【CNN】 卷积神经网络
1 起源 origin🚩CNN讲解它来咯!
🚩 番外篇:
CNN讲解它来咯!

文章目录
1 起源 origin
为了解决什么实际问题?
- 核心:让计算机像人眼一样理解图像内容
视觉在人脑中占据超过50%的比例,包含注意力分配,记忆,决策等
(后文将会给出:记忆对应于卷积核参数,决策对应于全连接之后的softmax函数输出,而注意力对应于transformer网络结构,注意力机制已经超出CNN范畴,本文将不做详细说明)
这对人的视觉来说很简单,我们可以很容易地看出,图像中有一只cat和一只dog,并且能够给出他们的颜色,位置等信息。
要解决的问题是:如何让机器(计算机)知道图像上有一只cat和一只dog,并且给出他们的具体位置。
如果要把问题仔细划分,就会有计算机视觉的各种任务有待解决,下面是CNN能够解决的相关实际问题:
图像分类:图像中是否有猫? (每张图可分类为“有猫”和“无猫”两类)目标识别:图像中是波斯猫还是缅因猫,在哪个位置? (可以用一个矩形框,在图像中圈住猫的大概位置)语义分割:图像中的猫的详细位置? (像素级别区分猫和背景,要求边界清晰明显)
- 除了上述最基础的应用之外,CNN还可以用于解决下面问题:
图像生成、图像超分辨率、图像去噪、视频目标轨迹跟踪等
可以想象,如果计算机掌握了这些能力,会给我们的世界带来很多便利:手机人脸识别解锁,刷脸支付,OCR文本提取,AI抠图修图,无人驾驶(纯视觉的无人驾驶例如小鹏汽车、特斯拉)
