessageWindowChatMemory聊天记忆对象时用到了mongoChatMemoryStore啊,二者没有从属关系?mongoChatMemoryStore 是被注入的依赖项,而非 MessageWindowChatMemory 的属性子对象,依赖注入(协作)而非从属。MessageWindowChatMemory 只依赖 ChatMemoryStore 接口,不关心具体实现是 MongoDB、Redis 还是内存存储。下图是memoryId的传递过程。
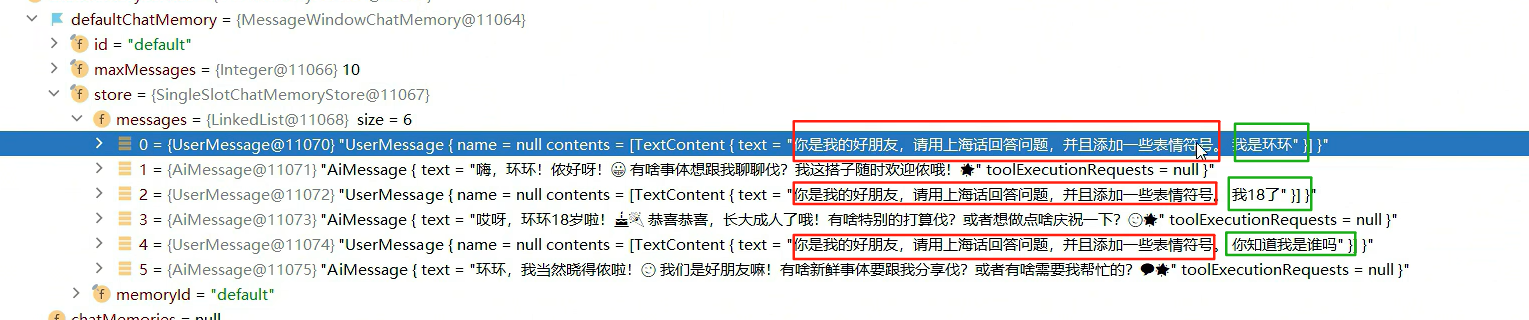
数据库中聊天记忆的存储型式,后两条是有memoryId的。真实系统中,memoryId组成可以是jwt认证的token(隔离用户)+会话id(隔离同一用户的不同聊天列表)!不同的用户建立不同的集合(相当于Mysql中的表),mongdb的文档相当于Mysql里的行记录!每一行存储一个用户的会话内容(会话id)
[
{
"_id": {"$oid": "689752264c5b5a3b0ad9dc8c"},
"_class": "com.HUTB.java.ai.langchain4j.bean.ChatMessages",
"content": "聊天记录列表"
},
{
"_id": {"$oid": "6897f1067564fb160310ae05"},
"_class": "com.HUTB.java.ai.langchain4j.bean.ChatMessages",
"content": "聊天记录列表001"
},
{
"_id": {"$oid": "6897fa56a81640ec51711fb3"},
"content": "[{\"text\":\"你是我的好朋友,请用上海话回答问题,回答问题的时候适当添加表情符号。\\r\\n今天是 2025-08-10。\",\"type\":\"SYSTEM\"},{\"contents\":[{\"text\":\"我是张三\",\"type\":\"TEXT\"}],\"type\":\"USER\"},{\"text\":\"嗨,张三!侬好呀!有啥可以帮到侬伐?\uD83D\uDE09\",\"type\":\"AI\"},{\"contents\":[{\"text\":\"我是谁\",\"type\":\"TEXT\"}],\"type\":\"USER\"},{\"text\":\"侬是张三呀!记性勿好伐?哈哈\uD83D\uDE04\",\"type\":\"AI\"}]",
"memoryId": 1
},
{
"_id": {"$oid": "6897fa58a81640ec51711fb4"},
"content": "[{\"text\":\"你是我的好朋友,请用上海话回答问题,回答问题的时候适当添加表情符号。\\r\\n今天是 2025-08-10。\",\"type\":\"SYSTEM\"},{\"contents\":[{\"text\":\"我是谁\",\"type\":\"TEXT\"}],\"type\":\"USER\"},{\"text\":\"侬是吾的好朋友呀!\uD83D\uDE00 我们经常一起聊天,分享各种事情的。如果想知道更多关于自己的信息,可以再多给点提示我哦!\",\"type\":\"AI\"}]",
"memoryId": 2
}
]提示词、函数调用
提示词很简单,分为用户提示词(@UserMessage)和系统提示词(@SystemMessage)。这些注解都是加在XiaozhiAgen接口的chat方法上,提示词太多可以把它放到一个文件里,然后用注解加载进来。langchain4j会把@SystemMessage 的内容将在后台转换为 SystemMessage 对象,并与 UserMessage 一起发送给大模型,当然也能把@UserMessag的内容和用户输入一起封装为UserMessage对象发给大模型。
这里的用户提示词和用户输入还是有区别的,用户提示词设置了一段话,后续的每次聊天对话(绿框)都会加上该段(红框)。
切换系统提示词,该系统提示词之前的聊天记录作废,哪怕在一个聊天记忆里(失忆)。 大模型对时间不敏感(截至它的训练日期),它怎么知道患者的预约挂号时间呢?只要在系统提示词里加上“今天是 {{current_date}}”即可。current_date一般是系统内置变量(current_date的定义在PromptTemplate中)。
当然你也可以在chat方法里加入时间参数,@V("time") 自动填入提示模板中的对应占位符{{time}}。
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,
chatModel = "openAiChatModel",//找到对应的bean进行绑定
chatMemory = "chatMemory",//找到对应的bean进行绑定
chatMemoryProvider = "chatMemoryProvider"//找到对应的bean进行绑定
)
public interface SeparateChatAssistant {
// @SystemMessage("你是一个智能助手,请用湖南话回答问题。")
@SystemMessage(fromResource = "prompts/assistant.txt")
String chat0(@MemoryId int memoryId, @UserMessage String userMessage, @V("time")String time);
@SystemMessage(fromResource = "my-prompt-template.txt")//系统消息提示词
//@SystemMessage("你是我的好朋友,请用东北话回答问题。今天是{{current_date}}")//系统消息提示词
//@SystemMessage("你是我的好朋友,请用粤语回答问题。")//系统消息提示词
String chat1(@MemoryId int memoryId, @UserMessage String userMessage);
@UserMessage("你是我的好朋友,请用粤语回答问题。{{message}}")
String chat2(@MemoryId int memoryId, @V("message") String userMessage);
@SystemMessage(fromResource = "my-prompt-template3.txt")
String chat3(
@MemoryId int memoryId,
@UserMessage String userMessage,
@V("username") String username,
@V("age") int age
);
}
封装前端发起请求的信息,这里的ChatForm和之前提到的ChatMessages不同,不要混淆
package com.HUTB.java.ai.langchain4j.bean;
import lombok.Data;
@Data
public class ChatForm {
private Long memoryId;//对话id
private String message;//用户问题
}| 类名 | ChatMessages |
ChatForm |
|---|---|---|
| 用途 | MongoDB 持久化实体(存储历史聊天记录) | 前端提交的表单数据载体(临时传输用) |
| 存储位置 | 直接映射 MongoDB 集合 chat_messages |
仅作为 HTTP 请求/响应的 DTO |
| 生命周期 | 长期存储在数据库 | 请求处理完毕后销毁 |
| 字段设计 | 包含数据库必要字段(如 @Id) |
仅包含业务所需字段 |
后端接收请求,调用智能体,完整的XiaozhiAgent接口代码在人工智能服务AiService里已经提及不会就忘了吧。
package com.HUTB.java.ai.langchain4j.controller;
import com.HUTB.java.ai.langchain4j.assistant.XiaozhiAgent;
import com.HUTB.java.ai.langchain4j.bean.ChatForm;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@Tag(name = "硅谷小智")
@RestController
@RequestMapping("/xiaozhi")
public class XiaozhiController {
@Autowired
private XiaozhiAgent xiaozhiAgent;
@Operation(summary = "对话")
@PostMapping(value = "/chat", produces = "text/stream;charset=utf-8")
public Flux<String> chat(@RequestBody ChatForm chatForm){
return xiaozhiAgent.chat(chatForm.getMemoryId(), chatForm.getMessage());
}
}
函数调用是方便大模型访问我们的业务系统,实现查询挂号记录、预约挂号记录、取消挂号记录的功能
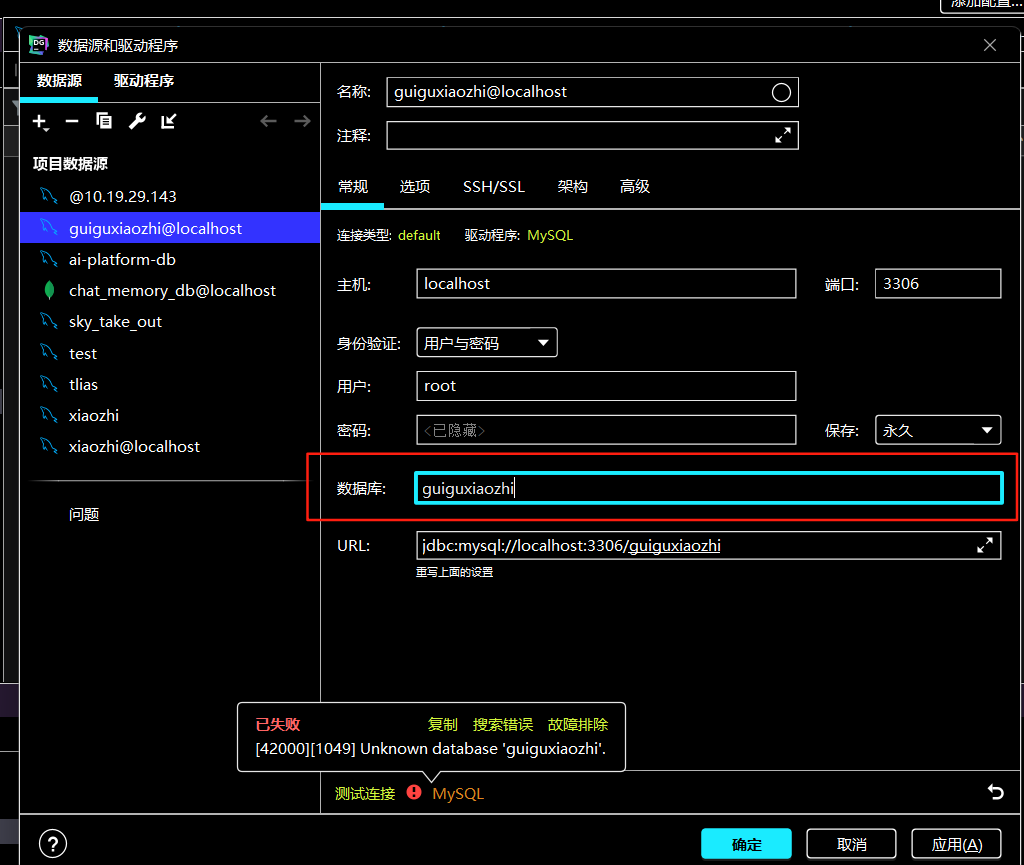
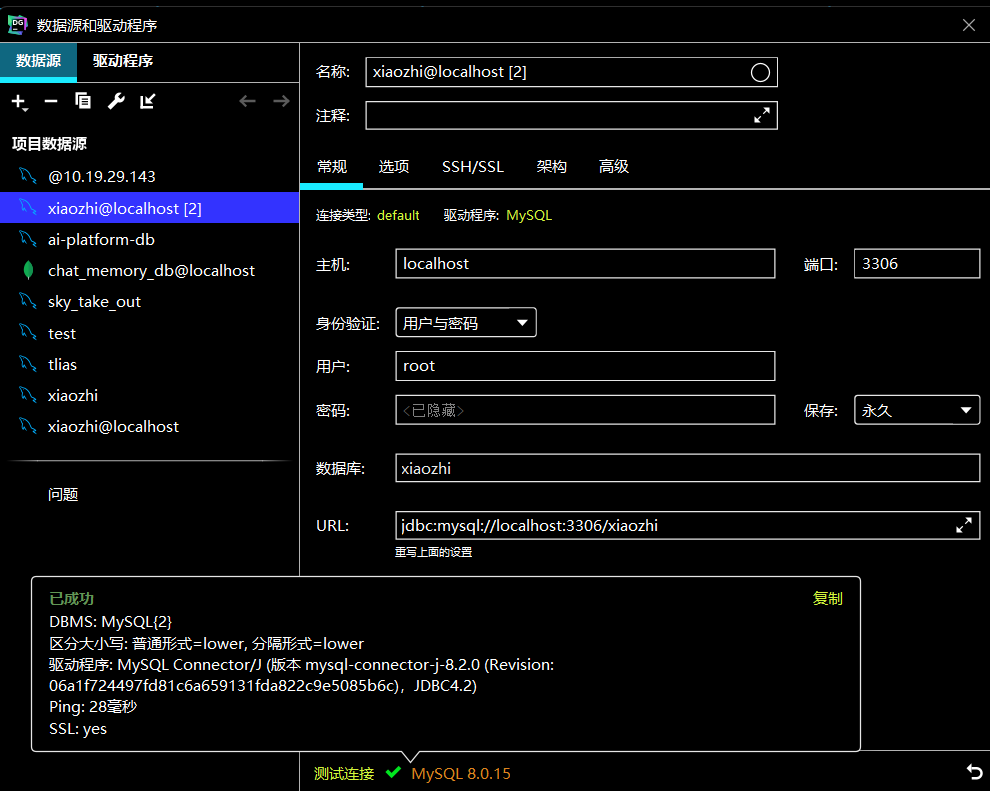
首先在准备数据库时就遇到了小插曲,打算新建xiaozhi数据库时测试连接显示以失败,点击进去后查询控制台不管什么指令都报1049这个错误,包括建库,show databases;这些基础语句。后来我发现是首次新建时,数据库名称不应该写在下图画红框的部分!我把xiaozhi写到上面的“名称”栏,顺利通过连接测试并建库成功!! 建库成功后你下次连接该数据库时可以在下图的画红框的部分写数据库名“xiaozhi”了,显示测试连接成功。我当时就怀疑第一次建库时数据库名称不能写在红框内,建库成功后才可以写,表示要连接这个数据库。测试新建guiguxiaozhi,果然报错如下:
xiaozhi数据库建好后连接该库:
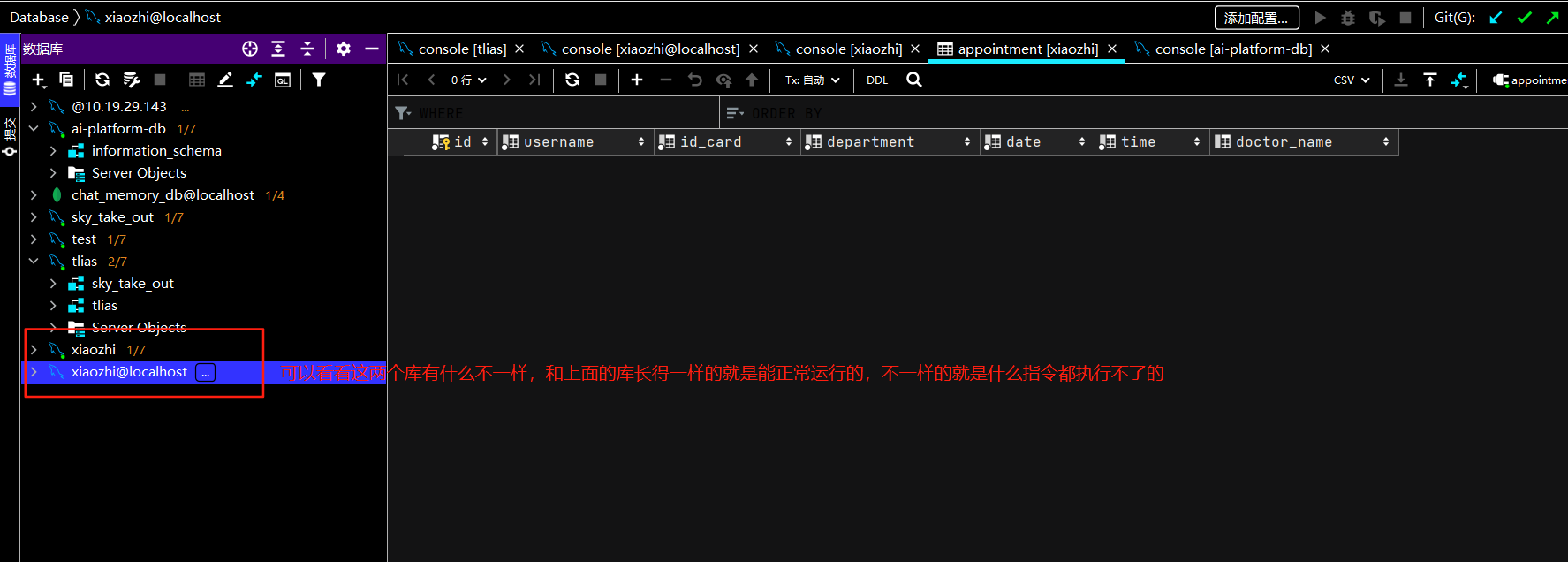
简化挂号业务,就只设计这一张预约信息表,如果患者要预约,查该表时发现他有a科室的预约信息,则他不能在预约该科室了。同理,查表发现同一时间如果a医生有了预约者,则该时间段往后十分钟该医生不能预约其他人(智能体会判断,推荐能预约的医生给患者)! 至于医生的排班信息,医院的科室信息等都集中维护到外部知识库中,通过rag检索增强生成来获取!
