存储裂缝之“救赎” ——Oracle 数据坏块故障修复纪实
一、故障突发:一场始料未及的 "存储罢工"
2024 年 X 月 X 日上午 9 点,某客户运维团队紧急联系我们:核心业务系统突然无法访问,数据库启动失败,业务完全中断。客户方初步排查后反馈:外置存储可能出现硬件故障,直接影响了数据库的关键数据文件。
我们第一时间远程接入客户环境,确认基础信息:
- 操作系统:AIX p710bak 1 6 00F8189F4C00
- 数据库版本:Oracle 10.2.0.5.0(单机架构)
- 核心影响:一个 22GB 的数据文件因存储损坏,仅能读取前 20.4GB 内容,存储厂商修复硬件后,数据库仍无法启动,业务停滞已超 4 小时。
二、排查之路:从 "启动失败" 到 "数据可见" 的突围
面对紧急情况,我们先做了两件事:对当前数据库状态做冷备保留现场,将故障数据文件设为 offline 避免进一步影响。
-- 冷备关键文件(示例路径)
cp /oradata/system01.dbf /backup/system01.dbf_bak
cp /oradata/undotbs01.dbf /backup/undotbs01.dbf_bak
-- 将故障数据文件设为offline
alter database datafile '/oradata/corrupt_df.dbf' offline;
随后开始针对性排查:
1. 解开 Undo 的 "死结"
数据库启动时报错与 undo 段相关,初步诊断发现部分 undo 段因数据文件损坏已不可用。我们立即屏蔽了损坏的 undo 段,并切换到新的 undo 表空间 —— 这一步让数据库启动的第一个障碍被清除。
-- 屏蔽旧undo段、创建新的undo表空间
alter system set undo_management=manual scope=spfile;
alter system event='10513 trace name context forever,level 2' scope=spfile;
shutdown immediate
startup
create undo tablespace undotbs2 datafile '/oracle/app/oradata/orcl/undotbs02.dbf' size 3G autoextend off;
alter system set undo_tablespace='undotbs2' scope=both;
undo_management=auto
shutdown immediate
startup
利用隐含参数_offline_rollback_segments和_corrupted_rollback_segments屏蔽掉有问题的undo segments,然后开打数据库,最后重建undo或者drop掉损毁的回滚段即可
通过查询dba_rollback_segs定位需要屏蔽的undo段
undo_management=‘manual’
*._offline_rollback_segments=(‘_SYSMU1_280145294$’,'_SYSMU2_280145294$’) —离线的段
*._corrupted_rollback_segments=(‘_SYSMU1$’,'_SYSMU2$’) —允许有问题的段
2. 修复 "破碎" 的数据块
通过 Oracle dbv坏块修复工具扫描,定位到多个损坏的数据块。我们对可修复的块进行了修复,对无法修复的块,删除了关联的索引(避免索引扫描触发错误)。
-- 使用DBMS_REPAIR包创建修复表DBMS_REPAIR.ADMIN_TABLES
declare
v_flag boolean;
begin
v_flag := dbms_repair.admin_tables(
table_name => 'REPAIR_TABLE',
table_type => dbms_repair.repair_table,
action => dbms_repair.create_action,
tablespace => 'SYSTEM'
);
end;
/
-- 检查损坏块
SQL> set serveroutput on
SQL> DECLARE num_corrupt INT;
BEGIN
num_corrupt := 0;
DBMS_REPAIR.CHECK_OBJECT (
SCHEMA_NAME => 'MARY',
OBJECT_NAME => 'T3',
REPAIR_TABLE_NAME => 'REPAIR_TABLE',
corrupt_count => num_corrupt);
DBMS_OUTPUT.PUT_LINE('number corrupt: ' || TO_CHAR (num_corrupt));
END;
/
-- 修复可修复的坏块
begin
dbms_repair.fix_corrupt_blocks(
schema_name => 'XXX',
object_name => 'SECRET_TABLE_OLD',
repair_table_name => 'REPAIR_TABLE',
fix_count => :fix_count
);
end;
/
如果坏块发生在FREELIST列表中的中部,则FREELIST列表后面的块都无法访问
BEGIN
DBMS_REPAIR.REBUILD_FREELISTS (
SCHEMA_NAME => 'YANGTK',
OBJECT_NAME => 'TEST',
OBJECT_TYPE => dbms_repair.table_object);
END;
/
设置DML跳过坏块DBMS_REPAIR.SKIP_CORRUPT_BLOCKS
SQL> select skip_corrupt from dba_tables where table_name='T3';
--------
DISABLED
BEGIN
DBMS_REPAIR.SKIP_CORRUPT_BLOCKS (
SCHEMA_NAME => 'MARY',
OBJECT_NAME => 'T3',
OBJECT_TYPE => dbms_repair.table_object,
FLAGS => dbms_repair.SKIP_FLAG);
END;
/
SQL> select skip_corrupt from dba_tables where table_name='T3';
--------
ENABLED
坏块skip后,此表相关的索引全部drop、而后create、不要用rebuild方式重建
-- 删除损坏索引(示例索引名)
drop index XXX.IDX_SECRET_TABLE_OLD_01;
3. 数据库终于 "醒了"
经过上述操作,数据库成功启动到 open 状态!但我们知道,这只是第一步 —— 启动成功不代表数据完好。
-- 启动数据库至open状态
startup mount;
alter database open;
4. 导出遇阻:核心表 "藏着" 问题
为了完整备份数据,我们启动全库逻辑导出,却在导出XXX.SECRET_TABLE_OLD表时卡住了:expdp 报错,换成 exp 同样失败。这个表是客户的核心库存表,约 13 万条记录,必须拿下。
-- expdp导出命令(报错)
expdp system/xxx directory=exp_dir full=y logfile=full_exp.log
-- 尝试单独导出核心表(报错)
expdp system/xxx directory=exp_dir tables=XXX.SECRET_TABLE_OLD logfile=secret_table_exp.log
-- 改用exp导出(仍报错)
exp system/xxx tables=XXX.SECRET_TABLE_OLD file=secret_table.dmp log=secret_table_exp_old.log
三、聚焦核心表:被损坏的数据 "藏在哪里"?