基本的设计思路是什么?
上面各类图像问题对人眼而言不算什么难事,如果计算机理解了图像的相关信息,也就可以代替人完成一些视觉上的任务。理解图像中的内容,这在计算机中叫做特征提取,为了让计算机能够像人的视觉来理解图片,人们仿照大脑设计了神经网络结构。CNN正是用于图像特征提取的一种网络结构。
基本思路
- 第一点:利用函数拟合不同任务的一一映射问题。以猫的分类为例,随手拍了一张照片,只有两个结果:有猫,无猫。函数的作用是,给定一个输入,得到唯一输出。我们可以构造一个函数,随手拍的图片作为函数的输入,将结果“有猫”和“无猫”作为函数的输出,这样就将原始问题简化成了求解函数表达式的问题。我们要做的就是找到一个函数实现猫咪分类。
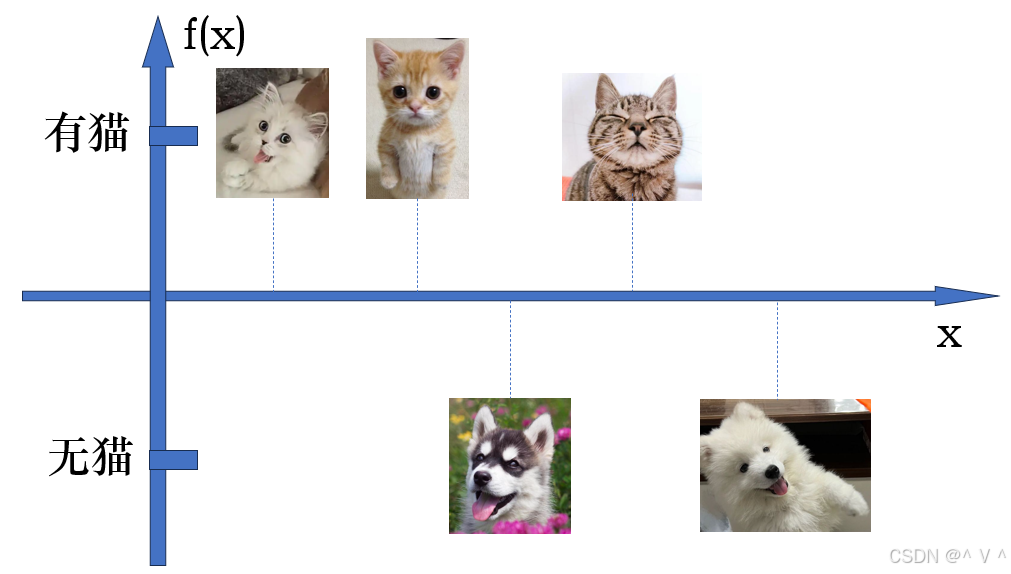
- 第二点:确定函数的输入输出。显然,函数的输入输出应当为数值。
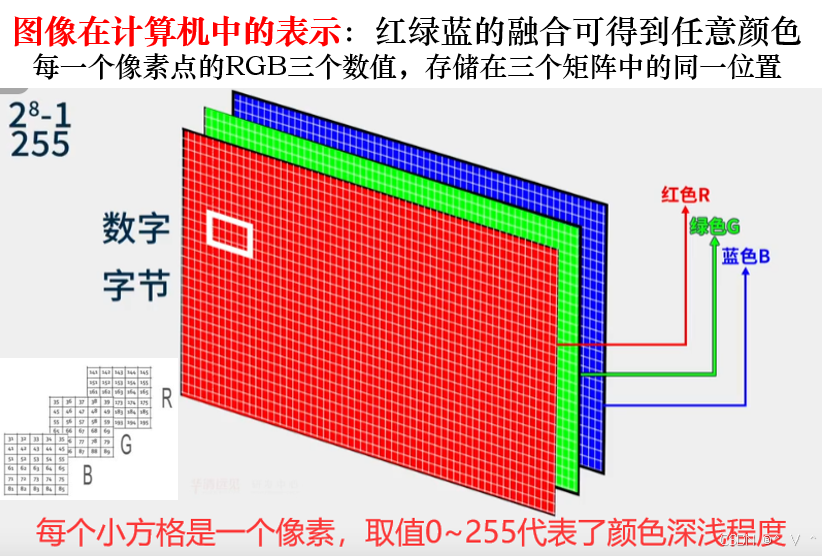
- 第三点:构造一个函数来拟合逼近真实的映射关系,(计算机中的图片数字矩阵)---->(有猫1,无猫-1)。有人可能会问,为什么输入可以是一个矩阵?这个一般使用多元函数就可以解决了,但是在深度学习之中是通过多个非线性函数的线性组合和非线性激活,来实现从RGB矩阵到类别的映射。
- 关键:非线性函数的组合能够拟合任意函数
- 理由:通用逼近定理告诉我们,即使只有一个隐藏层,配合合适的激活函数(如Sigmoid、Tanh、relu等),也能表示任意连续的函数。