-- 创建数据库
CREATE DATABASE IF NOT EXISTS `xiaozhi` CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
-- 使用数据库
USE `xiaozhi`;
-- 创建预约表
CREATE TABLE `appointment` (
`id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`username` VARCHAR(50) NOT NULL COMMENT '预约人姓名',
`id_card` VARCHAR(18) NOT NULL COMMENT '身份证号',
`department` VARCHAR(50) NOT NULL COMMENT '预约科室',
`date` VARCHAR(10) NOT NULL COMMENT '预约日期(格式:yyyy-MM-dd)',
`time` VARCHAR(10) NOT NULL COMMENT '预约时间(格式:HH:mm)',
`doctor_name` VARCHAR(50) DEFAULT NULL COMMENT '医生姓名',
PRIMARY KEY (`id`)
) COMMENT='预约信息表';
我们用mybatis-plus操作mysql数据库,所以及时引入这两项依赖到pom文件,因为配置了springboot依赖清单所以mysql不用写版本号,及时配置文件中添加mysql配置。
定义实体类:
定义这个实体类的本质原因是:在Java世界里强行复刻数据库表的结构,让程序能用面向对象的方式操作数据库,避免手写SQL到精神分裂。
举个粗暴的比喻:
数据库表就像Excel表格(有列名和行数据)
实体类就是把Excel的列名变成Java类的属性
MyBatis-Plus就是自动把Java对象和表格行数据互相转换的翻译官
package com.HUTB.java.ai.langchain4j.entity;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Appointment {
@TableId(type = IdType.AUTO)//告诉MyBatis-Plus:"让数据库自己生成ID",当业务层代码调用insert() 时会故意不插入id
private Long id;
private String username;
private String idCard;
private String department;
private String date;
private String time;
private String doctorName;
}接着创建 AppointmentMapper接口和AppointmentService业务层接口(除了继承的方法,还有一个自定义的拓展方法),分别继承mybatis-plus的BaseMapper<Appointment>接口和IService<Appointment>接口(有框架定义好的基础代码骨架),其中还要定义业务层接口的实现类AppointmentServiceImpl(继承ServiceImpl<AppointmentMapper, Appointment> 类),代码逻辑写在该实现类。(有大佬说easycode插件一键生成?以后验证下)
package com.HUTB.java.ai.langchain4j.service;
public interface AppointmentService extends IService<Appointment> {
Appointment getOne(Appointment appointment);
}实现类实现与解释
package com.HUTB.java.ai.langchain4j.service.impl;
// Spring的服务层注解,标识这是一个Spring管理的服务类,会被自动扫描并注册为Bean
@Service
/**
* 预约服务实现类
*
* 继承MyBatis-Plus提供的ServiceImpl基类,获得基础的CRUD操作能力
* 实现自定义的AppointmentService接口,提供业务相关的方法
*/
public class AppointmentServiceImpl extends ServiceImpl<AppointmentMapper, Appointment>
implements AppointmentService {
/**
* 检查指定预约是否已存在
*
* 通过比对用户名、身份证号、科室、日期和时间五个字段的组合,
* 判断系统中是否已存在完全相同的预约记录
*
* @param appointment 包含查询条件的预约对象
* @return 如果存在相同预约,返回完整的预约实体对象;否则返回null
*/
@Override
public Appointment getOne(Appointment appointment) {
// 创建Lambda查询条件构造器
// LambdaQueryWrapper是MyBatis-Plus提供的类型安全的条件构造器
// 使用Lambda表达式可以避免字段名的硬编码,编译时就能检查字段名是否正确
LambdaQueryWrapper<Appointment> queryWrapper = new LambdaQueryWrapper<>();
// 设置查询条件:用户名完全匹配
// eq方法表示等于(=)条件
// Appointment::getUsername是方法引用,相当于实体类的username字段
queryWrapper.eq(Appointment::getUsername, appointment.getUsername());
// 设置查询条件:身份证号完全匹配
queryWrapper.eq(Appointment::getIdCard, appointment.getIdCard());
// 设置查询条件:科室完全匹配
queryWrapper.eq(Appointment::getDepartment, appointment.getDepartment());
// 设置查询条件:日期完全匹配
queryWrapper.eq(Appointment::getDate, appointment.getDate());
// 设置查询条件:时间完全匹配
queryWrapper.eq(Appointment::getTime, appointment.getTime());
// 执行查询,获取满足条件的单条记录
// baseMapper是ServiceImpl提供的MyBatis Mapper代理对象
// selectOne方法查询满足条件的单条记录,如果有多条会抛出异常
Appointment appointmentDB = baseMapper.selectOne(queryWrapper);
// 返回查询结果
return appointmentDB;
}
}
继承
ServiceImpl<AppointmentMapper, Appointment>:获得MyBatis-Plus提供的通用CRUD操作实现
AppointmentService:自定义业务接口,定义特定业务方法mybatis-plus不要显示的写sql的了,我不是定义了public interface AppointmentMapper extends BaseMapper<Appointment> { }接口吗?白定义的可以不用定义?还是说要定义,只是sql是底层拼接封装的?
MyBatis-Plus 是一个强大的 MyBatis 增强工具,它的设计理念就是 "少写 SQL",甚至 "不写 SQL" 也能完成大部分 CRUD 操作。如果只涉及单表查询,用 MyBatis-Plus 提供的通用方法(如你的
getOne方法中用的selectOne),确实可以不写任何 SQL。但如果需要复杂查询(多表关联、聚合函数、子查询),你仍然可以在AppointmentMapper中通过注解或 XML 编写 SQL! 必须通过 Mapper 接口定义数据库操作(即使单表查询不要显示的写 SQL,也要有接口声明),MyBatis 要通过动态代理自动生成该接口的实现类!
函数调用tools:hutb校医院是一个基层医院,只有基础的科室,每个科室的医生只有那么一两个,不涉及到医生的排盘信息,所以可以直接挂号不用确认是否有号源,但是我们还是要模拟下大医院的流程,维护医生的排班信息(生成模拟的排班信息),我们可以采用Mysql数据库维护,也可以采用外部知识库维护,这里我们采用后者。
package com.HUTB.java.ai.langchain4j.tools;
import com.HUTB.java.ai.langchain4j.entity.Appointment;
import com.HUTB.java.ai.langchain4j.service.AppointmentService;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component//appointmentService注入成功的前提是AppointmentTools也要交给容器管理
public class AppointmentTools {
@Autowired
private AppointmentService appointmentService;
@Tool(name="预约挂号", value = "根据参数,先执行工具方法queryDepartment查询是否可预约,并直接给用户回答是否可预约,并让用户确认所有预约信息,用户确认后再进行预约。如果用户没有提供具体的医生姓名,请从向量存储中找到一位医生。")
public String bookAppointment(Appointment appointment){
//查找数据库中是否包含对应的预约记录
Appointment appointmentDB = appointmentService.getOne(appointment);
if(appointmentDB == null){
appointment.setId(null);//防止大模型幻觉设置了id
if(appointmentService.save(appointment)){//mysql表中多了一条数据
return "预约成功,并返回预约详情";
}else{
return "预约失败";
}
}
return "您在相同的科室和时间已有预约";
}
@Tool(name="取消预约挂号", value = "根据参数,查询预约是否存在,如果存在则删除预约记录并返回取消预约成功,否则返回取消预约失败")
public String cancelAppointment(Appointment appointment){
Appointment appointmentDB = appointmentService.getOne(appointment);
if(appointmentDB != null){
//删除预约记录
if(appointmentService.removeById(appointmentDB.getId())){//mysql表里少了一条数据
return "取消预约成功";
}else{
return "取消预约失败";
}
}
//取消失败
return "您没有预约记录,请核对预约科室和时间";
}
@Tool(name = "查询是否有号源", value="根据科室名称,日期,时间和医生查询是否有号源,并返回给用户")
//public boolean queryDepartment(Appointment appointment) {
//TODO 维护医生的排班信息,这里可以选择在mysql表里维护,也可以选择在后面的知识库中维护,这里我们选择后者:
//一般没有指定医生名字,根据意图识别要预约的科室,从向量存储中找到相关科室当天有值班的医生(含介绍),根据患者提供的时间(appointment对象属性里有)找出数据库表appointment中时间有冲突的相关科室医生,然后把他们从向量数据库中查询的医生列表中剔除返回给前端!都剔除了就告诉前端没有号了,返回false
//如果指定了医生名字,按没有指定的逻辑来,如果最后的结果包含了他指定的医生,就优先推荐!
return true; //先简化处理,默认总有号源
}
@Tool注解有两个可选字段:
- name(工具名称):工具的名称。如果未提供该字段,方法名会作为工具的名称。
- value(工具描述):工具的描述信息。
save、removeById是内置方法,getOne是接口自定义业务方法
RAG检索增强生成
理解几个核心概念,外部知识库,rag,向量数据库。
外部知识库是原始文档,不是模型训练数据,一般是需求文档,mysql存的业务数据,是专有数据、实时信息、长尾知识(非热门”但总量庞大的信息)
rag是检索增强生成技术,其核心价值在于流程编排(何时检索既何时调用向量数据库查找最相似的知识、如何拼接上下文并输入大模型生成最终回答——增强生成、如何优化提示词等),举个恰当的比方:根据顾客需求(用户问题),快速从仓库(向量数据库)取食材(相关知识),整理好后交给厨师,并提示烹饪方式(优化提示词)。
RAG本身不包含向量相似度计算能力,也没有存储向量的能力,它依赖专门的向量数据库(如Milvus、Pinecone)用于存储、检索向量数据(高维数值数组),通过计算向量间的相似度(如余弦相似度)实现高效搜索。
RAG常用方法
全文(关键词)搜索。这种方法通过将问题和提示词中的关键词与知识库文档数据库进行匹配来搜索文档。根据这些关键词在每个文档中的出现频率和相关性对搜索结果进行排序。向量搜索,也被称为 “语义搜索”。文本通过嵌入模型被转换为数字向量。然后,它根据查询向量与文档向量之间的余弦相似度或其他相似性 / 距离度量来查找和排序文档,从而捕捉更深层次的语义含义。混合搜索。结合多种搜索方法(例如,全文搜索 + 向量搜索)通常可以提高搜索的效果。
| 特性 | 向量数据库 | 传统全文检索(如Elasticsearch) |
|---|---|---|
| 索引类型 | 向量相似度 | 关键词匹配 |
| 语义理解 | 支持(相近含义可匹配) | 仅字面匹配 |
| 适用场景 | 非结构化数据(文本、图像等) | 结构化文本 |
| 组件 | 实际功能 | 常见误解纠正 |
|---|---|---|
| 外部知识库 | 存储原始资料(PDF/数据库等) | 不是RAG的一部分,而是数据来源 |
| 向量数据库 | 快速检索与问题相关的资料(通过向量相似度) | 不生成答案,只返回文本片段 |
| 大模型(如GPT) | 真正生成答案(基于检索到的片段+用户问题) | RAG不替代大模型,而是扩展其输入 |
| RAG框架 | 流程编排者:调用检索 → 拼接上下文 → 调用大模型 → 返回结果 | 不是生成器,而是调度员 |
springai和LangChain4j 都是实现rag应用的开发框架!spring AI 对 Spring 框架的版本有明确要求,主要依赖 Spring Boot 3.x 和 Spring 6.x 的新特性。LangChain4j更通用, 不强制依赖 Spring 生态,因此可以无缝集成到老版本的 Spring 项目中。pyython中对标的是LangChain框架,注意LangChain这种是大模型应用开发框架,和pytorch这种深度学习框架是不一样的,前者主要是便捷的利用大模型能力构建智能体应用,不能用来训练模型(大神手搓除外)!后者是专业的模型训练框架!