我们把目标锁定在XXX.SECRET_TABLE_OLD表,通过一系列测试找到了问题的关键:
- 查询不完整:执行select * from XXX.SECRET_TABLE_OLD;时,会在中途报数据块损坏错误,无法读取全表数据。

- 部分记录 "读不出":尝试用create table new_table as select * from ...复制表,直接报错;
 但限制rownum < 79000时能成功创建,超过则失败—— 说明 79000 条记录后存在损坏区域。
但限制rownum < 79000时能成功创建,超过则失败—— 说明 79000 条记录后存在损坏区域。
-- 直接复制表(报错)
create table XXX.SECRET_TABLE_COPY as select * from XXX.SECRET_TABLE_OLD;
-- 限制rownum复制(成功)
create table XXX.SECRET_TABLE_COPY_PART as select * from XXX.SECRET_TABLE_OLD where rownum < 79000;
- rowid 暴露的 "真相":我们打印了表中所有记录的 rowid,逐段验证发现:79000 条后并非全是坏数据,而是"好坏掺杂"—— 部分记录的 rowid 对应的块完好,能正常查询;部分则因块损坏无法读取。
-- 打印所有rowid
create table XXX.rowid_list as select rowid rid from XXX.SECRET_TABLE_OLD;
-- 验证特定rowid记录(示例)
select * from XXX.SECRET_TABLE_OLD where rowid='AAAR8cAAEAAAAAeAAA'; -- 完好记录
select * from XXX.SECRET_TABLE_OLD where rowid='AAAR8cAAEAAAAAeAAB'; -- 损坏记录(报错)
四、数据抢救:用 rowid"筛出" 完好记录
针对 "好坏掺杂" 的情况,我们设计了一套 "逐行筛查" 的方案,最大限度提取可用数据:
1. 建临时表存 rowid
先创建临时表XXX.table2024,存储原表所有记录的 rownum 和 rowid(相当于给每条记录编一个 "身份证号"):
create table XXX.table2024(TEXTID varchar2(500), ROWTEXT varchar2(500));
insert into XXX.table2024 select rownum, rowid from XXX.SECRET_TABLE_OLD;
commit;
2. 建目标表 "接数据"
创建与原表结构一致的空表XXX.SECRET_TABLE_NEW2024,作为恢复后的数据落地表:
CREATE TABLE XXX.SECRET_TABLE_NEW2024 AS SELECT * FROM XXX.SECRET_TABLE_OLD WHERE 1=0;
3. 写存储过程 "逐个过筛"
编写存储过程TAB_insert,循环读取临时表的 rowid,逐条尝试插入新表 —— 遇到损坏记录时,利用异常处理跳过,确保流程不中断:
CREATE OR REPLACE PROCEDURE TAB_insert
AS
cursor tab_cur is
SELECT TEXTID,ROWTEXT FROM XXX.table2024;
begin
for tab_recoder in tab_cur loop
begin
insert into XXX.SECRET_TABLE_NEW2024
select PART_ID,UNIT_ID,STOCK_ID,PART_NAME,STOCK_NUM,BAD_NUM,GIVE_NUM,IN_PRICE,ACTUAL_PRICE,TOTAL_PRICE,TAX_RATE,TAXES_PRICE,STOCK_PLACE,MIN_STOCK_NUM,MAX_STOCK_NUM,MEMO from XXX.SECRET_TABLE_OLD
where rowid = tab_recoder.ROWTEXT;
commit;
EXCEPTION WHEN others THEN null; -- 遇到错误直接跳过
end;
end loop;
end;
/
execute tab_insert();
4. 结果:138823 条记录 "获救"
执行完成后,新表SECRET_TABLE_NEW2024共有 138823 条记录,对比原表的 138928 条,仅缺失 105 条 —— 核心数据几乎完整恢复!