- 好处:现实生活中的很多问题可以表述为某种函数关系表达式。
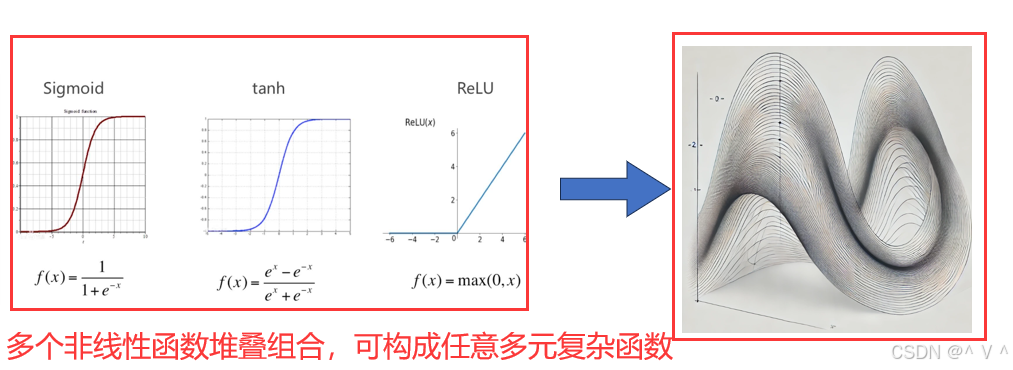
- 第四点:了解到我们可以堆叠非线性函数来逼近任意一一映射关系,那么针对图像
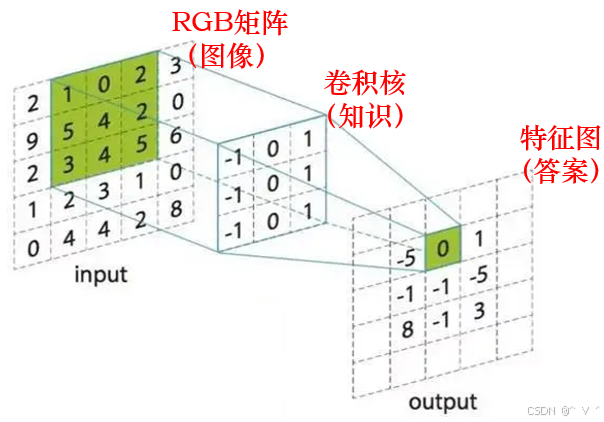
特征提取问题,应该如何构造从RGB矩阵到类别数字的映射呢?- 如下图所示,函数输入input为图像矩阵,经过卷积运算,输出output了图像的特征图。
- 为了学习到图像特征,构造了一个小型的3×3的知识记忆矩阵,叫做
卷积核。关于卷积核的作用,我们只需要知道,一个卷积核记录了目标物体的部分特征,例如猫的耳朵。经过猫耳朵卷积核知识的运算,得到的特征图会无限放大猫的耳朵部分的数值,减小非猫耳朵部分的数值,从而实现特征放大,方便输出层辨认猫耳朵的位置等信息。 - 一个神经网络中可以存在多个卷积核,他们分工合作,记住了猫的整体外貌。如果一张图片中出现猫,你可以理解为特征图中猫所在区域的数值会很大,从而很容易就能通过特征图判断出图片中是否有猫。
2 原理 theory
深度学习CNN的一般基本结构:卷积层(提取特征),激活函数(非线性映射),池化层(下采样),全连接层(适配输出),sigmoid归一化到0~1之间作为最终输出(接近1代表真/正,接近0代表假/负)
-
-