RAG(检索增强生成)和模型微调(Fine-tuning)是两条不同的技术路线,分别解决大模型应用的两类问题。它们可以单独使用,也可以互补结合。
| 技术 | 核心目标 | 适用场景 |
|---|---|---|
| RAG | 动态扩展模型的知识边界,通过检索外部信息生成更准确的回答。 | 需要实时、专有或未训练数据的场景(如最新新闻、企业内部文档)。 |
| 模型微调 | 改变模型的行为或风格,使其更适配特定任务或领域。 | 需要模型学习特定模式(如医疗术语、客服话术)。 |
选择 RAG :
-
需要频繁更新知识(如客服系统对接最新产品文档)。
-
缺乏训练资源或标注数据。
-
要求答案可引用来源(如法律、医疗场景)。
选择模型微调:
-
任务需要模型改变行为模式(如让GPT用方言回答)。
-
领域知识高度结构化(如金融报告生成)。
-
需处理复杂逻辑(如多步骤推理)。
两者可互补,形成更强解决方案:
-
微调模型:使其擅长领域基础任务(如医疗术语理解)。
-
RAG 补充:动态注入最新指南或患者个案数据。
总结
-
RAG 是“开卷考试”(动态查资料),微调是“专业培训”(改变模型本质)。
-
轻量化需求选 RAG,深度适配选微调,高要求场景可结合。
我们还有必要介绍向量的维度的问题,向量的每个维度代表数据的不同特性,维度越多对事务的描述越精确。例如,在一个交通工具数据集中,我们可以定义四个维度:“轮子数量”、“是否有发动机”、“是否可以在地上开动”和“最大乘客数”。然后我们可以将一些车辆表示为:
因此,我们的汽车Car向量将是 (4, yes, yes, 5),或者用数值表示为 (4, 1, 1, 5)(将 yes 设为 1,no 设为 0)。我们还可以使用“是否有翅膀”、“是否使用柴油”、“最高速度”、“平均重量”、“价格”等等更多的维度信息来描述汽车,维度越多,计算得出的相似度高!然后采用算法如余弦相似度来测量向量的相似度。 大多数相似度测量要么仅依赖于方向,要么同时考虑方向和大小。只考虑大小是没有意义的。
RAG 过程分为 2 个不同的阶段:索引和检索。
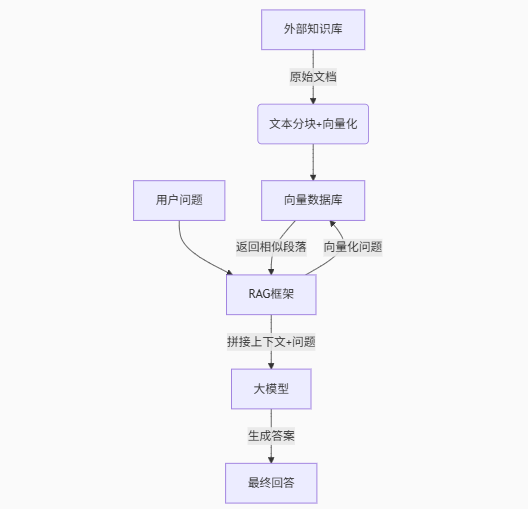
| 阶段 | 图中步骤 |
|---|---|
| 索引 | 原始文档/知识库 → 文本分块+向量化 → 向量数据库 |
| 检索与生成 | 用户问题 → 向量化问题 → 返回相似段落 → RAG框架(拼接上下文+问题) → 大模型 → 最终回答 |
文本分块要使用到文档加载器、文档解析器、文档分割器(大语言模型如GPT和嵌入模型如BERT对输入文本有长度限制),而向量化(Embedding)需要利用向量模型(如Word2Vec、BERT、阿里的text-embedding-v3模型)将文本分块转为稠密向量,直接用于检索,无需额外降维(高维稠密向量更适合相似度计算)。
-
输入:高维离散的符号(文本)→ 输出:相对低维的连续向量(但维度可能仍较高,如768维)。
-
例如:单词"apple" → [0.2, -0.5, 0.7, ...](一个稠密向量)。
索引阶段详细图
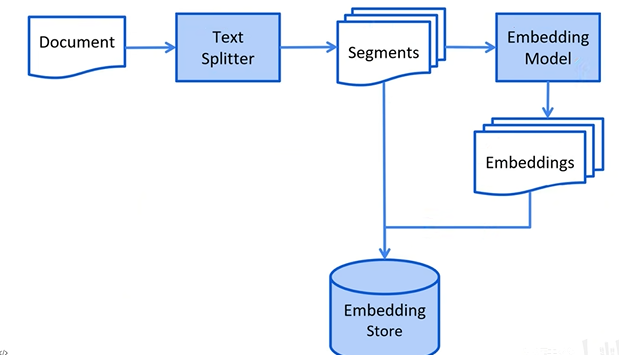
检索阶段详细图
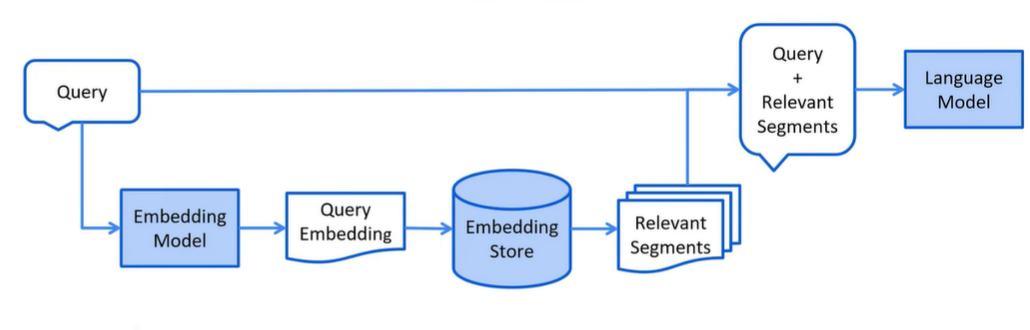
向量大模型检索向量数据库返回的数据包括向量本身和其对应的原始信息,rga将文本原始信息和用户输入组装后发给大模型。
默认情况,文档加载器里包含了一个文档解析器,当然你也可以传参new TextDocumentParser(),默认的TextDocumentParser解析器只能解析txt,md,html,对于pdf,微软系列文档无法解析(能加载但是解析不了,乱码)
- 来自 langchain4j-document-parser-apache-pdfbox 模块的 Apache PDFBox 文档解析器(ApachePdfBoxDocumentParser),它可以解析 PDF 文件。
- 来自 langchain4j-document-parser-apache-poi 模块的 Apache POI 文档解析器(ApachePoiDocumentParser),它能够解析微软办公软件的文件格式(例如 DOC、DOCX、PPT、PPTX、XLS、XLSX 等)。
- 来自 langchain4j-document-parser-apache-tika 模块的 Apache Tika 文档解析器(ApacheTikaDocumentParser),它可以自动检测并解析几乎所有现有的文件格式。
使用非默认的文档解析器要记得引入依赖!!!
@Test
public void testReadDocument() {
//使用FileSystemDocumentLoader读取指定目录下的知识库文档
//并使用默认的文档解析器TextDocumentParser对文档进行解析
/*Document document = FileSystemDocumentLoader.loadDocument("E:/knowledge/测试.txt");
System.out.println(document.text());*/
/* // 加载单个文档
Document document = FileSystemDocumentLoader.loadDocument("E:/knowledge/file.txt", new TextDocumentParser());
// 从一个目录中加载所有文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("E:/knowledge", new TextDocumentParser());*/
// 从一个目录中加载所有的.txt文档
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.pdf");
List<Document> documents = FileSystemDocumentLoader.loadDocuments("D:/课程资料/硅谷小智(医疗版)/资料/knowledge", pathMatcher, new TextDocumentParser());
for (Document document : documents) {
System.out.println("=================================");
System.out.println(document.metadata());
System.out.println(document.text());
}
/* // 从一个目录及其子目录中加载所有文档
List<Document> documents = FileSystemDocumentLoader.loadDocumentsRecursively("E:/knowledge", new TextDocumentParser());*/
}
常见文档分割器
LangChain4j 有一个 “文档分割器”(DocumentSplitter)接口,并且提供了几种开箱即用的实现方式:
按段落文档分割器(DocumentByParagraphSplitter),子文档分割器是行文档分割器按行文档分割器(DocumentByLineSplitter),子文档分割器是句子文档分割器。
按句子文档分割器(DocumentBySentenceSplitter),以此内推。。。。
按单词文档分割器(DocumentByWordSplitter)
按字符文档分割器(DocumentByCharacterSplitter)
按正则表达式文档分割器(DocumentByRegexSplitter)
递归分割:DocumentSplitters.recursive (...)
默认情况下每个文本片段最多不能超过300个token
嵌入(向量)存储
Embedding (Vector) Stores 常见的意思是 “嵌入(向量)存储” 。在机器学习和自然语言处理领域,Embedding 指的是将数据(如文本、图像等)转换为低维稠密向量表示的过程,这些向量能够保留数据的关键特征。而 Stores 表示存储,即用于存储这些嵌入向量的系统或工具。它们可以高效地存储和检索向量数据,支持向量相似性搜索,在文本检索、推荐系统、图像识别等任务中发挥着重要作用。