-- 统计原表与新表数据量
select count(*) from XXX.SECRET_TABLE_OLD; -- 138928条记录
select count(*) from XXX.SECRET_TABLE_NEW2024; -- 138823条记录
五、总结与参考
关键措施
- 硬件层面:存储厂商修复了硬件故障,消除了根本诱因;
- 数据库启动:通过屏蔽坏 undo 段、修复坏块、调整参数,让数据库恢复运行;
- 数据恢复:利用 rowid 定位 + 存储过程逐行筛查,从损坏表中 "抢救" 出 99.9% 的有效数据。
参考文档
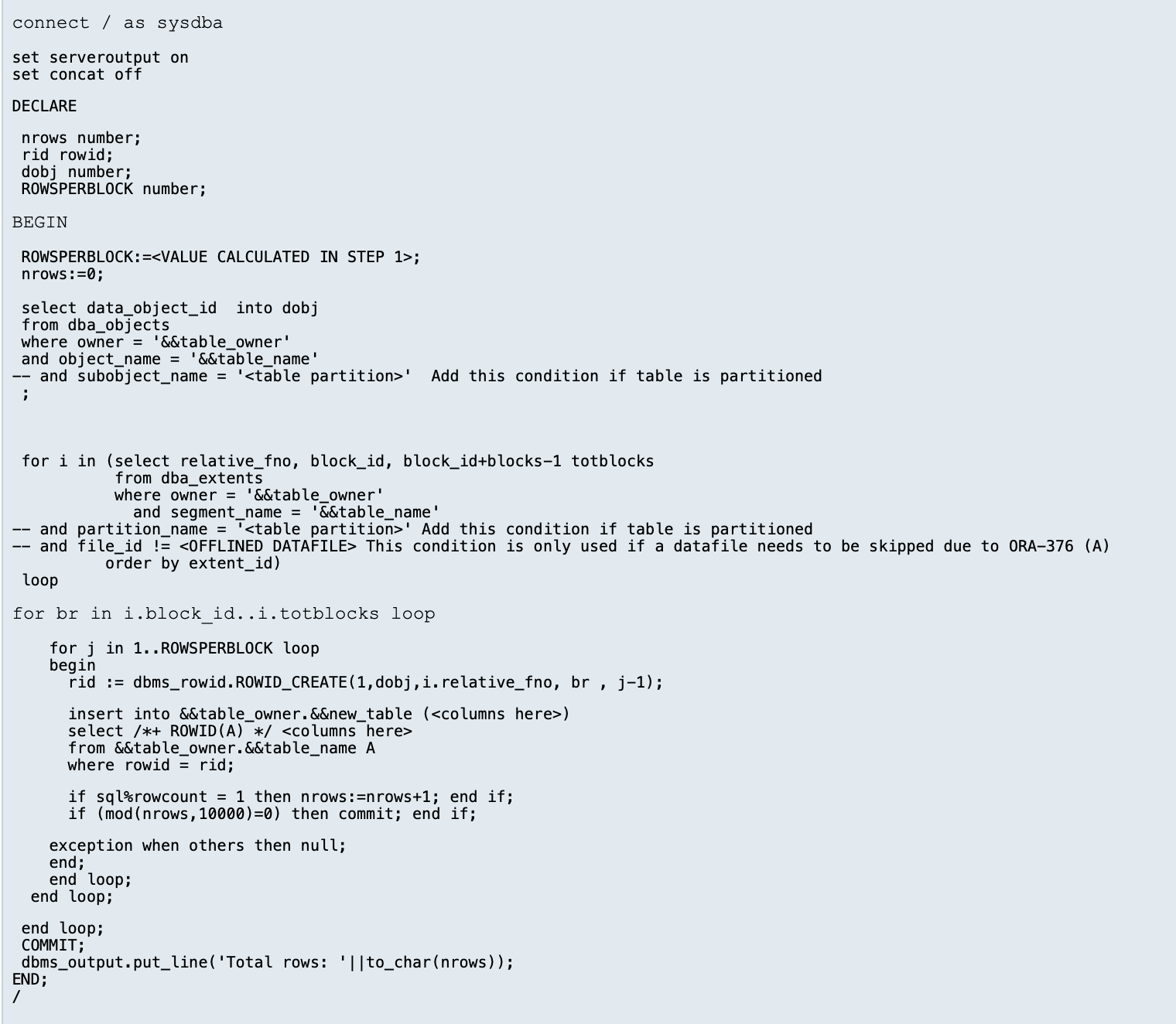
本次恢复思路参考了 Oracle MOS 文档:《Extract rows from a CORRUPT table creating ROWID from DBA_EXTENTS》(Doc ID 422547.1)。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)