- 卷积层、池化层和全连接层可以是多层堆叠,令N,M,K∈正整数,CNN可简单表述为:
-
-
(卷积层 + 激活函数) × N + 池化层 × M + (全连接层 + 激活函数) × K + s i g m o i d 函数输出 (卷积层+激活函数)× N + 池化层 × M + (全连接层+激活函数)× K+sigmoid函数输出 (卷积层+激活函数)×N+池化层×M+(全连接层+激活函数)×K+sigmoid函数输出
卷积层
- 作用:提取图像特征,相当于记忆猫的特征。卷积核中的参数即为“记忆”,卷积核相当于学习到的“经验知识”。
- 性质:平移不变性(经验知识可以用在任意地方,而不改变其正确性)和局部性(一个卷积核只关注目标的某一部分特征)
- 我们将输出叫做
特征图,是一个数值矩阵;对于输入,可以是原始图像RGB矩阵,其实也可以将特征图作为输入。(后文统一将输入输出的数值矩阵叫做特征图),显然每次的卷积运算相当于对图像某一个区域,使用卷积核(知识)进行了探测,看看这个区域是否有感兴趣的目标。 - 计算方式:超简单的线性组合,下图为[参考文献3]中给出的图解:
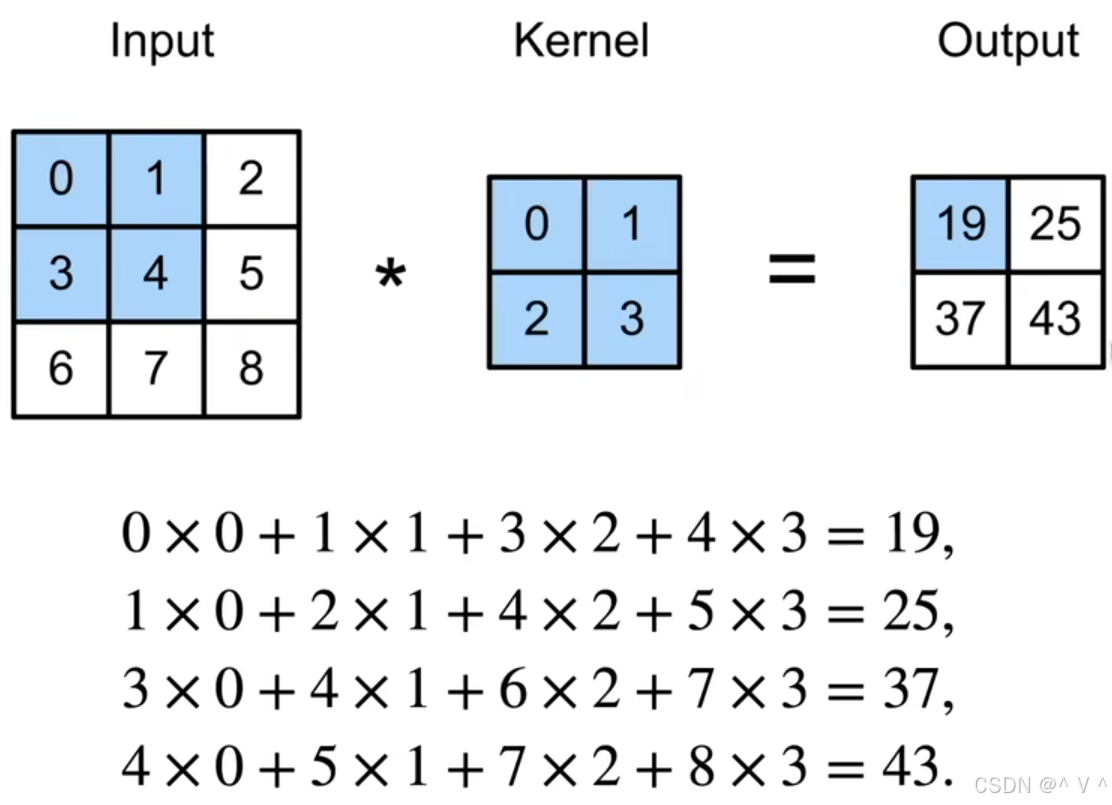
- 其实就是对应位置输入与卷积核元素相乘,然后再相加。不好理解,不妨拆开来看(运算只涉及红框的部分):
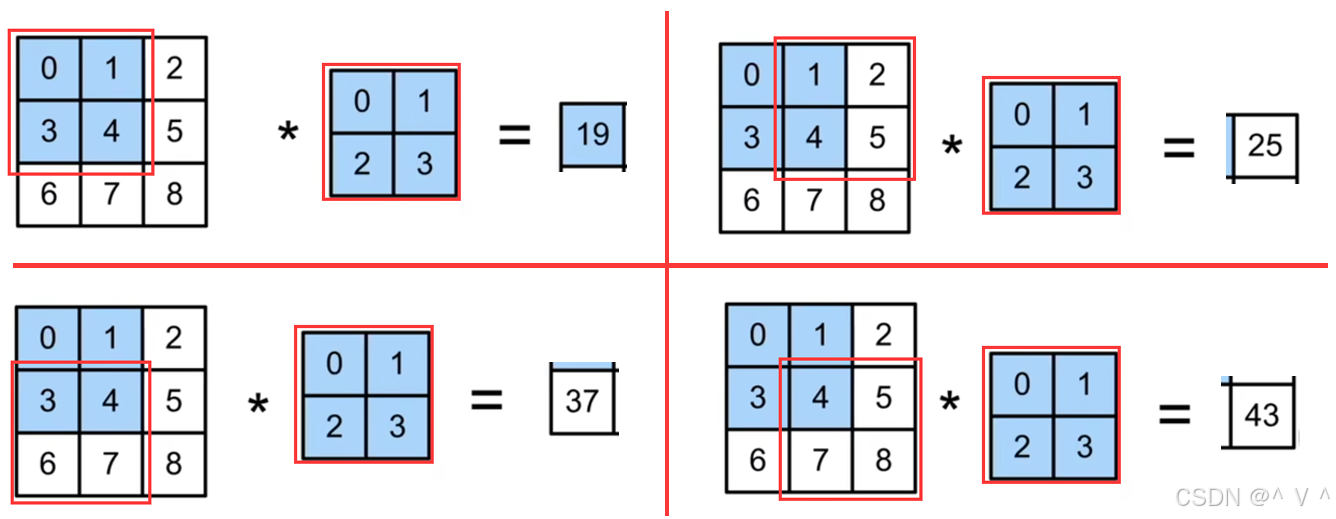
- 显然卷积核运用类似