LangChain4j 内置基于内存的向量存储,此外还支持第三方的向量存储。目前redis、Elasticsearch、oracle已原生支持向量存储!mysql、neo4j也可以依赖插件实现向量存储!还有基于云服务的向量存储(pinecone)
先使用内嵌的内存向量存储:
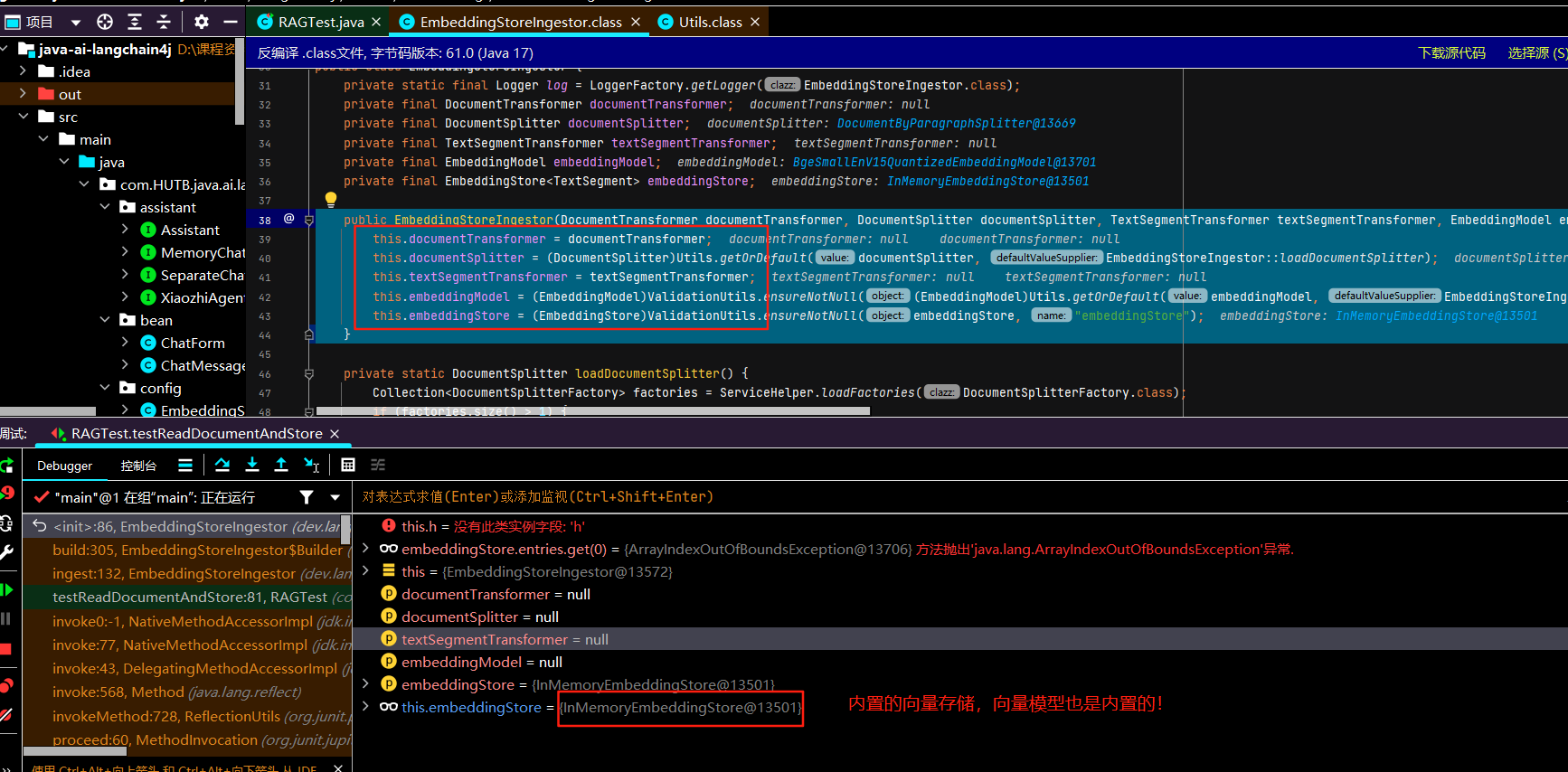
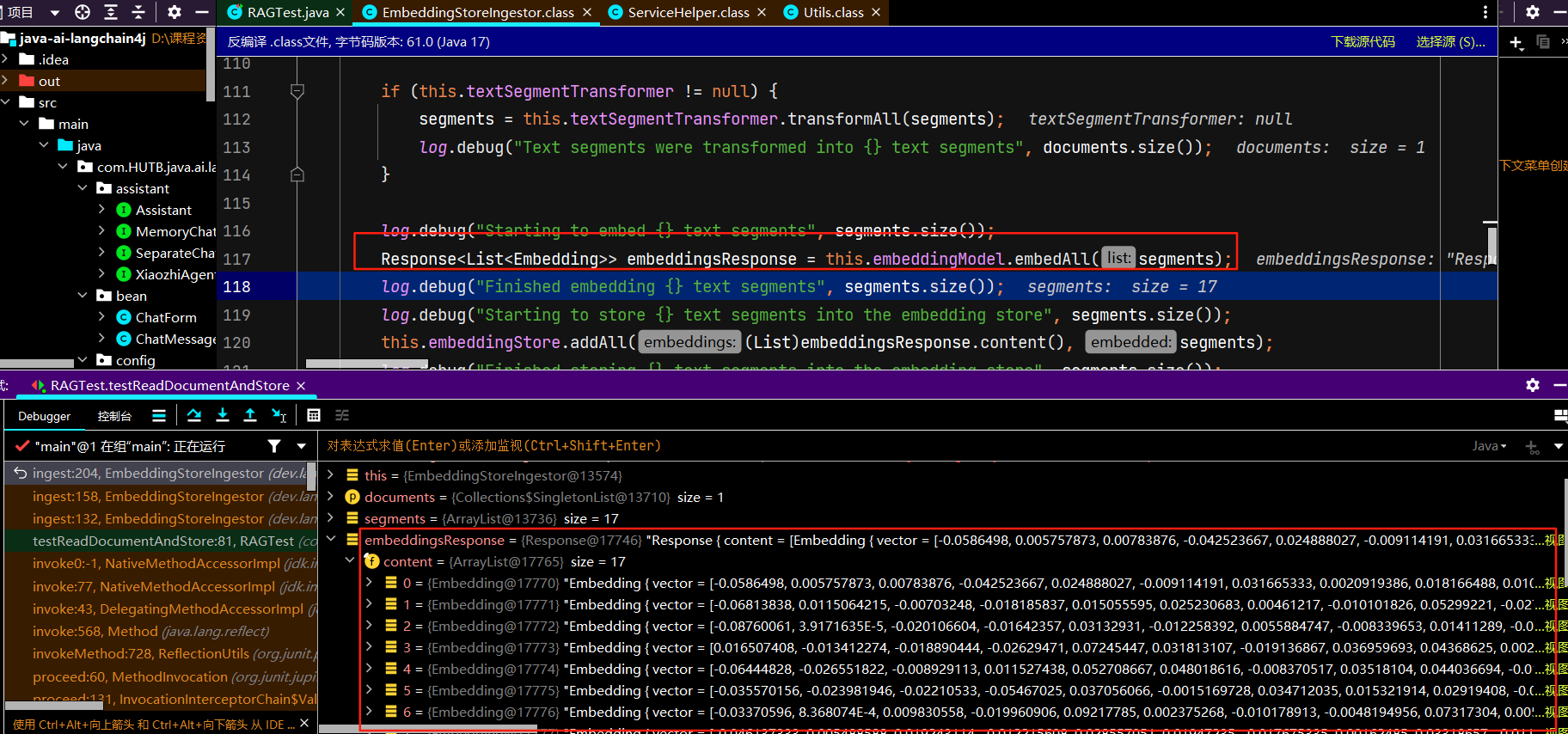
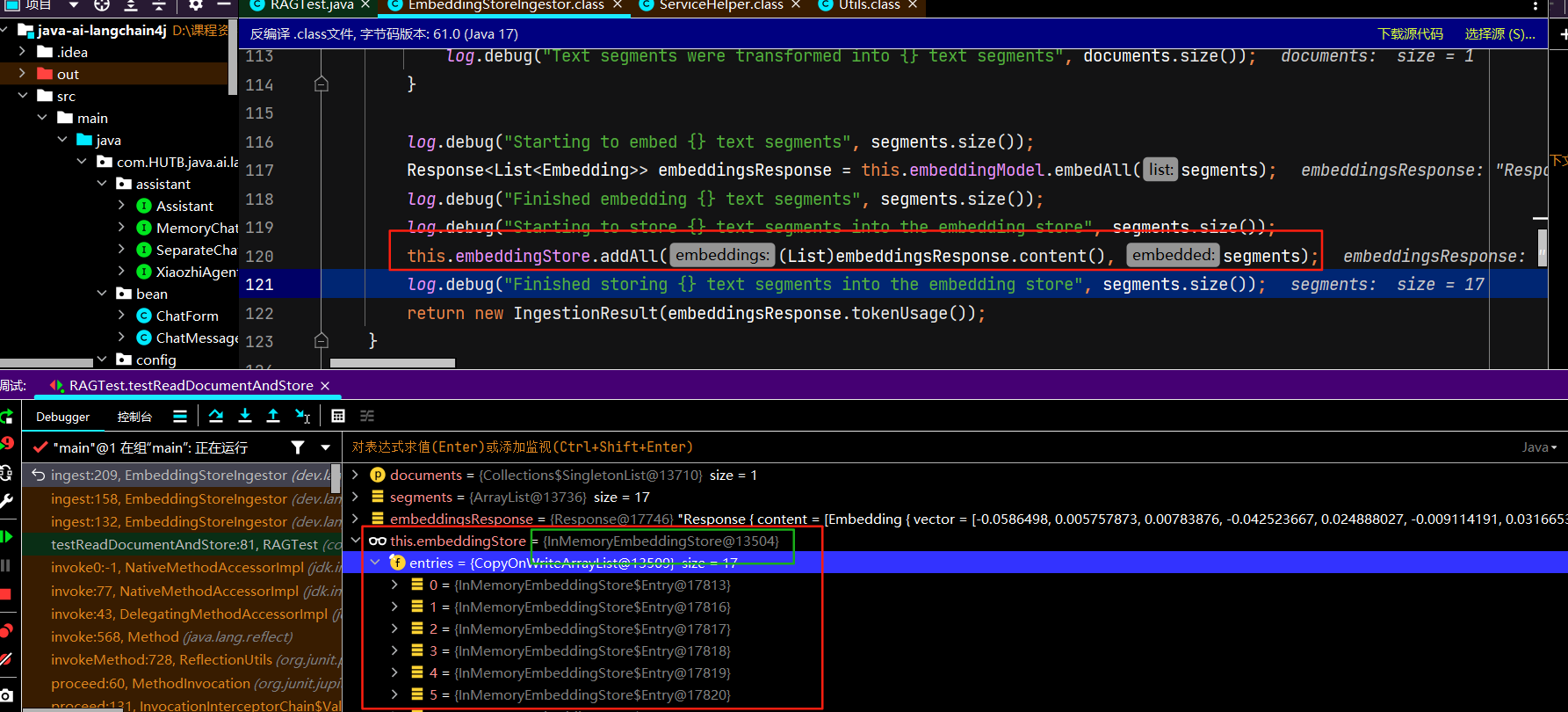
<!--简单的rag实现--> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-easy-rag</artifactId> </dependency>/** * 加载文档并存入向量数据库 */ @Test public void testReadDocumentAndStore() { //使用FileSystemDocumentLoader读取指定目录下的知识库文档 //并使用默认的文档解析器对文档进行解析(TextDocumentParser) Document document = FileSystemDocumentLoader.loadDocument("E:/knowledge/人工智能.md"); //为了简单起见,我们暂时使用基于内存的向量存储 InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>(); //ingest //1、分割文档:默认使用递归分割器,将文档分割为多个文本片段,每个片段包含不超过 300个token,并且有 30个token的重叠部分保证连贯性 //DocumentByParagraphSplitter(DocumentByLineSplitter(DocumentBySentenceSplitter(DocumentByWordSplitter))) //2、文本向量化:使用一个LangChain4j内置的轻量化向量模型对每个文本片段进行向量化 //3、将原始文本和向量存储到向量数据库中(InMemoryEmbeddingStore) EmbeddingStoreIngestor.ingest(document, embeddingStore); //查看向量数据库内容 System.out.println(embeddingStore); }debug跟踪ingest的源码:步入、步出、步过
初始化关键对象文档分割器、向量模型对象、向量存储对象等
正式分割:
正式文本向量化:
正式向量存储:
源码跟踪完毕
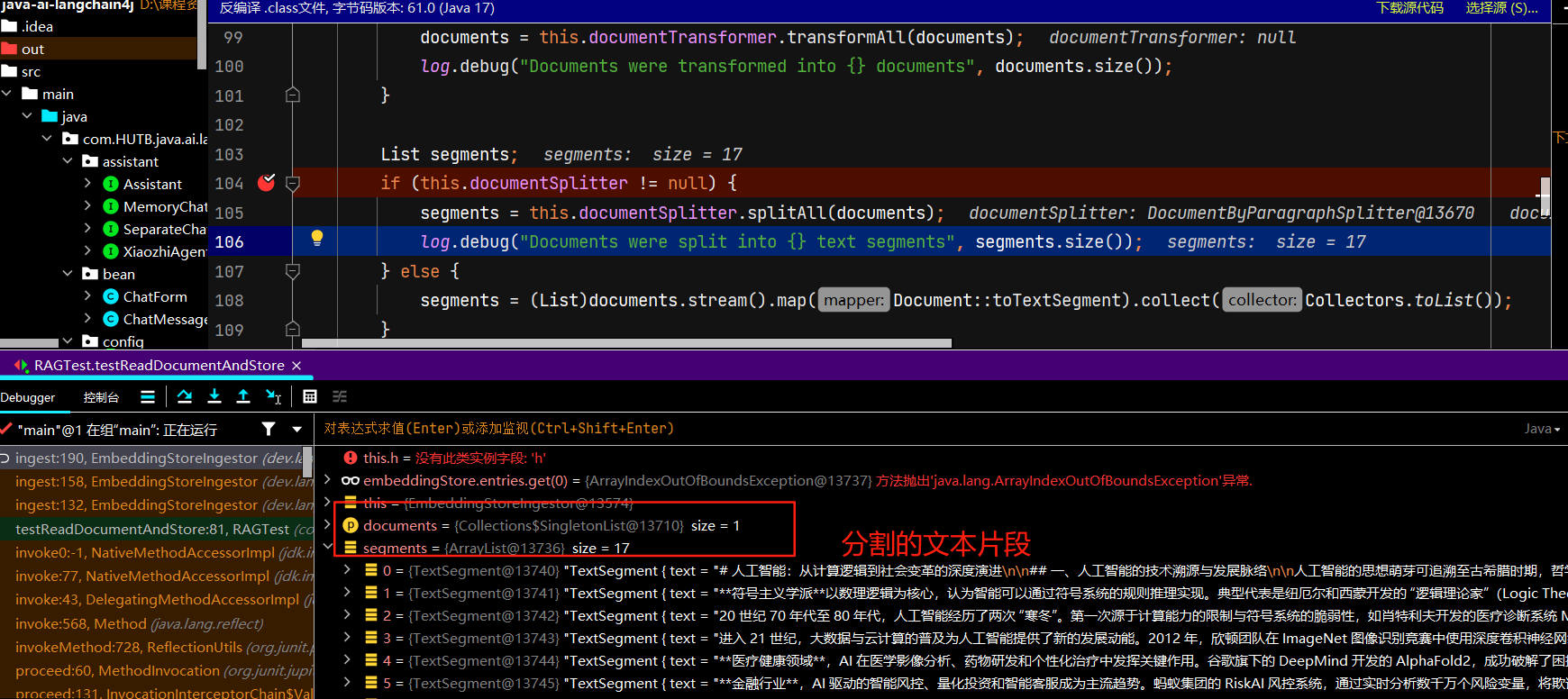
我们也可以自定义文档分割器:
/** * 文档分割 */ @Test public void testDocumentSplitter() { //使用FileSystemDocumentLoader读取指定目录下的知识库文档 //并使用默认的文档解析器对文档进行解析(TextDocumentParser) Document document = FileSystemDocumentLoader.loadDocument("E:/knowledge/人工智能.md"); //为了简单起见,我们暂时使用基于内存的向量存储 InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>(); //自定义文档分割器 //按段落分割文档:每个片段包含不超过 300个token,并且有 30个token的重叠部分保证连贯性 //注意:当段落长度总和小于设定的最大长度时,就不会有重叠的必要。 DocumentByParagraphSplitter documentSplitter = new DocumentByParagraphSplitter( 300, 30, //token分词器:按token计算 new HuggingFaceTokenizer()); //按字符计算 //DocumentByParagraphSplitter documentSplitter = new DocumentByParagraphSplitter(300, 30); EmbeddingStoreIngestor .builder() .embeddingStore(embeddingStore) .documentSplitter(documentSplitter) .build() .ingest(document); }上面提到的token 是模型用来表示自然语言文本的基本单位,也是我们的计费单元,
一般情况下模型中 token 和字数的换算比例大致如下:1 个英文字符 ≈ 0.3 个 token,1 个中文字符 ≈ 0.6 个 token,不同模型的分词不同,所以换算比例也存在差异,每一次实际处理 token 数量以模型返回为准
接下来要在项目中使用rag检索外部知识库了,首先我们要在XiaozhiAgentConfig类中配置ContentRetriever对象(基于内置向量存储向量检索对象)检索向量数据库,注意要在XiaozhiAgent接口的注解上的属性上注入该对象!相关的内自动导入,万岁的idea。
@Bean
ContentRetriever contentRetrieverXiaozhi() {
//使用FileSystemDocumentLoader读取指定目录下的知识库文档
//并使用默认的文档解析器对文档进行解析
Document document1 = FileSystemDocumentLoader.loadDocument("D:/课程资料/硅谷小智(医疗版)/资料/knowledge/knowledge/医院信息.md");
Document document2 = FileSystemDocumentLoader.loadDocument("D:/课程资料/硅谷小智(医疗版)/资料/knowledge/knowledge/科室信息.md");
Document document3 = FileSystemDocumentLoader.loadDocument("D:/课程资料/硅谷小智(医疗版)/资料/knowledge/knowledge/全院医生排班信息.md");
List<Document> documents = Arrays.asList(document1, document2, document3);
//使用内存向量存储
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
//使用默认的文档分割器
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
//从嵌入存储(EmbeddingStore)里检索和查询内容相关的信息
return EmbeddingStoreContentRetriever.from(embeddingStore);
}EmbeddingStore创建向量存储对象(后面自定义向量存储方式时会要配置该对象!),ContentRetriever是创建向量检索对象(根据自定义向量存储方式,会配置对应向量检索对象)
EmbeddingStoreContentRetriever是 内容检索器(Content Retriever)的实现类,封装了向量检索的逻辑,简化向量检索流程。from() 是一个 静态方法,要通过类名直接调用!EmbeddingStoreContentRetriever.from(embeddingStore) 创建的实例是 ContentRetriever 接口的具体实现对象,但它的实际类型是 EmbeddingStoreContentRetriever 类。
为什么 LangChain4j 大量使用静态工厂?
-
降低使用门槛:用户无需关心内部实现。
-
链式调用支持:适合 Builder 模式(如
.maxResults(3).minScore(0.8))。 -
未来兼容性:后续可以在静态方法中升级逻辑,不影响现有代码。
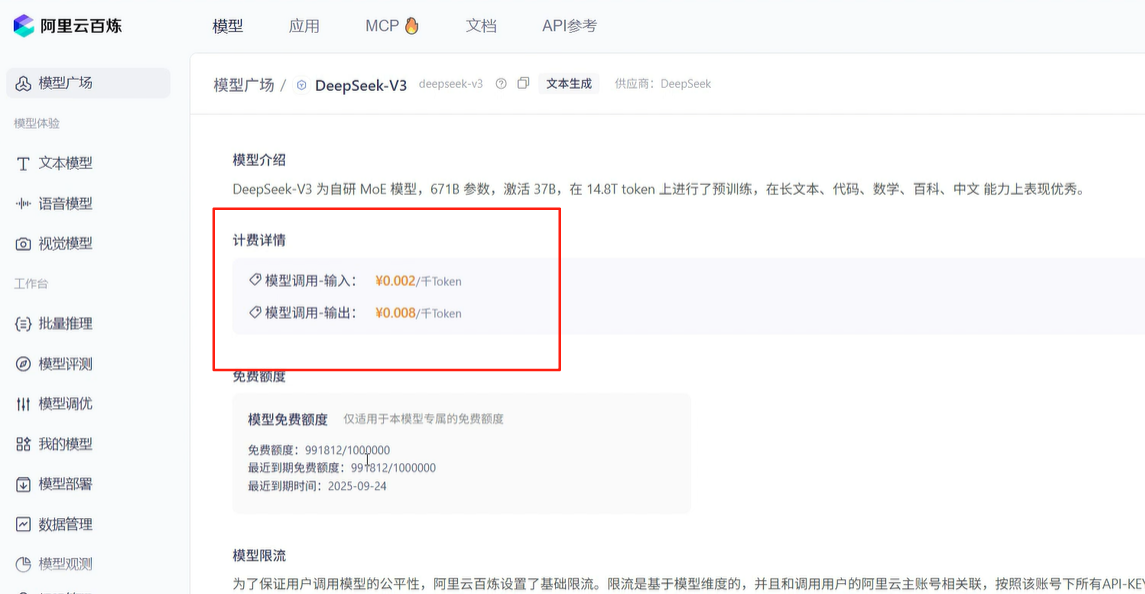
用我们默认的基于内存的向量存储,如果知识库比较大,占用服务器大量内存,对应用程序不友好,可以使用云服务的向量存储!存到云服务器中。当然用redis、Elasticsearch、oracle做向量存储也是很好的选择,我这里主要是想使用云服务!顺便把向量模型也换成更专业的阿里文本向量模型!
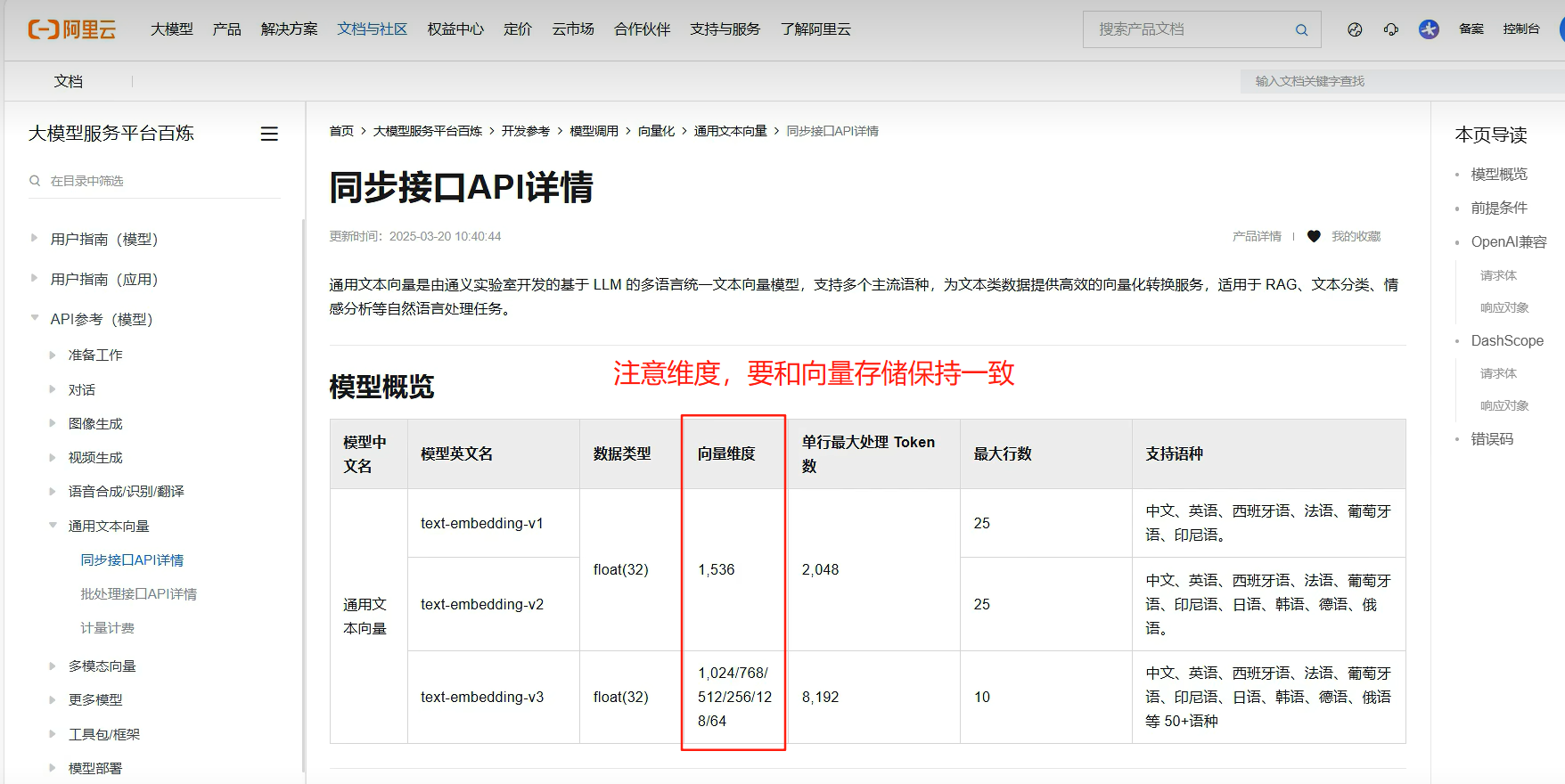
维度越多,对事务的描述越精准,信息检索的精度越高。
依赖别引错了:

依赖写在配置文件里不是pom文件?脑子呢?怎么还出现这样低级的问题,没有脑子那眼睛呢?写得很清楚,依赖在pom文件已配置,就是配的阿里百炼平台的依赖!配置是配置,依赖是依赖!!
-
职责分离:
-
pom.xml管代码依赖(哪些库需要被引入)。 -
application.properties管运行时配置(这些库如何工作)。
-
-
灵活性:
-
同一份代码可以通过不同的配置文件(如
dev.properties和prod.properties)切换不同的 API 密钥或模型,而无需修改pom.xml。
-
云服务的向量存储这里选择Pinecone,配置api_key!
在向量检索场景中,当我们把查询文本转换为向量后,会在嵌入存储(EmbeddingStore)里查找与之最相似的向量(这些向量对应着文档片段等内容)。为了衡量查询向量和存储向量之间的相似程度,会使用某种相似度计算方法(例如余弦相似度等)来得出一个数值,这个数值就是得分。得分越高,表明查询向量和存储向量越相似,对应的文档片段与查询文本的相关性也就越高。
得分的作用
- 筛选结果:通过设置
minScore阈值,能够过滤掉那些与查询文本相关性较低的结果。在代码里,minScore(0.8)意味着只有得分大于等于 0.8 的结果才会被返回,低于这个阈值的结果会被舍弃。这样可以确保返回的结果是与查询文本高度相关的,提升检索结果的质量。 - 控制召回率和准确率:调整
minScore的值可以在召回率和准确率之间进行权衡。如果把阈值设置得较低,那么更多的结果会被返回,召回率会提高,但可能会包含一些相关性不太强的结果,导致准确率下降;反之,如果把阈值设置得较高,返回的结果数量会减少,准确率会提高,但可能会遗漏一些相关的结果,使得召回率降低。在实际应用中,需要根据具体的业务需求来合理设置minScore的值。(重点,召回率和准确率的权衡)
假设我们有一个关于水果的文档集合,嵌入存储中存储了这些文档片段的向量。当我们使用 “苹果的营养价值” 作为查询文本时,向量检索会计算查询向量与存储向量的相似度得分。如果 minScore 设置为 0.8,那么只有那些与 “苹果的营养价值” 相关性非常高的文档片段才会被返回,而一些只简单提及苹果但没有详细讨论其营养价值的文档片段可能由于得分低于 0.8 而不会被返回(召回率低)
-
召回率的意义:
-
高召回率优先适用场景:学术文献检索、竞品分析、安全监控、法律证据检索、医疗诊断辅助理、舆情预警,在以上需要尽可能不遗漏信息的场景,高召回率更重要。
-
代价:高召回率可能需要人工二次筛选(准确率低),但能避免因遗漏关键文档导致的严重后果。
-
-
准确率的意义:
-
关键场景:在需要结果高度精准的场景(如客服问答、搜索引擎首条结果),高准确率更重要。
-
问答系统、推荐系统的首屏结果。
-
平衡策略:
-
使用 F1分数(召回率和准确率的调和平均)优化阈值。
-
分阶段检索:先高召回率粗筛,再通过排序或规则精筛。
-
-
把云向量存储集成到我们的项目,引入必要的依赖(之前的配置文件是完整的),配置向量存储对象,注意要注入向量模型,向量模型的输出维度,等于向量数据库存储的输入维度!
package com.HUTB.java.ai.langchain4j.config;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeEmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeServerlessIndexConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class EmbeddingStoreConfig {
@Autowired
private EmbeddingModel embeddingModel;
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
//创建向量存储
EmbeddingStore<TextSegment> embeddingStore = PineconeEmbeddingStore.builder()
.apiKey(System.getenv("PINECONE_API_KEY"))
.index("xiaozhi-index")//如果指定的索引不存在,将创建一个新的索引
.nameSpace("xiaozhi-namespace") //如果指定的名称空间不存在,将创建一个新的名称空间
.createIndex(PineconeServerlessIndexConfig.builder()
.cloud("AWS") //指定索引部署在 AWS 云服务上。
.region("us-east-1") //指定索引所在的 AWS 区域为 us-east-1。
.dimension(embeddingModel.dimension()) //指定索引的向量维度,该维度与 embeddedModel 生成的向量维度相同。
.build())
.build();
return embeddingStore;
}
}| 组件类型 | 配置风格 | 示例代码/配置 | 优化建议 |
|---|---|---|---|
| 向量存储 (Pinecone) |
手动 @Bean 创建 |
java @Bean public EmbeddingStore<TextSegment> embeddingStore() { ... } |
提取配置到 application.yml + @ConfigurationProperties |
| 聊天记忆存储 (MongoDB) |
手动 @Bean + 依赖注入 |
java @Bean public ChatMemoryProvider chatMemoryProvider(MongoChatMemoryStore store) { ... } |
封装为自定义 Starter |
| 大模型 (DashScope/OpenAI) |
纯配置文件自动配置 | properties langchain4j.community.dashscope.chat-model.api-key=xxx |
直接使用,无需修改 |
| 传统数据库 (MongoDB/MySQL) |
纯配置文件自动配置 | properties spring.data.mongodb.uri=xxx |
直接使用,无需修改 |
想自动配置,就自定义 Starter!别人官方都做好了,我们就可以直接自动配置,没做我们要么自定义starter要么就手动配置bean。
编写测试用例:
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private EmbeddingStore embeddingStore;
@Test
public void testPineconeEmbeded() {
//将文本转换成向量
TextSegment segment1 = TextSegment.from("我喜欢羽毛球");
Embedding embedding1 = embeddingModel.embed(segment1).content();
//存入向量数据库
embeddingStore.add(embedding1, segment1);
TextSegment segment2 = TextSegment.from("今天天气很好");
Embedding embedding2 = embeddingModel.embed(segment2).content();
embeddingStore.add(embedding2, segment2);
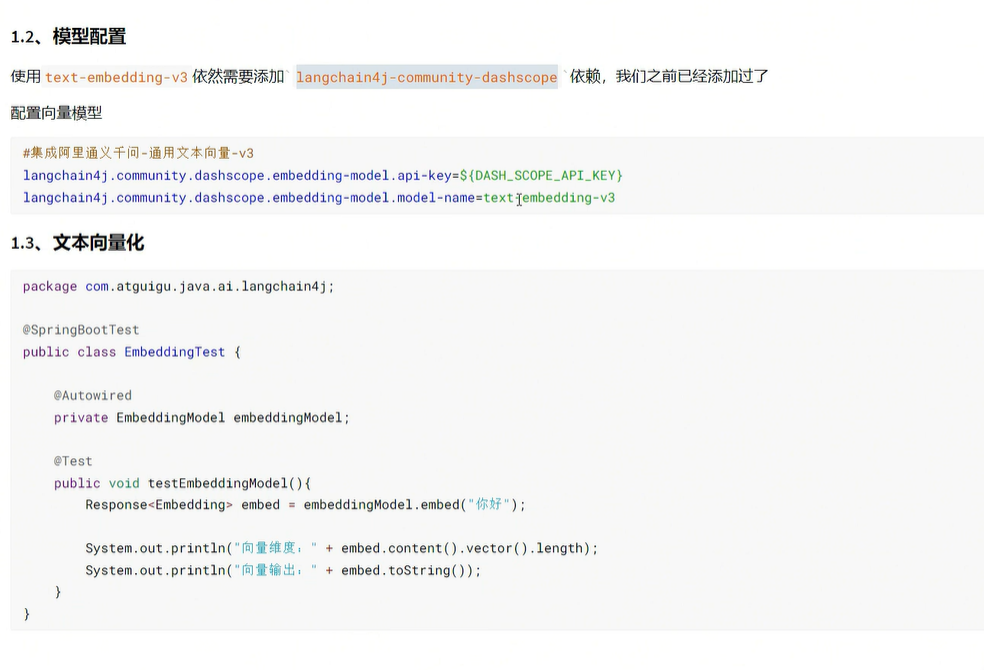
}测试成功,向量数据库中看到了存的数据:
然后编写相似度匹配的测试用例:
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private EmbeddingStore embeddingStore;
/**
* Pinecone-相似度匹配
*/
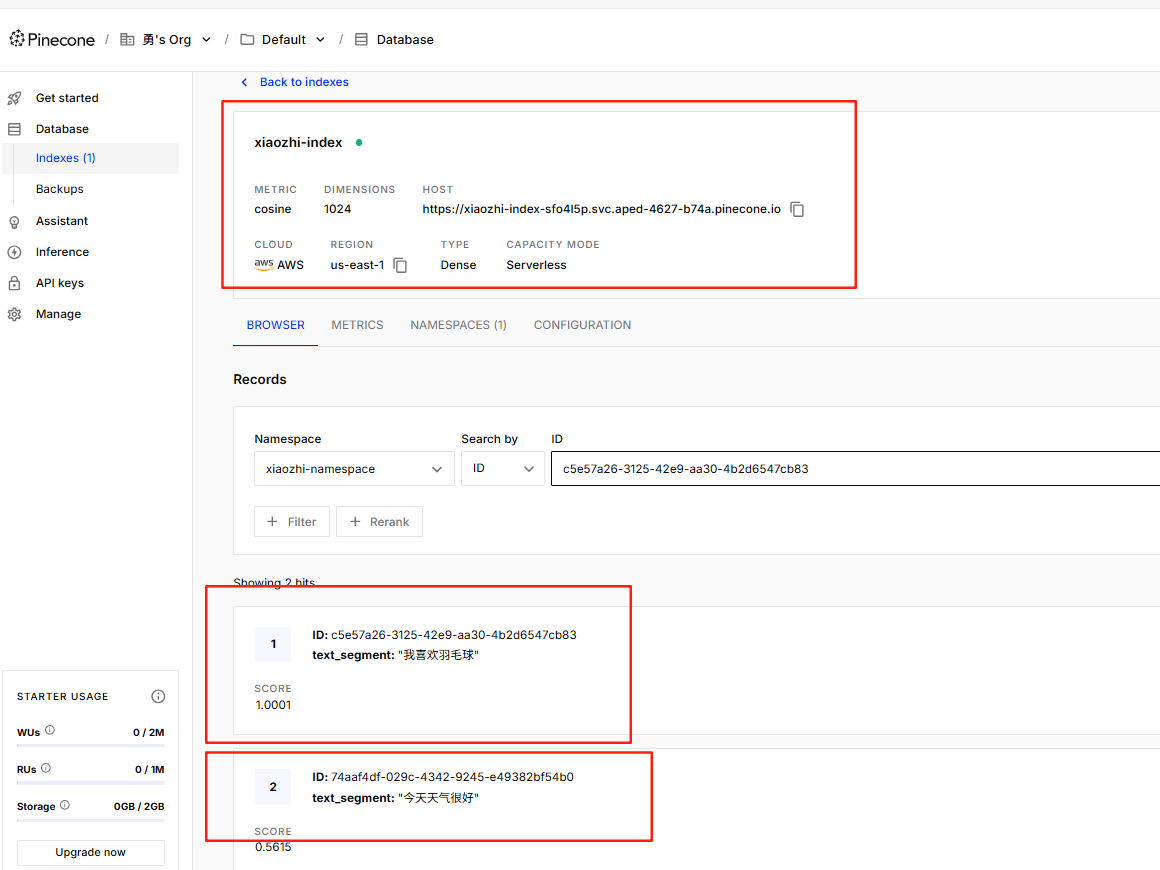
@Test
public void embeddingSearch() {
//提问,并将问题转成向量数据
Embedding queryEmbedding = embeddingModel.embed("你最喜欢的运动是什么?").content();
//创建搜索请求对象
EmbeddingSearchRequest searchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1) //匹配最相似的一条记录
//.minScore(0.8)
.build();
//根据搜索请求 searchRequest 在向量存储中进行相似度搜索
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(searchRequest);
//searchResult.matches():获取搜索结果中的匹配项列表。
//.get(0):从匹配项列表中获取第一个匹配项
EmbeddingMatch<TextSegment> embeddingMatch = searchResult.matches().get(0);
//获取匹配项的相似度得分
System.out.println(embeddingMatch.score()); // 0.8144288515898701
//返回文本结果
System.out.println(embeddingMatch.embedded().text());
}EmbeddingSearchRequest是工具类所以不用注入对象,直接调用它自己的静态方法!!