滑动窗口的方法,对整张图片进行了逐行逐列的遍历,通过线性加权运算,最终得到了结果(特征图)。 - 可以对特征图进一步进行卷积操作,这样就可以扩展卷积网络的深度。
- 容易观察到,一次卷积运算导致输入的 3 ∗ 3 3*3 3∗3 变成了 2 ∗ 2 2*2 2∗2 的大小。
- 为了保证特征图的形状不会随着卷积层的增加而不断减小,引入了
填充,原理很简单:给特征图的边界扩充行和列,保证卷积不改变特征图的宽高,有以下策略:- 以0填充整行整列
- 复制边界填充
- 自定义
- 考虑原始RGB矩阵,显然有三个矩阵作为了输入;当然输入的特征图可以还可以是任意数量。这就引出了
多输入输出通道,下图以二通道为例: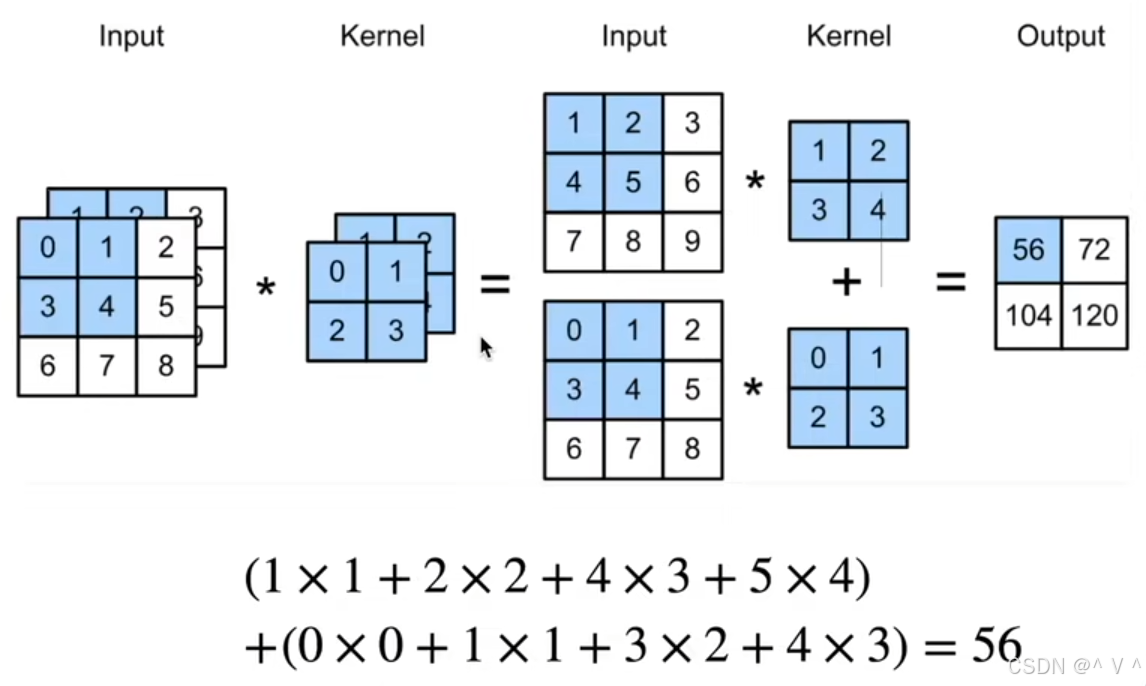
- 有一点需要说明, 1 ∗ 1 1*1 1∗1 的卷积核,相当于全连接层,但是参数量大大降低。
激活函数
- 作用:拟合任意映射关系,用于构建一个接近理想输入输出的函数。
池化层
3 优化 improve
更深
更宽
残差结构
4 进化 evolution
注意力机制
Mamba
附录(本文未完待续…)
本文引用的参考链接如下,所有引用均在本文中段落中标注:
- 【知乎】:图片在计算机中的表示
- 【bilibili】:计算机眼中的图像
- 【bilibili】动手学深度学习(卷积层)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)