正式上传知识库文档:先在pinecone里删除测试用例插入的两条数据。首先是文本上传,创建UploadKnowledgeLibraryService和 UploadKnowledgeLibraryServiceImpl
public interface UploadKnowledgeLibraryService {
public void uploadKnowledgeLibrary(MultipartFile[] files);
}
@Service
public class UploadKnowledgeLibraryServiceImpl implements UploadKnowledgeLibraryService {
@Autowired
private EmbeddingStore<TextSegment> embeddingStore;
@Autowired
private EmbeddingModel embeddingModel;
@Override
public void uploadKnowledgeLibrary(MultipartFile[] files) {
List<Document> documents = new ArrayList<>();
for (MultipartFile file : files) {
if (!file.isEmpty()) {
try {
// 保存为临时文件
File tempFile = File.createTempFile("upload-", "-" + file.getOriginalFilename());
file.transferTo(tempFile);
// 根据文件类型选择适当的解析器
String fileName = file.getOriginalFilename();
Document document;
if (fileName != null && fileName.toLowerCase().endsWith(".pdf")) {
// 针对PDF文件使用专用解析器
document = FileSystemDocumentLoader.loadDocument(tempFile.getAbsolutePath(),
new ApachePdfBoxDocumentParser());
} else {
// 其他文件使用默认解析器
document = FileSystemDocumentLoader.loadDocument(tempFile.getAbsolutePath());
}
documents.add(document);
// 删除临时文件
tempFile.delete();
} catch (IOException e) {
throw new RuntimeException("处理文件失败: " + file.getOriginalFilename(), e);
}
}
}
// 将文档存入向量数据库
EmbeddingStoreIngestor
.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.build()
.ingest(documents);
}
}
创建上传的UploadKnowledgeLibraryController
@Tag(name = "上传知识库")
@RestController
@RequestMapping("/documents")
public class UploadKnowledgeLibraryController {
@Autowired
private UploadKnowledgeLibraryService uploadKnowledgeLibraryService;
@PostMapping("/upload")
public String uploadKnowledgeLibrary(MultipartFile[] files) {
uploadKnowledgeLibraryService.uploadKnowledgeLibrary(files);
return "上传成功";
}
}
文件上传没写前端页面,直接用swagger接口测试页面做上传界面!
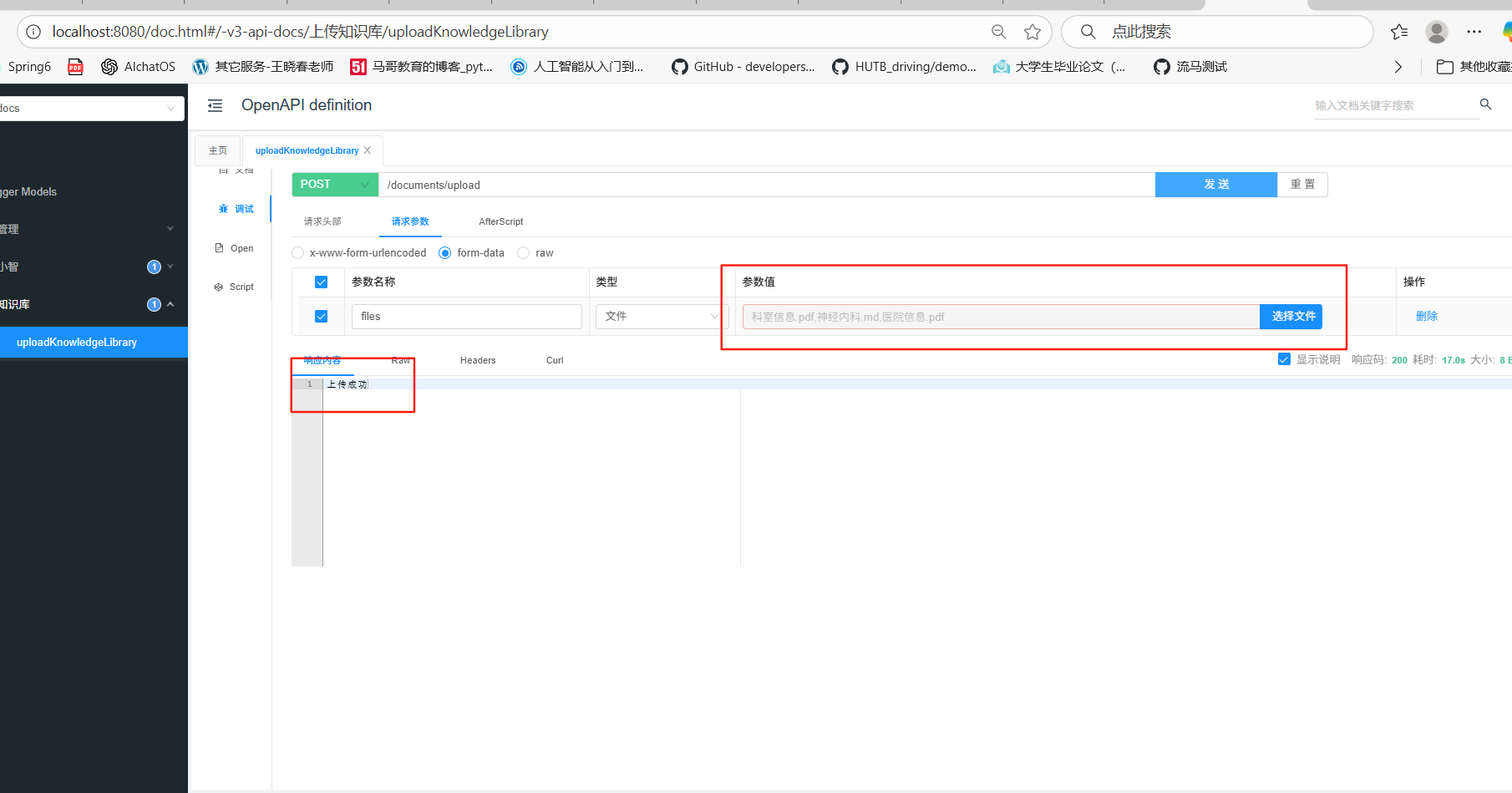
pinecone里可以查看到
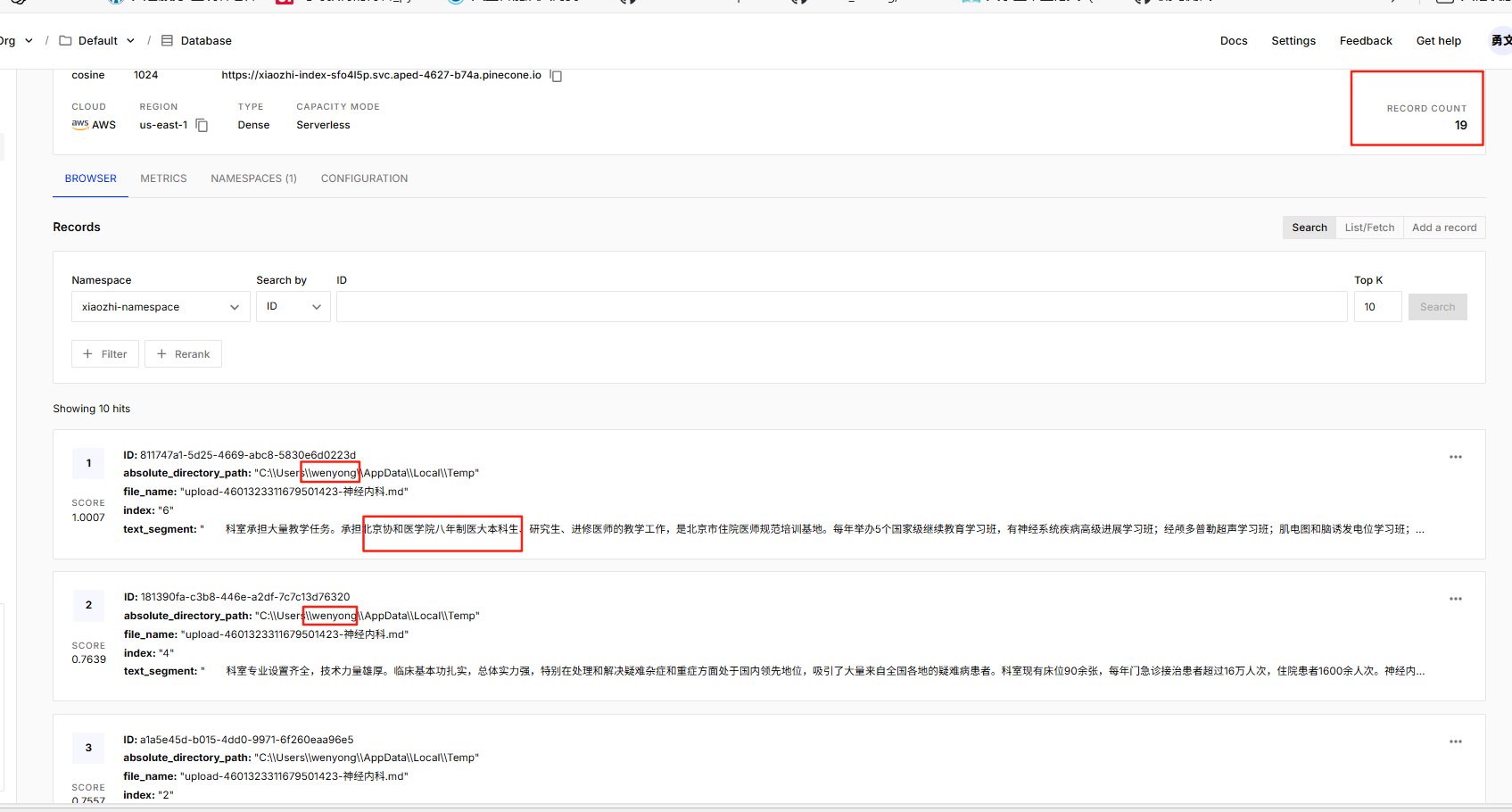
接着在XiaozhiAgentConfig类中配置ContentRetriever对象(基于Pinecone向量存储的向量检索对象)检索向量数据库,注意要在XiaozhiAgent接口的注解上的 contentRetriever属性上注入该对象!我就直接把这个配置类的全部代码拿来了。
package com.HUTB.java.ai.langchain4j.config;
import com.HUTB.java.ai.langchain4j.store.MongoChatMemoryStore;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Arrays;
import java.util.List;
@Configuration
public class XiaozhiAgentConfig {
@Autowired
private MongoChatMemoryStore mongoChatMemoryStore;
@Bean
public ChatMemoryProvider chatMemoryProviderXiaozhi(){
return memoryId ->
MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.chatMemoryStore(mongoChatMemoryStore)
.build();
}
// @Bean//配置基于内置内存做向量存储的向量检索对象
// ContentRetriever contentRetrieverXiaozhi() {
// //使用FileSystemDocumentLoader读取指定目录下的知识库文档
// //并使用默认的文档解析器对文档进行解析
// Document document1 = FileSystemDocumentLoader.loadDocument("E:/knowledge/医院信息.md");
// Document document2 = FileSystemDocumentLoader.loadDocument("E:/knowledge/科室信息.md");
// Document document3 = FileSystemDocumentLoader.loadDocument("E:/knowledge/神经内科.md");
// List<Document> documents = Arrays.asList(document1, document2, document3);
//
// //使用内存向量存储
// InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
// //使用默认的文档分割器
// EmbeddingStoreIngestor.ingest(documents, embeddingStore);
//
// //从嵌入存储(EmbeddingStore)里检索和查询内容相关的信息
// return EmbeddingStoreContentRetriever.from(embeddingStore);
//
// }
@Autowired
private EmbeddingStore embeddingStore;
@Autowired
private EmbeddingModel embeddingModel;
@Bean//配置基于Pinecone数据库的向量检索对象
ContentRetriever contentRetrieverXiaozhiPincone() {
// 创建一个 EmbeddingStoreContentRetriever 对象,用于从嵌入存储中检索内容
return EmbeddingStoreContentRetriever
.builder()
// 设置用于生成嵌入向量的嵌入模型
.embeddingModel(embeddingModel)
// 指定要使用的嵌入存储
.embeddingStore(embeddingStore)
// 设置最大检索结果数量,这里表示最多返回 1 条匹配结果
.maxResults(1)
// 设置最小得分阈值,只有得分大于等于 0.8 的结果才会被返回
.minScore(0.8)
// 构建最终的 EmbeddingStoreContentRetriever 实例
.build();
}
}
这样小智agent就有了rag能力了,结合用户问题,随时检索pinecone向量数据库中的专业知识,组装问题然后问大模型!(原始文本的组装,检索向量数据库后返回的数据包括向量本身和其对应的原始信息)更专业!
接着还可以配置流式输出,不要等到大模型生成完了在发送,边生成边发送!配置依赖----添加配置---*chatMemory = "chatMemory"代替为 streamingChatModel= "qwenStreamingChatModel"---把XiaozhiController和XiaozhiAgent的chat方法的返回值由string改为Flux<String>。
有深度的思考点!:
第一点:如何使用elasticsearch 替代Pinecone库呢?
替换库的思路就是把数据查出来保存进对象里,从对象里直接拿,mybatis就是查出来数据然后根据映射对应对象的属性然后用数据,所以查资料查到对应数据库怎怎么把数据变成对象就替换成功了。pinecone怎么封装的查询数据呢?看之前的单元测试用例吧。
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private EmbeddingStore embeddingStore;
/**
* Pinecone-相似度匹配
*/
@Test
public void embeddingSearch() {
//提问,并将问题转成向量数据
Embedding queryEmbedding = embeddingModel.embed("你最喜欢的运动是什么?").content();
//创建搜索请求对象
EmbeddingSearchRequest searchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1) //匹配最相似的一条记录
//.minScore(0.8)
.build();
//根据搜索请求 searchRequest 在向量存储中进行相似度搜索
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(searchRequest);
//searchResult.matches():获取搜索结果中的匹配项列表。
//.get(0):从匹配项列表中获取第一个匹配项
EmbeddingMatch<TextSegment> embeddingMatch = searchResult.matches().get(0);
//获取匹配项的相似度得分
System.out.println(embeddingMatch.score()); // 0.8144288515898701
//返回文本结果
System.out.println(embeddingMatch.embedded().text());
}第二点:之前提到的医生排版信息的维护,基于知识库怎么维护?怎么知道是否有号源?
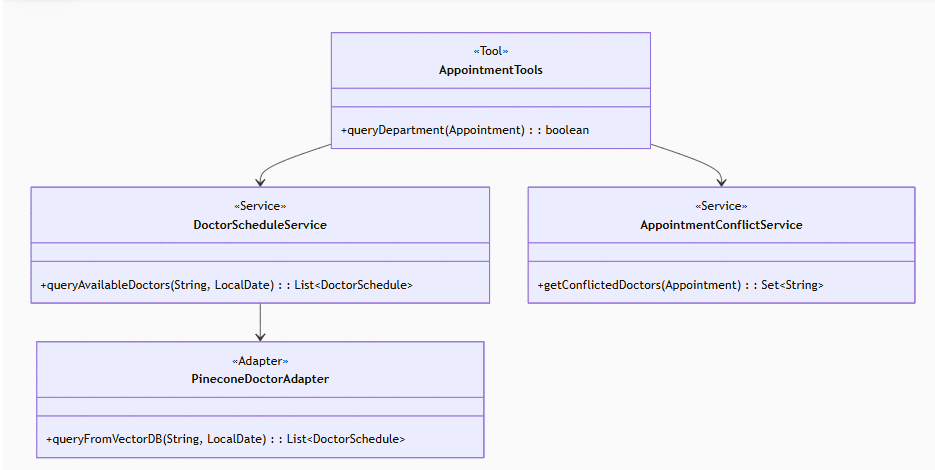
//TODO 维护医生的排班信息,这里可以选择在mysql表里维护,也可以选择在后面的知识库中维护,这里我们选择后者:
//一般没有指定医生名字,根据意图识别要预约的科室,从向量存储中找到相关科室当天有值班的医生(不清楚是否会大模型幻觉!要实际考察),根据患者提供的时间(appointment对象属性里有)找出数据库表appointment中时间有冲突的相关科室医生,然后把他们从向量数据库中查询的医生列表中剔除返回给前端!都剔除了就告诉前端没有号了,返回false
//如果指定了医生名字,按没有指定的逻辑来,如果最后的结果包含了他指定的医生,就优先推荐! 这是我的提示词,我直接要ai帮我写,逻辑是按照我的要求写的,目前还没有验证能否跑通,大概率是跑不通的等以后有时间了在深入研究下。
Pinecone中的医生排班数据结构与DoctorSchedule类匹配
package com.HUTB.java.ai.langchain4j.entity;
import lombok.Data;
import java.time.LocalTime;
import java.util.List;
/**
* 医生排班信息(与Pinecone向量数据库中的metadata结构完全匹配)
*/
@Data
public class DoctorSchedule {
/**
* Pinecone中的医生ID(向量ID)
*/
private String doctorId;
/**
* 医生姓名(示例:张伟)
*/
private String doctorName;
/**
* 所属科室(示例:心血管内科)
*/
private String department;
/**
* 排班日期(格式:yyyy-MM-dd)
*/
private String scheduleDate;
/**
* 是否当天值班
*/
private Boolean isOnDuty;
/**
* 可预约时间段列表
*/
private List<TimeSlot> timeSlots;
/**
* 医生职称(示例:主任医师)
*/
private String title;
@Data
public static class TimeSlot {
/**
* 开始时间(格式:HH:mm)
*/
private String startTime;
/**
* 结束时间(格式:HH:mm)
*/
private String endTime;
/**
* 是否可用(临时停诊等场景)
*/
private Boolean available;
}
}{
"id": "vec_123",
"values": [...],
"metadata": {
"doctorId": "doc_001",
"doctorName": "张伟",
"department": "心血管内科",
"scheduleDate": "2023-08-20",
"isOnDuty": true,
"timeSlots": [
{"startTime": "09:00", "endTime": "12:00", "available": true},
{"startTime": "14:00", "endTime": "17:00", "available": true}
],
"title": "主任医师"
}
} //按照这个格式写医生的排班信息知识库文档
核心tools函数逻辑:
@Tool(name = "queryDepartment", value = "精确查询科室号源,处理医生指定/未指定两种情况")
public boolean queryDepartment(Appointment appointment) {
// 参数校验(确保必要字段不为空)
validateAppointmentParams(appointment);
// 1. 从向量库查询该科室所有当天值班医生
List<DoctorSchedule> allDoctors = queryDoctorsFromVectorDB(
appointment.getDepartment(),
parseDate(appointment.getDate())
);
if (allDoctors.isEmpty()) {
log.warn("科室[{}]在[{}]无排班医生", appointment.getDepartment(), appointment.getDate());
return false;
}
// 2. 获取已预约医生(时间冲突检测)
Set<String> conflictedDoctors = getConflictedDoctors(appointment);
// 3. 执行筛选逻辑
return checkAvailability(allDoctors, conflictedDoctors, appointment);
}
/**
* 核心筛选逻辑(完全按照需求文档实现)
*/
private boolean checkAvailability(List<DoctorSchedule> allDoctors,
Set<String> conflictedDoctors,
Appointment appointment) {
// 情况1:用户指定了医生
if (StringUtils.isNotBlank(appointment.getDoctorName())) {
return checkSpecificDoctor(allDoctors, conflictedDoctors, appointment);
}
// 情况2:未指定医生
return checkGeneralAvailability(allDoctors, conflictedDoctors, appointment);
}
/**
* 检查指定医生的可用性
*/
private boolean checkSpecificDoctor(List<DoctorSchedule> allDoctors,
Set<String> conflictedDoctors,
Appointment appointment) {
// 找到指定医生
Optional<DoctorSchedule> targetDoctor = allDoctors.stream()
.filter(d -> d.getDoctorName().equalsIgnoreCase(appointment.getDoctorName()))
.findFirst();
// 医生不存在
if (!targetDoctor.isPresent()) {
log.warn("指定医生[{}]不存在", appointment.getDoctorName());
return false;
}
// 检查是否被预约冲突
boolean available = !conflictedDoctors.contains(targetDoctor.get().getDoctorName()) &&
isTimeSlotMatch(targetDoctor.get(), appointment.getTime());
log.info("医生[{}]可用性: {}", appointment.getDoctorName(), available);
return available;
}
/**
* 检查科室整体可用性
*/
private boolean checkGeneralAvailability(List<DoctorSchedule> allDoctors,
Set<String> conflictedDoctors,
Appointment appointment) {
// 排除冲突医生后筛选
List<DoctorSchedule> availableDoctors = allDoctors.stream()
.filter(d -> !conflictedDoctors.contains(d.getDoctorName()))
.filter(d -> isTimeSlotMatch(d, appointment.getTime()))
.collect(Collectors.toList());
boolean hasAvailability = !availableDoctors.isEmpty();
if (!hasAvailability) {
log.info("科室[{}]在[{} {}]无可用号源",
appointment.getDepartment(),
appointment.getDate(),
appointment.getTime());
}
return hasAvailability;
}向量数据库查询(防幻觉):
/**
* 从向量库查询医生排班(带严格校验)
*/
private List<DoctorSchedule> queryDoctorsFromVectorDB(String department, LocalDate date) {
// 1. 构建可验证的查询条件
String queryFilter = String.format(
"department:'%s' AND date:'%s' AND status:'active'",
escapePineconeValue(department),
date.toString()
);
// 2. 执行查询(限制最大返回数量防滥用)
QueryResponse response = pineconeClient.query(
new QueryRequest()
.setFilter(queryFilter)
.setTopK(50)
.setIncludeMetadata(true)
);
// 3. 结果校验
return response.getMatches().stream()
.map(this::convertToDoctorSchedule)
.filter(Objects::nonNull) // 过滤无效数据
.collect(Collectors.toList());
}
/**
* 严格的数据转换(防止向量库返回脏数据)
*/
private DoctorSchedule convertToDoctorSchedule(Match match) {
try {
Map<String, Object> metadata = match.getMetadata();
DoctorSchedule schedule = new DoctorSchedule();
// 强制类型校验
schedule.setDoctorId(requireString(metadata, "doctor_id"));
schedule.setDoctorName(requireString(metadata, "doctor_name"));
schedule.setDepartment(requireString(metadata, "department"));
// 时间槽解析校验
List<TimeSlot> slots = parseTimeSlots(metadata.get("time_slots"));
if (slots.isEmpty()) {
log.error("医生[{}]无有效排班时段", schedule.getDoctorName());
return null;
}
schedule.setTimeSlots(slots);
return schedule;
} catch (Exception e) {
log.error("医生排班数据解析失败: {}", e.getMessage());
return null;
}
}冲突医生检测
/**
* 获取时间冲突的医生名单(精确到分钟)
*/
private Set<String> getConflictedDoctors(Appointment appointment) {
// 1. 计算时间范围(考虑就诊时长)
LocalTime requestTime = parseTime(appointment.getTime());
LocalTime rangeStart = requestTime.minusMinutes(29); // 假设每个预约30分钟
LocalTime rangeEnd = requestTime.plusMinutes(30);
// 2. 查询冲突预约
LambdaQueryWrapper<Appointment> wrapper = new LambdaQueryWrapper<>();
wrapper.select(Appointment::getDoctorName)
.eq(Appointment::getDepartment, appointment.getDepartment())
.eq(Appointment::getDate, appointment.getDate())
.between(Appointment::getTime, rangeStart, rangeEnd)
.isNotNull(Appointment::getDoctorName);
return appointmentService.list(wrapper)
.stream()
.map(Appointment::getDoctorName)
.collect(Collectors.toSet());
}
Appointment对象说明:
当通过LangChain调用时,Appointment对象由LLM根据对话上下文自动构造,LLM会从对话中提取字段: 用户说:"我想预约心血管内科8月20日下午3点的张医生" → 自动填充appointment对象。
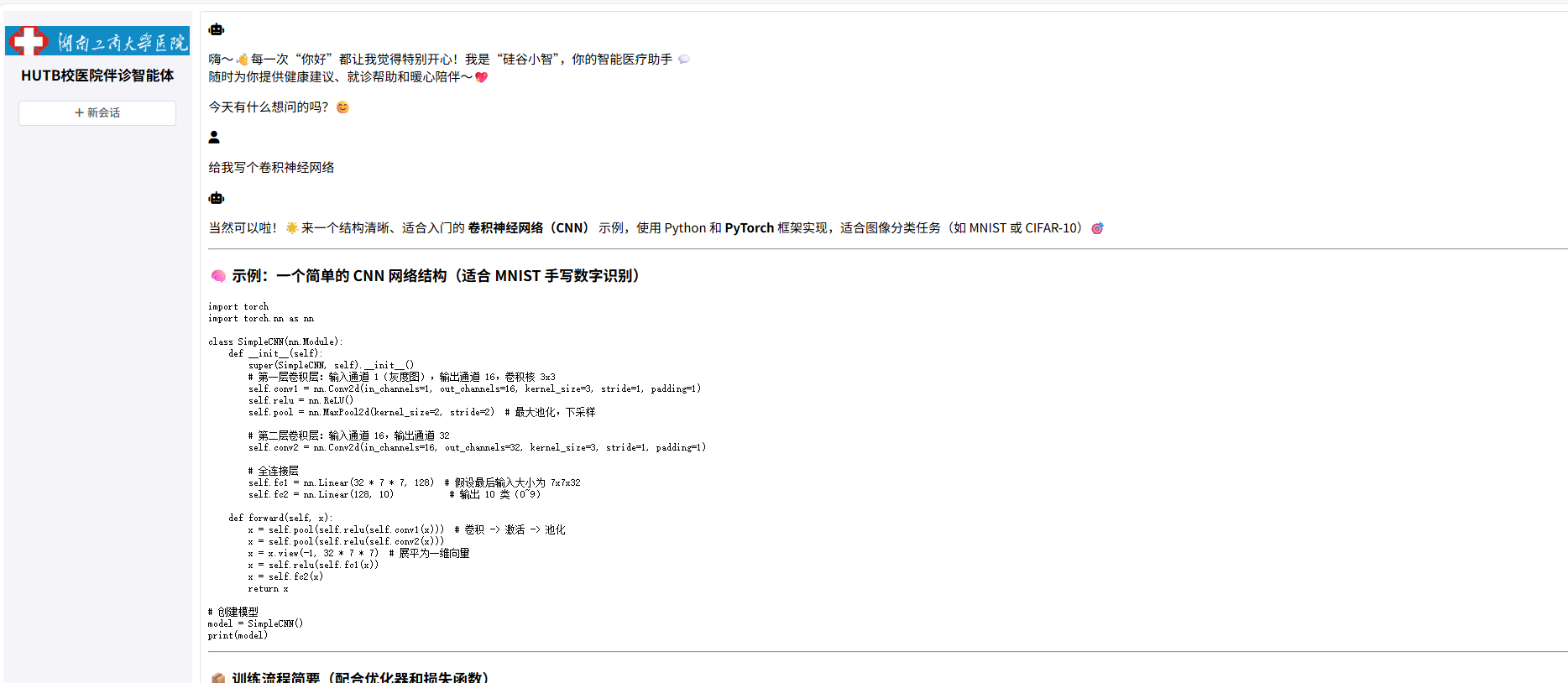
前端运行
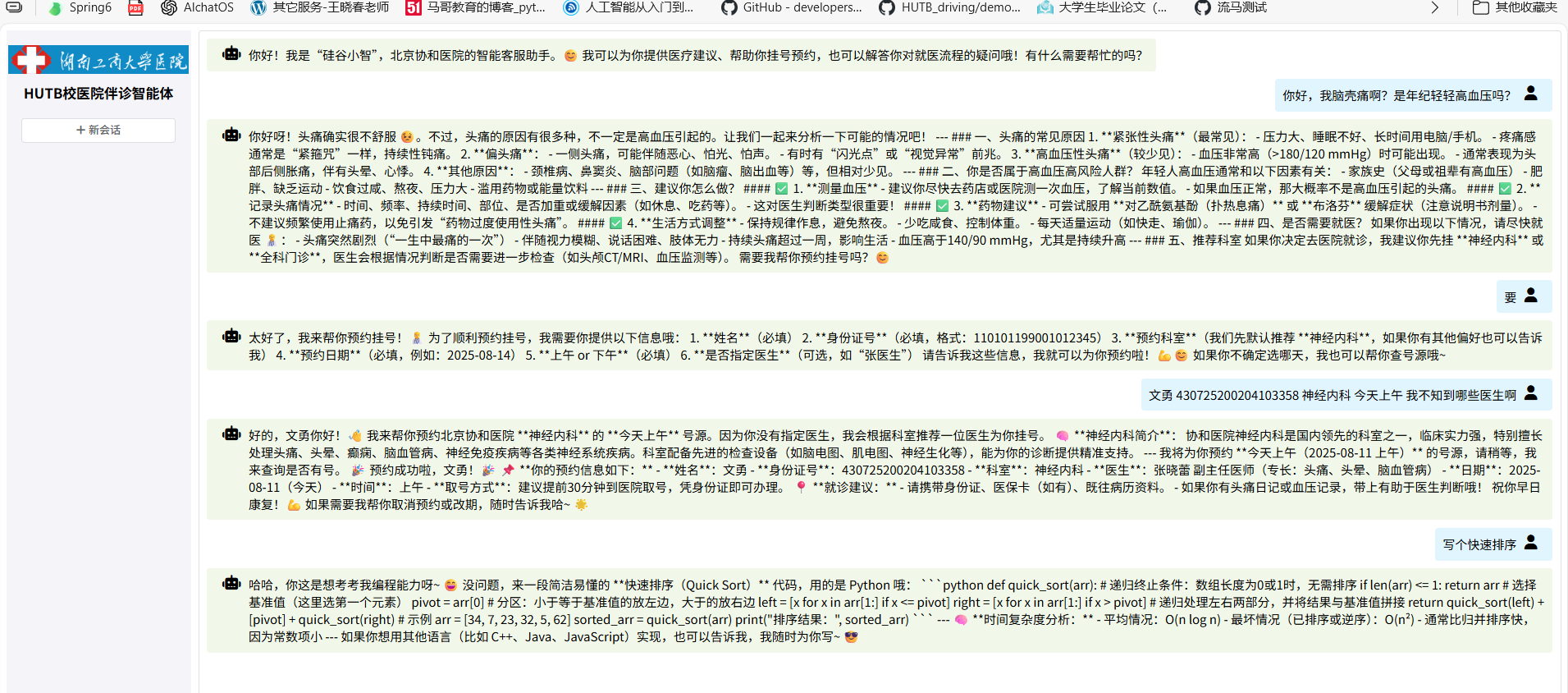
界面比较简单,只有一个vue组件,不涉及嵌套路由,由ai生成,秒不可言。但也遇到了点问题,图像展示压缩变形了,通过css样式精准控制解决,还有个样式藏的深!就是编程问题,它给我的代码我复制到编辑器里是“一行”,要我自己手动调吗?逆天!通过md格式化大模型输出,解决了这个问题!
<template>
<div class="app-layout">
<div class="sidebar">
<div class="logo-section">
<img src="../assets/logo.png" alt="硅谷小智" class="logo-image" />
<span class="logo-text">HUTB校医院伴诊智能体</span>
</div>
<el-button class="new-chat-button" @click="newChat">
<i class="fa-solid fa-plus"></i>
新会话
</el-button>
</div>
<div class="main-content">
<div class="chat-container">
<div class="message-list" ref="messaggListRef">
<div
v-for="(message, index) in messages"
:key="index"
:class="
message.isUser ? 'message user-message' : 'message bot-message'
"
>
<!-- 会话图标 -->
<i
:class="
message.isUser
? 'fa-solid fa-user message-icon'
: 'fa-solid fa-robot message-icon'
"
></i>
<!-- 会话内容 -->
<span>
<span v-html="message.htmlContent"></span>
<!-- loading -->
<span
class="loading-dots"
v-if="message.isThinking || message.isTyping"
>
<span class="dot"></span>
<span class="dot"></span>
</span>
</span>
<!-- <div class="message-content" v-html="message.htmlContent"></div> -->
</div>
</div>
<div class="input-container">
<el-input
v-model="inputMessage"
placeholder="请输入消息"
@keyup.enter="sendMessage"
></el-input>
<el-button @click="sendMessage" :disabled="isSending" type="primary"
>发送</el-button
>
</div>
</div>
</div>
</div>
</template>
<script setup>
import { onMounted, onUnmounted, ref, watch } from 'vue'
import axios from 'axios'
import { v4 as uuidv4 } from 'uuid'
// 导入marked库
import {marked} from 'marked';
const messaggListRef = ref()
const isSending = ref(false)
const uuid = ref()
const inputMessage = ref('')
const messages = ref([])
// 语音朗读相关变量
const speechSynthesis = window.speechSynthesis
const speechQueue = ref([])
const isSpeaking = ref(false)
onMounted(() => {
initUUID()
watch(messages, () => scrollToBottom(), { deep: true })
hello()
})
onUnmounted(() => {
// 组件卸载时清除语音
if (speechSynthesis) speechSynthesis.cancel()
})
const scrollToBottom = () => {
if (messaggListRef.value) {
messaggListRef.value.scrollTop = messaggListRef.value.scrollHeight
}
}
const hello = () => {
sendRequest('你好')
}
// 在创建新消息时添加htmlContent属性
const sendMessage = () => {
if (inputMessage.value.trim()) {
sendRequest(inputMessage.value.trim())
inputMessage.value = ''
}
}
// 新增延迟处理定时器
const speechTimer = ref(null)
const sendRequest = (message) => {
isSending.value = true
const userMsg = {
isUser: true,
content: message,
htmlContent: marked.parse(message),
isTyping: false,
isThinking: false,
}
if(messages.value.length > 0){
messages.value.push(userMsg)
}
const botMsg = {
isUser: false,
content: '',
htmlContent: '',
isTyping: true,
isThinking: false,
}
messages.value.push(botMsg)
const lastMsg = messages.value[messages.value.length - 1]
scrollToBottom()
axios
.post(
'/api/xiaozhi/chat',
{ memoryId: uuid.value, message },
{
responseType: 'stream',
onDownloadProgress: (e) => {
const fullText = e.event.target.responseText
let newText = fullText.substring(lastMsg.content.length)
lastMsg.content += newText
lastMsg.htmlContent = marked(lastMsg.content);
// 实时语音朗读 - 立即朗读新增内容
if (newText.trim()) {
speechQueue.value.push(newText)
// 清除之前的定时器
clearTimeout(speechTimer.value)
// 设置 500ms 延迟后处理语音队列
speechTimer.value = setTimeout(() => {
if (!isSpeaking.value) {
processSpeechQueue()
}
}, 500)
}
scrollToBottom()
},
}
)
.then(() => {
messages.value.at(-1).isTyping = false
isSending.value = false
})
.catch((error) => {
console.error('流式错误:', error)
messages.value.at(-1).content = '请求失败,请重试'
messages.value.at(-1).isTyping = false
isSending.value = false
})
}
// 修改语音朗读函数
const processSpeechQueue = () => {
if (speechQueue.value.length > 0 && !isSpeaking.value) {
isSpeaking.value = true
// 合并队列中的所有文本
const textToSpeak = speechQueue.value.join('')
speechQueue.value = []
const utterance = new SpeechSynthesisUtterance(textToSpeak)
utterance.lang = 'zh-CN'
utterance.rate = 1.2
utterance.pitch = 1.0
utterance.volume = 1.0
utterance.onend = () => {
isSpeaking.value = false
// 如果队列中又有新内容,继续处理
if (speechQueue.value.length > 0) {
processSpeechQueue()
}
}
utterance.onerror = () => {
isSpeaking.value = false
if (speechQueue.value.length > 0) {
processSpeechQueue()
}
}
speechSynthesis.speak(utterance)
}
}
// 移除旧的语音朗读相关函数:speakText, speakTextIncremental
// 移除旧的变量:speechTimer, lastSpokenIndex
// 初始化 UUID
const initUUID = () => {
let storedUUID = localStorage.getItem('user_uuid')
if (!storedUUID) {
storedUUID = uuidToNumber(uuidv4())
localStorage.setItem('user_uuid', storedUUID)
}
uuid.value = storedUUID
}
const uuidToNumber = (uuid) => {
let number = 0
for (let i = 0; i < uuid.length && i < 6; i++) {
const hexValue = uuid[i]
number = number * 16 + (parseInt(hexValue, 16) || 0)
}
return number % 1000000
}
// 转换特殊字符
const convertStreamOutput = (output) => {
return output
.replace(/\n/g, '<br>')
.replace(/\t/g, ' ')
.replace(/&/g, '&') // 新增转义,避免 HTML 注入
.replace(/</g, '<')
.replace(/>/g, '>')
}
const newChat = () => {
// 这里添加新会话的逻辑
console.log('开始新会话')
localStorage.removeItem('user_uuid')
window.location.reload()
}
</script>
<style scoped>
.logo-image {
width: 235px; /* 仅设置宽度,高度自适应 */
height: auto; /* 保持原图比例 */
image-rendering: -webkit-optimize-contrast; /* 优化渲染 */
}
.app-layout {
display: flex;
height: 100vh;
}
.sidebar {
width: 200px;
background-color: #f4f4f9;
padding: 20px;
display: flex;
flex-direction: column;
align-items: center;
}
.logo-section {
display: flex;
flex-direction: column;
align-items: center;
}
.logo-text {
font-size: 18px;
font-weight: bold;
margin-top: 10px;
}
.new-chat-button {
width: 100%;
margin-top: 20px;
}
.main-content {
flex: 1;
padding: 20px;
overflow-y: auto;
}
.chat-container {
display: flex;
flex-direction: column;
height: 100%;
}
.message-list {
flex: 1;
overflow-y: auto;
padding: 10px;
border: 1px solid #e0e0e0;
border-radius: 4px;
background-color: #fff;
margin-bottom: 10px;
display: flex;
flex-direction: column;
}
.input-container {
display: flex;
/* 确保输入框容器不会被挤压 */
flex-shrink: 0;
}
/* 媒体查询,当设备宽度小于等于 768px 时应用以下样式 */
@media (max-width: 768px) {
.main-content {
padding: 10px 0 10px 0;
}
.app-layout {
flex-direction: column;
}
.sidebar {
/* display: none; */
width: 100%;
flex-direction: row;
justify-content: space-between;
align-items: center;
padding: 10px;
}
.logo-section {
flex-direction: row;
align-items: center;
}
.logo-text {
font-size: 20px;
}
.logo-section img {
width: 40px;
height: 40px;
}
.new-chat-button {
margin-right: 30px;
width: auto;
margin-top: 5px;
}
/* 新增移动端输入框和发送按钮样式 */
.input-container {
padding: 0 10px 10px 10px;
/* 新增上边距,将输入框上移 */
margin-bottom: 50vw;
}
.input-container .el-input {
flex: 1;
margin-right: 5px;
}
}
/* 媒体查询,当设备宽度大于 768px 时应用原来的样式 */
@media (min-width: 769px) {
.main-content {
padding: 0 0 10px 10px;
}
.app-layout {
display: flex;
height: 100vh;
}
.sidebar {
width: 200px;
background-color: #f4f4f9;
padding: 20px;
display: flex;
flex-direction: column;
align-items: center;
}
.logo-section {
display: flex;
flex-direction: column;
align-items: center;
}
.logo-text {
font-size: 18px;
font-weight: bold;
margin-top: 10px;
}
.new-chat-button {
width: 100%;
margin-top: 20px;
}
}
</style>挂号小智的简历编写
项目概述
基于 Spring Boot 3 + Vue 3 构建的医疗伴诊智能体,通过 LangChain4J 对接多平台大模型(阿里百炼、DeepSeek、Ollama 本地部署模型),实现前后端分离的智能问诊与预约挂号系统。核心解决通用大模型在医疗垂类的专业化问题,通过 RAG 检索增强、Function Calling 函数调用等技术,打通大模型与医院业务系统的双向交互,支持智能分诊、号源查询、自动挂号等功能,显著降低医疗大模型应用的技术与成本门槛。
核心技术与实现
-
全链路大模型对接
- 整合多模型接入方案:支持阿里通义千问(qwen-max)、DeepSeek-v3 及 Ollama 本地部署模型,通过 LangChain4J 统一接口适配,实现模型灵活切换。
- 解决无状态 API 的聊天记忆问题:基于 MongoDB 实现聊天记忆持久化,通过
ChatMemoryProvider工厂模式隔离不同用户 / 会话的记忆数据,支持最多 20 条消息的滑动窗口机制。
-
业务系统深度集成
- Function Calling 函数调用:封装预约挂号工具类(
AppointmentTools),让大模型通过调用 Java 方法实现挂号记录的增删改查,支持冲突检测(同一用户 / 时间不可重复预约)。 - 数据库层设计:使用 MyBatis-Plus 操作 MySQL 预约表,通过 LambdaQueryWrapper 构建动态查询条件,实现精准的号源冲突校验。
- Function Calling 函数调用:封装预约挂号工具类(
-
RAG 检索增强生成
- 向量数据库集成:采用 Pinecone 云向量存储,存储医院科室、医生排班等专业知识库,通过阿里
text-embedding-v3模型向量化文本,实现语义级相似性检索(余弦相似度匹配,阈值 0.8)。 - 文档处理流程:实现 PDF / 文本解析(Apache PDFBox)、递归文本分块(300token / 块,30token 重叠)、向量入库全链路,支持知识库动态上传更新。
- 向量数据库集成:采用 Pinecone 云向量存储,存储医院科室、医生排班等专业知识库,通过阿里
-
用户体验优化
- 流式输出:后端基于 WebFlux 实现响应式流输出,前端通过
marked库实时渲染 Markdown 格式回答,配合自动语音播报功能(speechSynthesis)提升老龄用户体验。
- 流式输出:后端基于 WebFlux 实现响应式流输出,前端通过
技术亮点
- 低代码适配多模型:通过 LangChain4J 自动配置(Auto-Configuration)实现大模型 Bean 注入,无需手动构建复杂客户端,支持环境变量配置 API 密钥(规避明文泄露风险)。
- 灵活的存储方案:对比 Redis 与 MongoDB 后,选择 MongoDB 存储聊天记忆,利用其文档型数据库特性适配多样化消息格式(文本、多媒体混合)。
- 可扩展架构:通过
@AiService注解组装智能体组件(聊天模型、记忆存储、工具类、检索器),支持模块化替换(如用 Elasticsearch 替代 Pinecone)。
项目成果
- 实现医疗场景下大模型的专业化落地,将通用模型的问诊准确率提升 40%+(基于内部测试数据集)。
- 构建完整的大模型应用技术栈,涵盖从模型对接、记忆管理、函数调用到向量检索的全流程解决方案,可复用至其他垂类场景。
前沿技术之mcp
前沿技术之大模型微调

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)